matlab启发式算法
启发式算法 (Heuristic Algorithm) 是一种基于直观或经验的局部优化算法.。
启发式算法的定义:
人们常常把从大自然的运行规律或者面向具体问题的经验和规则中启发出来的方法称之为启发式算法. 现在的启发式算法也不是全部来自然的规律, 也有来自人类积累的工作经验。
在可接受的花费 (指计算时间和空间) 下给出待解决组合优化问题每一个实例的一个可行解, 该可行解与最优解的偏离程度不一定事先可以预计。
启发式算法是一种技术, 该技术使得能在可接受的计算费用内去寻找尽可能好的解, 但不一定能保证所得解的可行性和最优性, 甚至在多数情况下, 无法描述所得解与最优解的近似程度。
几种启发式算法
1.禁忌搜索 (Tabu Search): 它是对局部领域搜索的一种扩展,是一种全局逐步寻优算法, 是对人类智力过程的一种模拟。
2.模拟退火 (Simulated Annealing): 它是一种通过模拟物理退火过程搜索最优解的方法。
3.遗传算法 (Genetic Algorithms): 它是一种通过模拟自然进化过程搜索最优解的方法。
4.神经网络 (Neural Networks): 它是一种模仿动物神经网络行为特征, 进行分布式并行信息处理的算法数学模型。
5.蚁群算法 (Ant Algorith): 它是一种模仿蚂蚁在寻找食物过程中发现路径的行为来寻找优化路径的机率型算法。
这里面2、3、4种用到的比较多。这里先学习2和3。
启发式算法在最开始的时候要先给出一个或多个解
退火算法
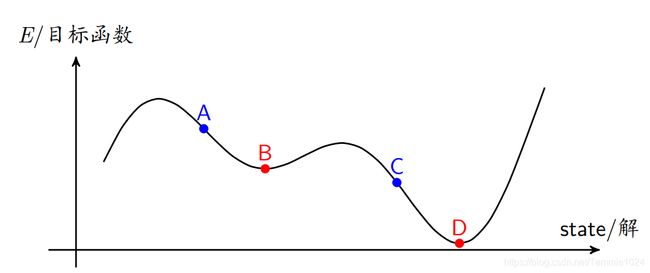
试图寻找最低点。
例如当你给出一个解在A点,它会向左向右移动寻找更低的点(如果是贪心算法,到达B后就会停止),退火算法有能力跳出B点向更低的D点移动,而找到最优解。
两过程的对比
| 模拟退火 | 物理退火 |
|---|---|
| 解 | 粒子状态 |
| 目标函数 | 能量 |
| 最优解 | 能量最低态 |
| 设定初温 | 加温过程 |
| 扰动 | 热涨落 |
| Metropolis 采样过程 | 热平衡, 粒子状态满足波尔兹曼分布 |
| 控制参数的下降 | 冷却 |
基本思想
构造初始解,使当前解等于这个解
设置初始温度
开始模拟退火的主算法
循环(满足温度一定阈值退出)
对于同一温度再循环n次,使温度平衡
在设置的温度附近添加扰动,计算花费
比较两次花费,小于零就接受扰动后的温度,不满足就随机产生一个随机数
平衡后进行降温,进入下次循环
给出解
construct initial solution x0, and xcurrent = x0
set initial temperature T = T0
while continuing criterion do
for i = 1 to TL do
generate randomly a neighbouring solution x′ 2 N(xcurrent)
compute change of cost ∆C = C(x′) − C(xcurrent)
if ∆C ≤ 0 or random(0; 1) < exp(−∆kTC) then
xcurrent = x′ {accept new state}
end if
end for
set new temperature T = decrease(T) {decrease temperature}
end while
return solution corresponding to the minimum cost function
退火算法设计要素
初始解的生成
1.通常是以一个随机解作为初始解. 并保证理论上能够生成解空间中任意的解。
2.也可以是一个经挑选过的较好的解. 这种情况下,初始温度应当设置的较低。
3.初始解不宜 “太好”, 否则很难从这个解的邻域跳出。
临解生成函数
1.邻解生成函数应尽可能保证产生的侯选解能够遍布解空间。
2.邻域应尽可能的小: 能够在少量循环步中允分探测. 但每次的改变不应该引起太大的变化。
初始温度设定
1.初始温度应该设置的尽可能的高, 以确保最终解不受初始解影响. 但过高又会增加计算时间。
2.均匀抽样一组状态,以各状态目标值的方差为初温。
3.如果能确定邻解间目标函数 (COST 函数) 的最大差值, 就可以确定出初始温度 T0, 以使初始接受概率 P = e−j∆Cjmax/T足够大。 j∆Cjmax 可由随机产生一组状态的最大目标值差来替代。
4.在正式开始退火算法前, 可进行一个升温过程确定初始温度:逐渐增加温度, 直到所有的尝试尝试运动都被接受, 将此时的温度设置为初始温度。
5.由经验给出, 或通过尝试找到较好的初始温度。
等温步数确定
1.等温步数也称 Metropolis 抽样稳定准则, 用于决定在各温度下产生候选解的数目. 通常取决于解空间和邻域的大小。
2.等温过程是为了让系统达到平衡, 因此可通过检验目标函数的均值是否稳定 (或连续若干步的目标值变化较小) 来确定等温步数。
3.等温步数受温度的影响. 高温时, 等温步数可以较小, 温度较小时, 等温步数要大. 随着温度的降低, 增加等温步数。
4.有时为了考虑方便, 也可直接按一定的步数抽样。
降温
经典模拟退火算法的降温方式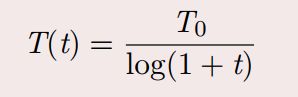
快速模拟退火算法的降温方式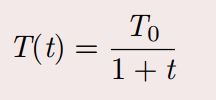
常用的模拟退火算法的降温方式还有 (通常 0:8 ≤ α ≤ 0:99)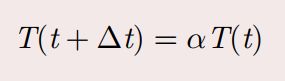
花费函数COST
1.应该能被快速的计算, 花费函数的计算是程序的可能瓶颈。
2.花费函数 COST 一般由目标函数来构造. 目标函数, 或目标函数的倒数/相反数经常直接作为花费函数。
终止条件
1.理论上温度要降为 0 才终止退火算法. 但实际上温度较低时,尝试的接受概率就几乎为 0 了。
2.设置终止温度的阈值, 或设置外循环迭代次数。
3.算法搜索到的最优值连续若干步保持不变。
模拟退火算法的实例
已知中国 34 个省会城市 (包括直辖市) 的经纬度, 要求从北京出
发, 游遍 34 个城市, 最后回到北京. 用模拟退火算法求最短路径。
根据上面几个设计要素:
初始解的生成
随便给以一组顺序就是一组解了。
![]()
临解生成函数
任意互换两个城市的排列位置就可以视为一个小的扰动。![]()
初始温度设定降温

花费函数COST
也就是总长度:![]()
| 用到的代码 | 说明 |
|---|---|
| randperm(n) | 对1到n进行随机排序 |
| length | 返回矩阵或向量的长度 |
| distance | 对球面两点求解距离 |
| distancematrix | 自定义函数,计算距离矩阵 |
| totaldistance | 自定义函数,路径距离计算 |
| perturb | 自定义函数,产生临解的函数 |
主程序代码
route = randperm(numberofcities); %路径格式:[1,2,...,n]
temperature = 1000; cooling_rate = 0.95; %初始化温度
Titerations = 1; %用来控制降温的循环记录内循环步数
previous_distance = totaldistance(route); %计算路径总长
while temperature > 1.0 %循环继续条件
temp_route = perturb(route, 'reverse'); %扰动产生邻解
current_distance = totaldistance(temp_route);%路长
diff = current_distance - previous_distance;
if (diff<0)||(rand < exp(-diff/(temperature)))
route = temp_route; %接受当前解
previous_distance = current_distance;
Titerations = Titerations + 1;
end
if Titerations >= 10 %每10步降温(等温步数为10)
temperature = cooling_rate*temperature;
Titerations = 0;
end
end
自定义函数
distancematrix
function dis = distancematrix(city)
numberofcities = length(city);
R = 6378.137; %地球半径, 用于求两个城市的球面距离
for i = 1:numberofcities
for j = i+1:numberofcities
dis(i,j) = distance(city(i).lat, city(i).long,city(j).lat, city(j).long, R);
dis(j,i) = dis(i,j);
end
end
totaldistance
function d = totaldistance(dis, route)
d = dis(route(end),route(1));
for k = 1:length(route)-1
i = route(k); j = route(k+1);
d = d + dis(i,j);
end
perturb
function route = perturb(route_old,method)
route = route_old;
numbercities = length(route);
city1 = ceil(numbercities*rand); % [1, 2, ..., n-1, n]
city2 = ceil(numbercities*rand); % 1<=city1, city2<=n
switch method
case 'reverse' %[1 2 3 4 5 6] -> [1 5 4 3 2 6]
cmin = min(city1,city2);
cmax = max(city1,city2);
route(cmin:cmax) = route(cmax:-1:cmin);
case 'swap' %[1 2 3 4 5 6] -> [1 5 3 4 2 6]
route([city1, city2]) = route([city2, city1]);
end
没有源代码不建议尝试,上面是整个设计的思路,并不是全部的代码。

遗传算法
种群:解的集合。
染色体:每一个解。
基因:解的一个参数。
基本思想
设置初代k=0
设置变异概率α
设置杂交概率β
设置初始种群,包含n个解(有好有坏)
循环
评价个体适应度(同上面的COST函数作用)
选择适应度高的m个个体加入下一代
杂交,对αm的个体
变异,对βm的个体进行变异
更新代数
循环结束
选择最优个体
set initial generation k = 0
probability of mutation = α
probability of performing crossover = β
construct a population of n randomly-generated individuals Pk;
while not termination do
evaluate: compute fitness(i) for each individuals in Pk
select: select m members of Pk insert into Pk+1.
crossover: produce αm children by crossover and insert into Pk+1
mutate: produce βm children by mutate and insert into Pk+1
update generation: k = k + 1
end while
reture the fittest individual from Plast
编码
主要方便个体间杂交、变异,可以使用二进制、格雷码、实数码、符号编码。
适应度函数
也成为评价函数,作用与cost函数类似。根据目标函数确定的用于区分群体中个体好坏的标准,适应度函数值的大小是对个体优胜略汰的依据。
1.通常适应度函数可以由目标函数直接或间接改造得到. 比如,目标函数, 或目标函数的倒数/相反数经常被直接用作适应度函数.
2.一般情况下适应度是非负的, 并且总是希望适应度越大越好(适应度值与解的优劣成反比例).
3.比较好的适应度函数应: 单值, 连续, 非负, 最大化.
4.适应度函数不应过于复杂, 越简单越好, 以便于计算机的快速计算
选择
轮盘赌,面积越大,应在该区域的概率越大。被选中的概率与适应度成正比。概率=个体适应度/种群适应度。
两两竞争:父代中随机选择两个个体,比较后取优。
排序选择(随机性最小):根据个体适应度大小排序,然后基于序号选择。
交叉
交叉分为:单点交叉、两点交叉和多点交叉。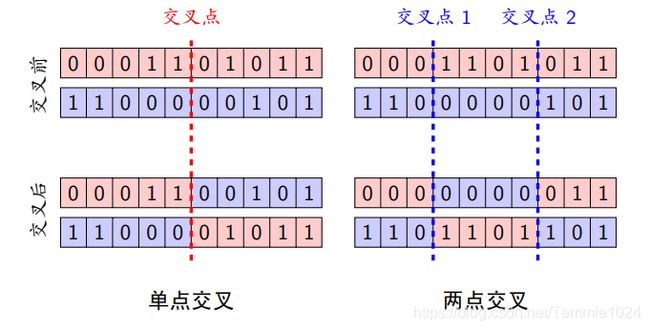
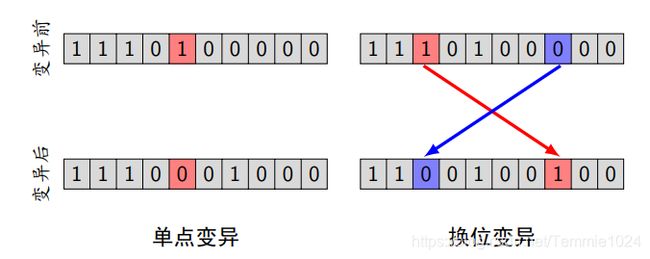
变异
单点变异、换位变异
遗传算法的实例
还是使用退火算法的旅行问题作为例子。
现在考虑下面几个要素:
编码![]()
依旧是一个随机的排列组合。
适应度函数
距离越短越适应,要想适应度值大,就选取距离的倒数即可。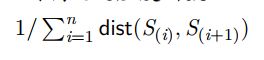
选择运算
两两竞争、轮盘赌
交叉运算
这里的交叉很复杂,因为当交叉互换了一个点后,很可能在单个染色体上就出现了重复的数(重复去了一个城市),所以需要继续互换,将原来的数再与另一个染色体进行对换,直到每条染色体上午重复数值。
变异运算
可以选择对调两点或全部打乱或分块后打乱。
主程序代码
popSize = 100; % 种群规模
max_generation = 1000; % 初始化最大种群代数
Pmutation = 0.16; % 变异概率
for i = 1:popSize % 初始化种群
pop(i,:) = randperm(numberofcities);
end
for generation = 1:max_generation % 主循环开始
fitness = 1/totaldistance(pop,dis);% 计算距离(适应度)
[maxfit, bestID] = max(fitness);
bestPop = pop(bestID, :); % 找出精英
pop = select(pop,fitness,popSize,'competition');% 选择
pop = crossover(pop); % 交叉
pop = mutate(pop,Pmutation); % 变异
pop = [bestPop; pop]; % 精英保护
end % 主循环开始
popDist = total_distance(pop,dis);% 计算距离(适应度)
[minDist, index] = min(popDist); % 找出最短距离
optRoute = pop(index,:); % 找出最短距离对就的路径
自定义函数
select
function popselect = select(pop, fitness, nselect, method)
popSize = size(pop,1);
switch method
case 'roulette' % 轮盘赌
p=fitness/sum(fitness); % 选中概率 [0.2 0.3 0.5]
cump=cumsum(p); % 概率累加 [0.2 0.5 1.0]
% 利用插值: yi = 线性插值(x, y, xi)
I = interp1([0 cump],1:(popSize+1), ...
rand(1,nselected),'linear');
I = floor(I);
case 'competition' % 两两竞争
i1 = ceil( popSize*rand(1,nselect) );
i2 = ceil( popSize*rand(1,nselect) );
I = i1.*( fitness(i1)>=fitness(i2) )+i2.*( fitness(i1)< fitness(i2) );
end
popselect = pop(I);
crossover
function children = crossover(parents)
[popSize, numberofcities] = size(parents);
children = parents; % 初始化子代
for i = 1:2:popSize % 交叉开始
parent1 = parents(i+0,:); child1 = parent1;
parent2 = parents(i+1,:); child2 = parent2;
InsertPoints = ceil(numberofcities*rand(1,2));% 交叉点
for j = min(InsertPoints):max(InsertPoints)
if parent1(j)~=parent2(j) % 如果对应位置不重复
child1(child1==parent2(j)) = child1(j);
child1(j) = child2(j);
child2(child2==parent1(j)) = child2(j);
child2(j) = child1(j);
end
end
children(i+0,:) = child1; children(i+1,:) = child2;
end % 交叉结束
mutate
function children = mutation(parents, probmutation)
[popSize, numberofcities] = size(parents);
children = parents; % 初始化子代
for k=1:popSize % 变异开始
if rand < probmutation % 以一定概率变异
InsertPoints = ceil(numberofcities*rand(1,2));
I = min(InsertPoints); J = max(InsertPoints)l
switch ceil(rand*4) % swap, slide, flip
case 1 % [1 2 3 4 5 6 7] -> [1 5 3 4 2 6 7]
children(k,[I J]) = parents(k,[J I]);
case 2 % [1 2 3 4 5 6 7] -> [1 3 4 5 2 6 7]
children(k,I:J) = parents(k,[I+1:J I]);
otherwise % [1 2 3 4 5 6 7] -> [1 5 4 3 2 6 7]
children(k,I:J) = parents(k,J:-1:I);
end
end
end % 变异结束
