MoCo: Momentum Contrast for Unsupervised Visual Representation Learning
目录
- Introduction
- Method
-
- Contrastive Learning as Dictionary Look-up
- Momentum Contrast
- Pretext Task
- Pseudocode of MoCo
- Experiments
-
- Linear Classification Protocol
- Transferring Features
- References
Introduction
Contrastive learning
- 对比学习的目的是让模型学习哪些样本是相似的,哪些样本是不相似的。模型不需要知道样本所属的类别,只需要知道样本之间是否相似就可以了。也就是说,假如现在有三张图片 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3,其中 x 1 , x 2 x_1,x_2 x1,x2 是相似的, x 3 x_3 x3 与 x 1 , x 2 x_1,x_2 x1,x2 是不相似的。三张图片在经过编码器编码后得到三个特征 f 1 , f 2 , f 3 f_1,f_2,f_3 f1,f2,f3,此时模型就需要让 f 1 , f 2 f_1,f_2 f1,f2 尽量接近,而 f 3 f_3 f3 与 f 1 , f 2 f_1,f_2 f1,f2 尽量远离即可
- 但既然没有标签信息,又如何知道样本之间是否相似进而提供监督信号去训练模型呢?在视觉领域,这一般是通过使用 代理任务 (pretext task),从而人为的定义一些规则,用于定义哪些图片是相似的,哪些图片是不相似的来完成的。代理任务多种多样,例如,在 个体判别 (instance discrimination) 中,我们从数据集中随机选取一张图片 x i x_i xi,对该图片做随机裁剪并进行数据增强 (random color jittering, random horizontal flip, and random grayscale conversion) 得到 x i 1 x_i^1 xi1 和 x i 2 x_i^2 xi2。由于它们都是从同一张图片得到的,语义信息应该相近,因此可以将 x i 1 x_i^1 xi1 和 x i 2 x_i^2 xi2 视为相似的正样本,数据集中的所有其他样本都是不相似的负样本,这就相当于将数据集中的每一个样本都看作一个单独的类别
- 在得到正样本和负样本之后,流程就基本固定了,就是利用 对比损失 (contrastive loss) 函数使得相似样本的特征尽量接近,不相似样本的特征尽量远离
Unsupervised visual representation learning
- 在 NLP 领域,无监督的表征学习 (representation learning) 已经非常成功了 (e.g. GPT, BERT),但在 CV 领域,有监督的预训练仍然占据主导地位,无监督学习的进展相对更加滞后。这种现象可能归因于语言和图像不同的信号空间:语言任务拥有离散的信号空间 (words, sub-word units, etc.) 来建立 tokenized dictionaries,无监督学习可以借由这种字典展开 (e.g. 可以把字典中的每个条目都看作一个类别);而在计算机视觉中,由于原始信号是在一个连续的高维空间中,它不像单词一样有很强的语义信息并且带有大量冗余信息,因此并不方便去建立 tokenized dictionaries,无监督学习也很难去建模
- 近来有一些研究使用 对比损失 在无监督视觉表征学习上取得了不错的结果,这些方法都可以被看作是构建动态字典。为什么能看作构建动态字典呢?还以 instance discrimination 为例,我们通过一张图片 x 1 x_1 x1 得到了两个相似的样本 x 1 1 x_1^1 x11 和 x 1 2 x_1^2 x12,其中 x 1 1 x_1^1 x11 称为锚点 (anchor), x 1 2 x_1^2 x12 称为正样本 (positive),数据集中的其余图片 x 2 , . . . , x N x_2,...,x_N x2,...,xN 就称为负样本 (negative). x 1 1 x_1^1 x11 通过编码器 E 11 E_{11} E11 得到特征 f 11 f_{11} f11, x 1 2 , x 2 , . . . , x N x_1^2,x_2,...,x_N x12,x2,...,xN 通过编码器 E 12 E_{12} E12 得到特征 f 12 , f 2 , . . . , f N f_{12},f_2,...,f_N f12,f2,...,fN。我们可以将 f 11 f_{11} f11 看作 query, f 12 , f 2 , . . . , f N f_{12},f_2,...,f_N f12,f2,...,fN 看作 keys,无监督的对比学习就可以看作时训练编码器进行字典查询:query f 11 f_{11} f11 应该尽可能与它匹配的 key f 12 f_{12} f12 接近而与其他 keys f 2 , . . . , f N f_2,...,f_N f2,...,fN 远离,学习过程则是最小化对比损失。而之所以说这个字典是动态的则是因为字典中的 keys 都是随机采样的,并且 key encoder 是随着训练的进行而改变的
large and consistent dictionaries (Motivation)
- 从构建动态字典的角度来看,我们猜想,构建一个大且训练时保持一致的字典是非常重要的。直观上看,大字典有利于更好得从连续高维视觉空间中采样,同时,字典中的 keys 应该由相同或相似的编码器进行表征,这样 query 和不同 keys 进行对比时才能保持一致性
- 然而,现存的使用对比损失的方法大致可以分为两类:end-to-end 和 memory bank,它们均不能同时满足上述两个要求
- (1) end-to-end: 如下图所示,query encoder 和 key encoder 都是实时更新的 (两个编码器参数可以是相同的,也可以是不同的),并都能直接使用梯度下降进行参数更新。由于 key encoder 是不断更新的,为了保证字典一致性,end-to-end 只将当前 mini-batch 作为字典。这样字典大小与 batch size 就是耦合的,受到 GPU 内存大小的限制。受此限制,小内存 GPU 上只能使用小字典,而大内存 GPU 上虽然能使用大字典,但结果也会受到 large mini-batch optimization 的影响
- (2) memory bank: 如下图所示,为了实现大字典,memory bank 方法用 memory bank 去代替 key encoder,memory bank 中存储了数据集中所有样本的特征,每个 mini-batch 所用的字典都从 memory bank 中随机采样得到 (不需要反向传播),这样就能支持大字典了 (由于要存储所有样本的特征,这种方法并不 memory-efficient,在面对亿级数据时十分消耗内存)。然而,memory bank 中的特征只在 mini-batch 采样时进行更新,也就是说,计算出一个 mini-batch 的 q q q 之后才将最新的特征 q q q 更新到 memory bank 中,因此,memory bank 中的特征具有高度的不一致性。为了避免这个问题,memory bank 中的特征在更新时使用了 momentum update (与之相比,MoCo 是在 key encoder 上进行 momentum update)
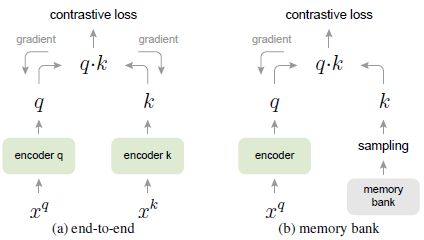
- 为此,我们提出了 Momentum Contrast (MoCo) 作为一种构建大且一致字典的无监督对比学习方法
Method
Contrastive Learning as Dictionary Look-up
- 如上所述,对比学习可以看作是训练一个编码器完成字典查询任务。假设 q q q 为 encoded query, { k 0 , k 1 , . . . } \{k_0,k_1,...\} {k0,k1,...} 为 encoded keys,其中只有一个 key k + k_+ k+ 是与 q q q 匹配的。此时可以将字典查询任务看作是一个多分类任务,要求 q q q 分为 k + k_+ k+ 一类,假设使用内积作为相似度的计量,那么 q ⋅ k i q\cdot k_i q⋅ki 就表示各个类别的 logits,分类任务的交叉熵损失可以写作
L q = − log exp ( q ⋅ k + ) ∑ i = 0 N exp ( q ⋅ k i ) \mathcal{L}_{q}=-\log \frac{\exp \left(q \cdot k_{+} \right)}{\sum_{i=0}^{N} \exp \left(q \cdot k_{i}\right)} Lq=−log∑i=0Nexp(q⋅ki)exp(q⋅k+)其中 N N N 为正负样本数之和 - 但如果采用 instance discrimination, N N N 就为数据集包含的样本数,计算损失的代价太大,因此可以采用一种近似的方法,只取 K K K 个负样本。这样损失函数就变成了 InfoNCE (Noise Contrasitive Estimation),其中的 Estimation 就是指只用 K K K 个负样本进行近似 ( K K K 越大近似也就越准确,这可能也是 MoCo 要求大字典的原因之一):
L q = − log exp ( q ⋅ k + / τ ) ∑ i = 0 K exp ( q ⋅ k i / τ ) \mathcal{L}_{q}=-\log \frac{\exp \left(q \cdot k_{+} / \tau\right)}{\sum_{i=0}^{K} \exp \left(q \cdot k_{i} / \tau\right)} Lq=−log∑i=0Kexp(q⋅ki/τ)exp(q⋅k+/τ)其中 τ \tau τ 为温度系数,用于控制分布形状, τ \tau τ 越小,分布越集中。 τ \tau τ 过大会导致模型对所有负样本一视同仁,学习没有轻重;过小会导致模型只关注特别困难的负样本,但其实某些负样本很可能是潜在的正样本,如果模型过度关注那些特别困难的负样本可能会导致模型难以收敛,学到的特征难以泛化
Momentum Contrast
- Dictionary as a queue: 在前面的分析中,我们知道要想提高对比学习的性能,就必须要维护一个大且一致的字典。MoCo 用一个队列作为字典,每个 mini-batch 采样时,都将当前的 mini-batch 特征入队 (加入字典),最旧的 mini-batch 特征出队 (移出字典),整个队列就是数据集的一个子集,队列的大小即为字典的大小,这样不仅让我们能重用之前 mini-batches 中计算得到的 encoded keys,还使字典大小和 mini-batch size 实现了解耦 (字典大小可以比 mini-batch size 大得多,并且可以作为一个独立的超参进行调节),同时队列 FIFO 的特点也让字典保持了一定的一致性
- Momentum update: 使用队列作为字典可以让字典变得很大,但这也使得我们没法用梯度回传去更新 key encoder 的参数。一个简单的更新 key encoder 参数的方法就是使 key encoder f k f_k fk 的参数 θ k \theta_k θk 与 query encoder f q f_q fq 的参数 θ q \theta_q θq 保持一致,但这会使得每个 mini-batch 之间 key encoder 的参数变化过大,进而带来字典的不一致性。为此,MoCo 对 f k f_k fk 的参数 θ k \theta_k θk 使用了动量更新,使得 θ k \theta_k θk 缓慢变化,缓解字典不一致的问题:
 其中, m ∈ [ 0 , 1 ) m\in[0,1) m∈[0,1) 为动量因子。当 m m m 取值较大时 (e.g. m = 0.999 m=0.999 m=0.999),虽然字典中的 keys 是由不同编码器得到的,但由于这些编码器参数比较接近,字典仍然可以保持一致性,模型效果也比较好
其中, m ∈ [ 0 , 1 ) m\in[0,1) m∈[0,1) 为动量因子。当 m m m 取值较大时 (e.g. m = 0.999 m=0.999 m=0.999),虽然字典中的 keys 是由不同编码器得到的,但由于这些编码器参数比较接近,字典仍然可以保持一致性,模型效果也比较好
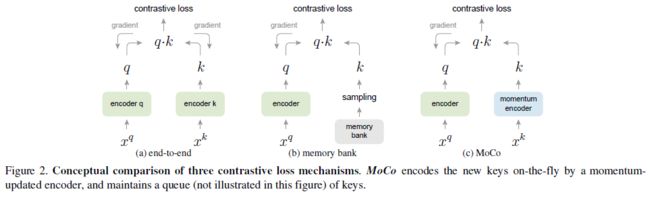
Encoder 可以是任何卷积网络
Pretext Task
- 对比学习可以使用多种多样的代理任务。为了简单起见,MoCo 使用 instance discrimination 作为其代理任务
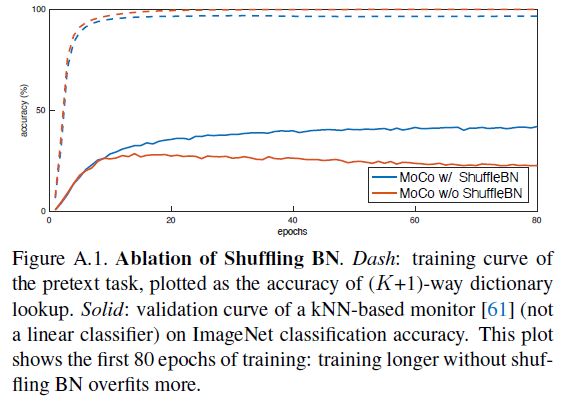
Shuffling BN
- 编码器 f q , f k f_q,f_k fq,fk 采用 ResNet 结构,因此都有 BN 层。在实验中,我们发现使用 BN 会导致模型无法学得好的特征表示,模型似乎可以很容易地找到一个低损失方案来欺骗代理任务,这可能是因为 BN 中样本之间的 intra-batch communication 泄露了信息 (e.g. running mean and var),进而产生退化解
- 为了解决上述问题,MoCo 使用了 Shuffling BN,使用多个 GPU 进行训练并让每个 GPU 单独进行 BN 操作,同时对于 key encoder f k f_k fk,我们在将当前 mini-batch 分配到不同 GPU 上之前先打乱样本顺序 (编码完成之后再将顺序还原),query encoder f q f_q fq 的样本顺序则保持不变。这保证了用于计算 query 和它相应的 positive keys 的 batch statistics 来自两个不同的子集,有效解决了 cheating issue (without shuffling BN, the sub-batch statistics can serve as a “signature” to tell which sub-batch the positive key is in. Shuffling BN can remove this signature and avoid such cheating)
(在之后的实验中,end-to-end 方法也使用了 Shuffling BN;而 memory bank 方法由于 positive keys 来自过去的不同 mini-batches,因此不受上述问题影响)
Pseudocode of MoCo

Experiments
Datasets
- ImageNet-1M (IN-1M): ImageNet-1K 的训练集。由于是无监督学习,这里只关注数据集的样本数,因此将其称为 ImageNet-1M。这个数据集的类别分布是非常均衡的,并且图片只包含一个物体
- Instagram-1B (IG-1B): 这个数据集更接近真实场景,数据分布是不均衡的长尾分布,并且图片中有包含多个物体的场景
Linear Classification Protocol
- 我们在 IN-1M 上做了无监督预训练,然后只将训练得到的模型看作一个特征提取器 (i.e. Linear Classification Protocol),冻住模型参数,额外训练一个有监督的线性分类器接在 ResNet 的全局池化平均层之后,然后测试模型在 ImageNet 验证集上的 1-crop, top-1 准确率。值得一提的是,为了训练这个线性分类器,我们进行了网格搜索,发现最佳的初始学习率为 30,这说明 MoCo 学得的特征分布与有监督学习得到的特征分布完全不同
Ablation: contrastive loss mechanisms

Ablation: momentum
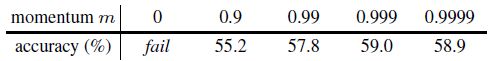
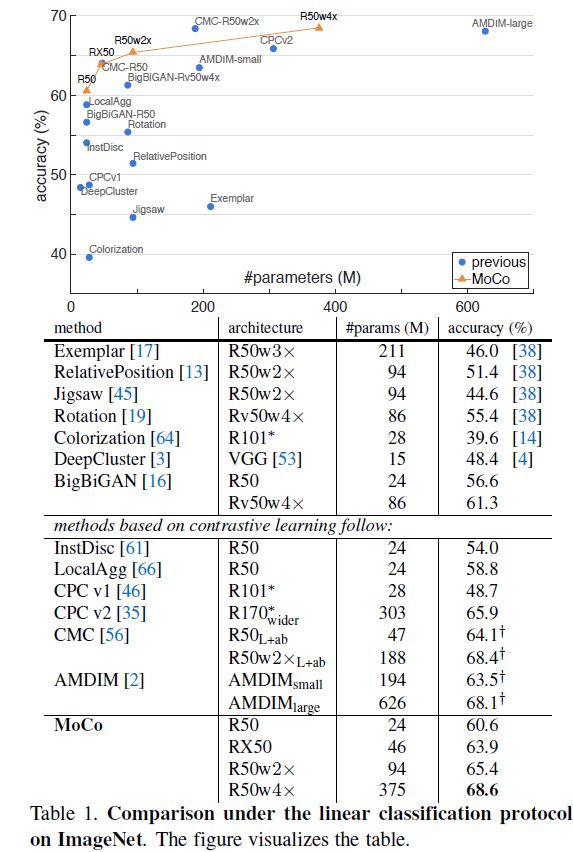
Comparison with previous results
Transferring Features
- 无监督学习最主要的目标就是学习一个可迁移的特征,因此下面将比较 MoCo 和 ImageNet 上的有监督预训练迁移到不同任务上的性能,包括 PASCAL VOC、COCO 等。但在展示结果时,需要先强调两点:
- (1) Normalization: 如前所述,MoCo 学得的特征分布与 ImageNet 上有监督学习学得的特征分布极不相同,使用的超参数也很不相同,需要用 grid search 才能找到一个比较好的超参。因此为了方便下游任务的调参,我们在微调有/无监督预训练模型时使用了特征归一化:微调整个模型并且使用 synchronized BN (把多卡训练时所有 GPU 上的 BN 统计量整合起来在做 BN 层的更新),同时还在新初始化的层里也加上 BN 来帮助调整值域大小。在做完特征归一化之后,就可以统一有/无监督学习的超参了 (这么做对 MoCo 的性能可能是有害的,但 MoCo 在这种设定下依然能取得较好的结果)
- (2) Schedules (学习时长): 当数据集足够大且学习时间足够长时,随机初始化的模型性能就可以接近在 ImageNet 上做有监督预训练的模型。因此,为了更好地比较预训练模型学得特征的可迁移性,实验的训练时长较短 (e.g., 1 × 1× 1× ( ∼ 12 ∼12 ∼12 epochs) or 2 × 2× 2× schedules)
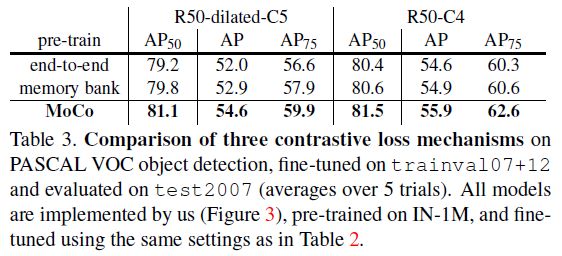
PASCAL VOC Object Detection

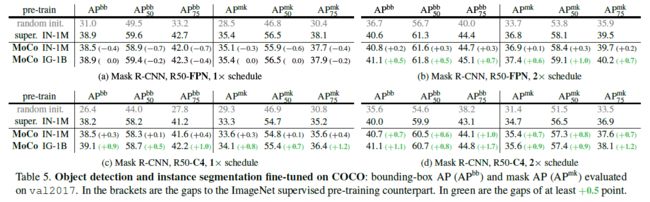
COCO Object Detection and Segmentation
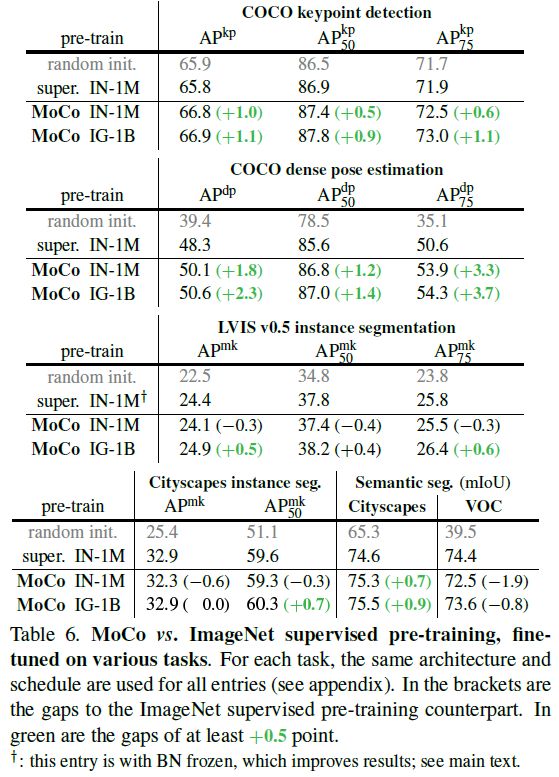
Summary
- 总体而言,MoCo 在 7 个检测或分割任务上性能都超过了 ImageNet 上的有监督预训练模型 (在某几个任务上 MoCo 性能稍差,主要集中在实力分割和语义分割任务上). Overall, MoCo has largely closed the gap between unsupervised and supervised representation learning in multiple vision tasks.
- 值得注意的是,在所有任务中,在 IG-1B 上预训练的 MoCo 性能均优于在 IN-1M 上预训练的 MoCo,这表明 MoCo 也能在大规模真实数据集上做无监督预训练。但 IG-1B 相对于 IN-1M 的提升是比较小的,这说明大规模的数据可能还没有被充分利用,或许一个更高级的代理任务能解决这一问题
- MoCo 是一个通用的使用对比损失的无监督学习框架,可以使用其他的对比损失或代理任务
References
- paper: Momentum Contrast for Unsupervised Visual Representation Learning
- Code: https://github.com/facebookresearch/moco
- MoCo 论文逐段精读【论文精读】