论文阅读“Momentum contrast for unsupervised visual representation learning”(CVPR2020)
论文标题
Momentum contrast for unsupervised visual representation learning
论文作者、链接
作者:He, Kaiming and Fan, Haoqi and Wu, Yuxin and Xie, Saining and Girshick, Ross
链接:CVPR 2020 Open Access Repository
代码:https://github.com/facebookresearch/moco
Introduction逻辑
论文动机&现有工作存在的问题
现有的构建动态字典的无监督学习方法,字典中的keys是从数据中采样的,并由编码器网络提取特征表示。无监督的学习过程是训练编码器去执行一个”字典查找“过程:编码后的“队列”应该与它匹配的key所相似,与其他的相异。
作者假种字典都有以下特征:(1)大型;(2)在训练过程中是一致的。按直觉来说,更大的字典有利于特征采样,并且字典中的key应该用相同或者相似的编码器去表示,这样它们与队列的比较是一致的。
现有的对比学习模型往往有以上的缺点。
本文提出MoCo,可以通过对比损失构建大型且一致的字典。将字典维护为一个数据队列:当前mini-batch中的数据的编码表示被加入队列,而最早的编码表示会被退出队列。队列将字典大小与mini-batch的大小解耦,允许队列大小比较大。此外,由于字典中的key来自前几个mini-batch,本文提出了一种slowly progressing key encoder慢进度的关键字编码器,实现为一个基于动量的移动平均的队列编码器,这个编码器的目的是保持队列的一致性。
本文使用实例区分任务作为pretext tasks:如果编码了同一张图片的不同视图,那么队列应该匹配其中的一个key。
论文核心创新点
(1)带队列的动态字典
(2)平均移动的编码器
相关工作
无监督学习的的两个方面:(1)pretext tasks ;(2)loss function
pretext tasks
The term “pretext” implies that the task being solved is not of genuine interest, but is solved only for the true purpose of learning a good data representation.
代理任务,这种任务并非我们关心的任务,但是完成这种任务往往可以得到很好的特征表示,这些特征表示对下游任务很重要。
loss function
loss fuction 往往独立于pretext tasks。
常用的loss function往往是衡量模型的预测和真实结果的差异。
Contrastive losses 对比损失往往是衡量样本对在特征空间的相似性。
Adversarial losses 对比损失衡量两个概率分布的差异性
论文方法
将对比学习视为字典查询
作者将对比学习视作训练一个针对字典查询任务的编码器。
一个编码队列 和一组编码好的样本
和一组编码好的样本![]() 作为字典的key。假设
作为字典的key。假设![]() 对应字典中的一个单独的key,这个key记作
对应字典中的一个单独的key,这个key记作![]() 。
。

其中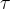 是超参。当
是超参。当![]() 与其对应的正key
与其对应的正key ![]() 相似并且与其他所有的key都不相似的时候,
相似并且与其他所有的key都不相似的时候,![]() 的值就会小。该损失是一个(K+1)路的基于softmax的分类器,目的是将q分类为
的值就会小。该损失是一个(K+1)路的基于softmax的分类器,目的是将q分类为![]() 。
。
将一个查询表示记作![]() ,其中
,其中![]() 是编码网络,
是编码网络,![]() 是一个队列样本,具体取值取决于下游任务。
是一个队列样本,具体取值取决于下游任务。
动量对比
从上述角度来看,对比学习是一种高维连续输入离散字典的构建方法。这个字典是动态的,因为key是随机抽样的,并且key编码器在训练过程中不断演化。
于是,作者假设通过一个大型的含有丰富负样本的字典可以学习到好的特征,与此同时,字典的key编码器在变化的过程中尽可能的保持一致。
字典作为队列
MoCo的核心就是维持字典作为一个含有数据样本的队列。这使得可以重用当前mini-batch中的编码好的key。将字典的大小分解成与mini-batch大小一致。字典的大小可以比mini-batch的大小大得多,并且可以由超参不断调整。
当前的mini-batch入队,最早的mini-batch出队。字典内的内容总是代表着数据集的一个子集。作者之所以让最早的mini-batch出队是因为作者认为老的编码是过时的与新的编码并不一致。
动量更新
使用队列使得字典变大,也使得通过反向传播更新key编码器变得困难。简单的解决方法是直接将队列编码器的参数直接复制给key编码器,但是这样的结果不好。作者猜想效果不好的原因是,编码器快速的变化导致key的表征一致性下降。于是采用动量更新的方法更新key编码器的参数。
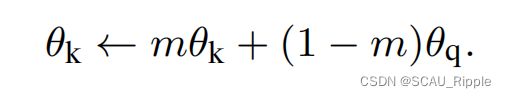
其中,![]() 是key编码器的参数,
是key编码器的参数,![]() 是队列编码器的参数,并且
是队列编码器的参数,并且![]() 是动量系数。只有
是动量系数。只有![]() 是靠反向传播更新的。动量更新使得
是靠反向传播更新的。动量更新使得![]() 可以更平滑的更新参数。并且,队列中的key值是由不同的编码器进行编码的,动量更新可以使得这些key之间的差异尽可能小。作者认为一个缓慢进化的key编码器是利用队列的关键点。
可以更平滑的更新参数。并且,队列中的key值是由不同的编码器进行编码的,动量更新可以使得这些key之间的差异尽可能小。作者认为一个缓慢进化的key编码器是利用队列的关键点。
与其他的模型对比
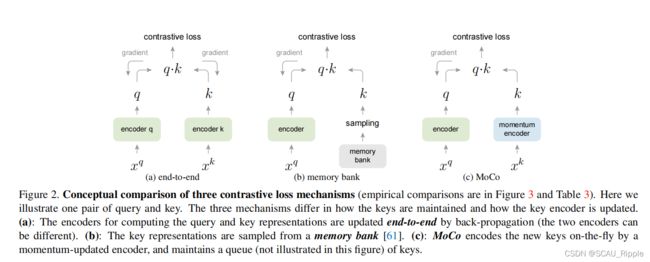
在图2中,MoCo与两个现有的对比学习模型进行比较。
(a)端到端:它使用当前mini-batch中的样本作为字典,因此key是一致编码的(通过相同的编码器)。缺点:字典大小与mini-batch绑定,受限于显卡的显存。
(b)内存银行:内存银行由数据集中所有样本的表示组成。对每一个mini-batch的字典都是随机的从内存银行中选择的,并且不进行反向传播,所以这种方法支持大的字典大小。缺点:内存银行中的样本是在最后一次使用时更新的,所以生成的key本质上是编码器在过去的多个不同步骤下生成的,因此key与key之间不太一致。也有在样本的特征更新时使用动量更新的(本文是对编码器采取动量更新)
(c)MoCo:不对每一个样本进行回溯,对内存消耗更小,同时又可以在大规模数据集上训练(这是内存银行做不到的)
代理任务
对比学习可以驱动各种各样的代理任务。由于本文的研究重点不在设计新的代理任务,于是选择了实例辨别任务。
消融实验设计
跟其他对比学习的模型对比
动量参数消融
主干网络消融
一句话总结
一个对内存友好并且效果好的对比学习模型