Shunted Self-Attention via Multi-Scale Token Aggregation

- 论文:https://arxiv.org/abs/2111.15193
- 代码:https://github.com/OliverRensu/Shunted-Transformer
- 核心内容:本身可以看做是对 PVT 中对 K 和 V 下采样的操作进行多尺度化改进。对 K 和 V 分成两组,使用不同的下采样尺度,构建多尺度的头的 token 来和原始的 Q 对应的头来计算,最终结果拼接后送入输出线性层。
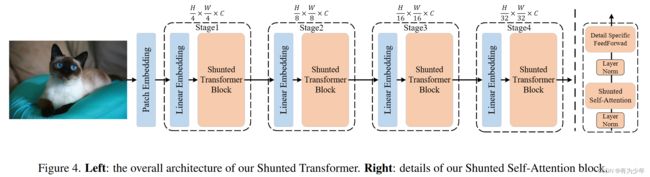
核心改进
| Attention |
FFN |
 |
 |
- Patch Embedding:带重叠的跨步为 2 的 7x7 卷积+3x3 标准卷积+非重叠补偿为 2 的投影层。最终下采样四倍。
- Attention:
- 对 Key 和 Value 使用不同大小的跨步卷积下采样序列,得到具有不同尺度的 K 和 V 的集合。通过将 q 与各个尺度的 K 和 V 进行 Attention 计算,从而捕获多个尺度的信息。
- 得到的 V 上引入额外的深度分离卷积实现局部增强。
- FFN:在两层 FC 中的激活层之前,在原始特征上加上了一个额外的深度分离卷积分支,来补充局部细节信息。
核心代码
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio
if sr_ratio > 1:
self.act = nn.GELU()
if sr_ratio==8:
self.sr1 = nn.Conv2d(dim, dim, kernel_size=8, stride=8)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2d(dim, dim, kernel_size=4, stride=4)
self.norm2 = nn.LayerNorm(dim)
if sr_ratio==4:
self.sr1 = nn.Conv2d(dim, dim, kernel_size=4, stride=4)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2d(dim, dim, kernel_size=2, stride=2)
self.norm2 = nn.LayerNorm(dim)
if sr_ratio==2:
self.sr1 = nn.Conv2d(dim, dim, kernel_size=2, stride=2)
self.norm1 = nn.LayerNorm(dim)
self.sr2 = nn.Conv2d(dim, dim, kernel_size=1, stride=1)
self.norm2 = nn.LayerNorm(dim)
self.kv1 = nn.Linear(dim, dim, bias=qkv_bias)
self.kv2 = nn.Linear(dim, dim, bias=qkv_bias)
self.local_conv1 = nn.Conv2d(dim//2, dim//2, kernel_size=3, padding=1, stride=1, groups=dim//2)
self.local_conv2 = nn.Conv2d(dim//2, dim//2, kernel_size=3, padding=1, stride=1, groups=dim//2)
else:
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.local_conv = nn.Conv2d(dim, dim, kernel_size=3, padding=1, stride=1, groups=dim)
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, nn.Linear):
trunc_normal_(m.weight, std=.02)
if isinstance(m, nn.Linear) and m.bias is not None:
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.LayerNorm):
nn.init.constant_(m.bias, 0)
nn.init.constant_(m.weight, 1.0)
elif isinstance(m, nn.Conv2d):
fan_out = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
fan_out //= m.groups
m.weight.data.normal_(0, math.sqrt(2.0 / fan_out))
if m.bias is not None:
m.bias.data.zero_()
def forward(self, x, H, W):
B, N, C = x.shape
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_1 = self.act(self.norm1(self.sr1(x_).reshape(B, C, -1).permute(0, 2, 1)))
x_2 = self.act(self.norm2(self.sr2(x_).reshape(B, C, -1).permute(0, 2, 1)))
kv1 = self.kv1(x_1).reshape(B, -1, 2, self.num_heads//2, C // self.num_heads).permute(2, 0, 3, 1, 4)
kv2 = self.kv2(x_2).reshape(B, -1, 2, self.num_heads//2, C // self.num_heads).permute(2, 0, 3, 1, 4)
k1, v1 = kv1[0], kv1[1]
k2, v2 = kv2[0], kv2[1]
attn1 = (q[:, :self.num_heads//2] @ k1.transpose(-2, -1)) * self.scale
attn1 = attn1.softmax(dim=-1)
attn1 = self.attn_drop(attn1)
v1 = v1 + self.local_conv1(v1.transpose(1, 2).reshape(B, -1, C//2).
transpose(1, 2).view(B,C//2, H//self.sr_ratio, W//self.sr_ratio)).\
view(B, C//2, -1).view(B, self.num_heads//2, C // self.num_heads, -1).transpose(-1, -2)
x1 = (attn1 @ v1).transpose(1, 2).reshape(B, N, C//2)
attn2 = (q[:, self.num_heads // 2:] @ k2.transpose(-2, -1)) * self.scale
attn2 = attn2.softmax(dim=-1)
attn2 = self.attn_drop(attn2)
v2 = v2 + self.local_conv2(v2.transpose(1, 2).reshape(B, -1, C//2).
transpose(1, 2).view(B, C//2, H*2//self.sr_ratio, W*2//self.sr_ratio)).\
view(B, C//2, -1).view(B, self.num_heads//2, C // self.num_heads, -1).transpose(-1, -2)
x2 = (attn2 @ v2).transpose(1, 2).reshape(B, N, C//2)
x = torch.cat([x1,x2], dim=-1)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C) + self.local_conv(v.transpose(1, 2).reshape(B, N, C).
transpose(1, 2).view(B,C, H, W)).view(B, C, N).transpose(1, 2)
x = self.proj(x)
x = self.proj_drop(x)
return x
实验结果
| 分类 |
检测与实例分割 |
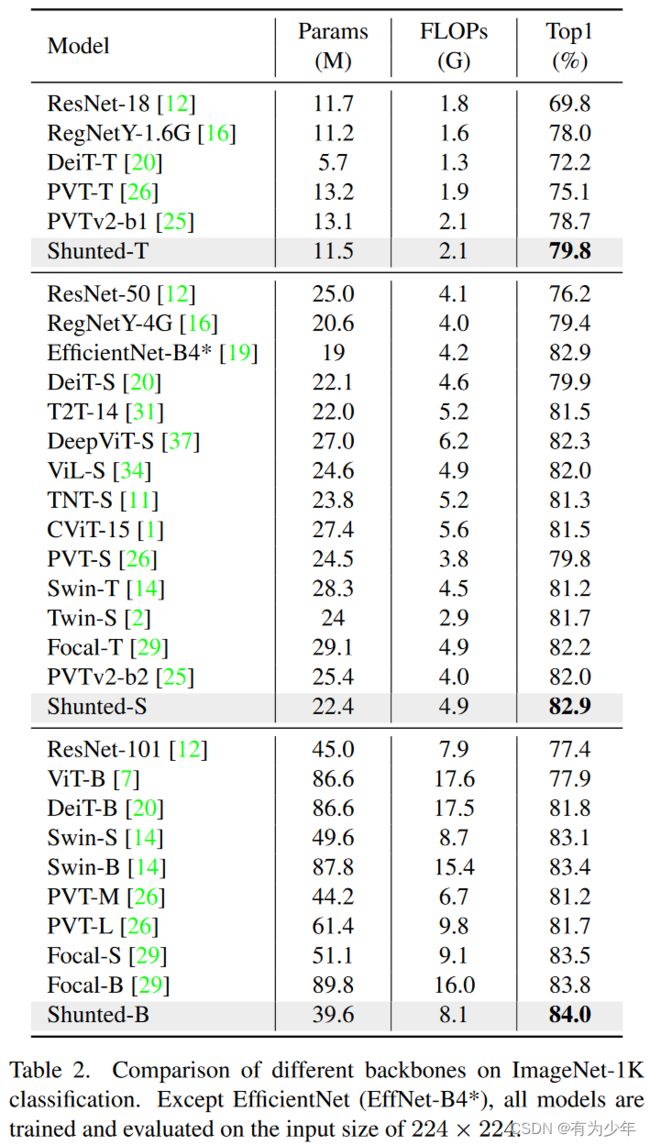 |
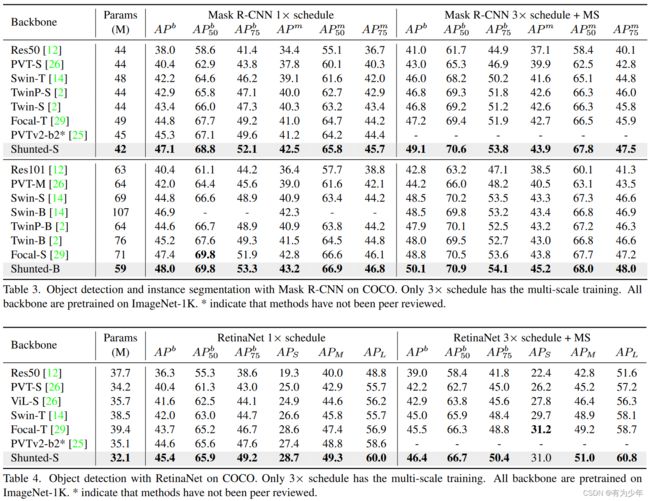 |