论文阅读 IPOD: Intensive Point-based Object Detector for Point Cloud
IPOD: Intensive Point-based Object Detector for Point Cloud
Abstract
提出了基于原始点云的3D目标检测框架。对于每一个点都设置proposal,我们设计了一个端到端的训练框架,所有proposal中所有点的特征都从骨干网络中提取并且得到一个proposal feature用于最终的边界框推测。
1. Introduction
随着CNN的发展2D图像识别取得了巨大的突破,同时3D场景理解也成为了一个重大课题。我们重点研究基于点云的3D目标检测,预测每个物体的三维边界框和类别标签。
Challenge
点云一方面提供了更多的空间和结构信息,另一方面稀疏无序并且分布不均匀。
为了使用CNN大多数方法都是通过投影或利用固定网格体素化云来将三维点云转换为图像。但是这些方法不具有最优的性能。
Our Contribution
为了解决上述的问题,我们提出了新的基于原始点云的三维目标检测方法,我们将云中的每一个点作为一个element并且给他们设置object proposal。将这些原始点云作为输出保证信息的充分性。
这样一种想法并不是一件简单的事情,在分配相应的ground-truth标签时存在大量冗余和具有歧义的proposal。我们的创新之处在于建立了一个proposal generation模块来根据每一个点输出proposal并且有效的选择符合ground-truth标签的代表性object proposal。因此这样的结构为每一个proposal提取上下文信息和局部信息,然后将这些信息输入到一个微小的PointNet中得到最终的结果。
主要贡献如下:
- We propose a new proposal generation paradigm for point cloud based object detector. It is a natural and general design, which does not need image detection while yielding much higher recall compared with widely used voxel and projection-based methods.
- A network structure with input of raw point cloud is proposed to produce features with both context and local information.
- Experiments on KITTI datasets show that our framework better handles many hard cases with highly occluded and crowded objects, and achieves new stateof-the-art performance.
2. Related Work
3D Semantic Segmentation
几种处理点云语义分割的方法:1.将LIDAR点转换为UV地图,然后通过2D语义分割进行分类。2.基于多视图的函数产生分割掩码。3.从原始LIDAR数据中分割点云,直接在每个点上生成特征同时保留结构信息。
3D Object Detection
主要有三种方法:基于voxel-grid,基于multi-view,基于PointNet
3. Our Framework
我们的方法是从易于得到的基于点的object proposal中回归出3D object bounding box。
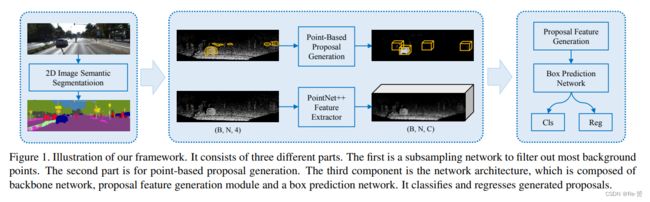
3.1 Point-based Proposal Generation
我们选择一种更为一般的策略,独立的基于每一个点产生object proposal
Challenge
基于点的框架面临许多挑战,例如点的数量非常大,不同proposal之间存在冗余,这些需要大量的计算。
Select Positive Points
第一步是过滤框架中的背景点,我们使用2D语义分割网络对前景像素进行预测,然后使用相机矩阵将前景像素作为掩模投影到点云中。这样一来我们得到了点云中的前景点和背景点。

bounding box内的positive点被聚集在一起。我们在每一个点的中心生成多个scale,angle和shift的proposal

Reducing Proposal Redundancy
去除掉背景点后,大约60k的proposal会剩下,但其中大多数都是冗余的。我们使用非极大值抑制(NMS)的方法来去除冗余。每个proposal的分数是内部点的语义分割数的总和。IOU的值是根据每个proposal到BEV的投影计算得到的。
NMS具体操作为:
- 计算每个proposal的得分,这个得分取该候选框里所有3D预测点的语义分割得分之和。
- 计算PointIoU,两个候选框交集部分的3D点数量与两个候选框并集的3D点数量之比。
Reduction of Ambiguity
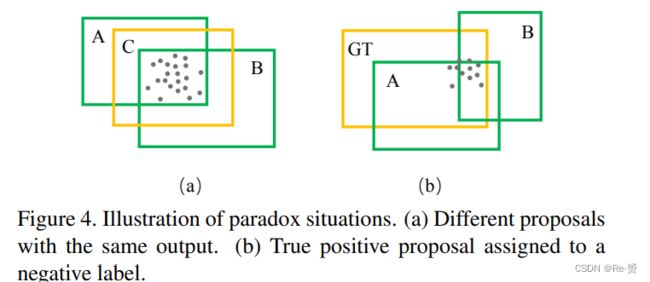
在某些情况下,两个不同的proposal会包含相同的点集,因为这些proposal具有相同的特征表示导致相同的分类或回归预测和不同的bounding box回归结果。为了解决这一个问题,我们将这两个proposal的大小和中心点替换为预定义的class-specific的anchor大小和内部点集合的中心。即将两个3D边界框进行合并。
另一个歧义在于在训练时为proposal分配目标标签。只考虑proposal和ground truth之间的IOU值来分配posititve和negative标签是不合适的,如下图所示A的IOU值更大但是B包含了更多的positive点。因此在我们判断时内部点数更加的重要。我们的解决方案是设计一个PointIOU的标准来分配目标标签,PointIOU定义为两个box相交区域内的点数与两个box区域内点数的商。
3.2 Network Architecture
目标检测要求网络能够为每一个实列生成正确的类标签和精确的定位信息。因此我们的网络需要了解上下文信息。我们的网络将整个点云作为输入,并且为每一个proposal生成特征表示。我们的网络由backbone,proposal feature generation,box prediction network输出。
Backbone Network
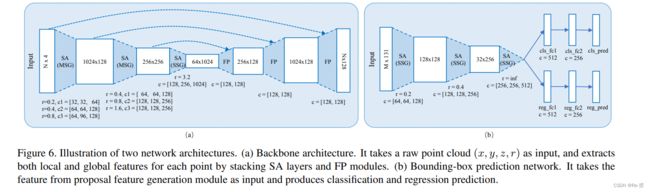
backbone网络是基于PointNet++,每一个点用坐标coordinate和反射率值reflectance进行参数化,即[x,y,z,r]。该网络由多个set abstraction(集合抽象层SA)和feature propagation(特征传播层FP)组成。对于N4个输入点,网络输出大小为NC的特征图。
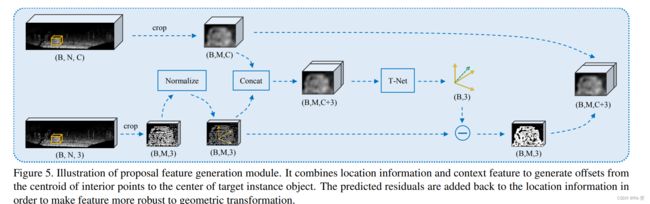
Proposal Feature Generation
每一个proposal的特征具有两个部分,第一个是从提取的特征图中提取出的,具体来说,对于每一个proposal我们随机选择M=512个点,如果候选框中没有512个点,就随机从背景点中选一些补齐到512个点特征,然后取大小为M*C的对应特征向量记为F1。第二个部分是这512个点的归一化坐标。我们使用T-Net来计算proposal中心到真实中心的残差。将F1,F2这两部分联合起来经过一系列变换得到最终的候选框特征。
**Bounding-Box Prediction Network **
对于每一个proposal都用一个小的PointNet++来预测其类别、尺寸比、中心残差和方向。采用3个带有MLP层的SA模块进行特征提取,在其中采用平均池化生成全局特征(原SA采用的是最大池化)。对于尺寸比例,作者直接以(tl,th,tw) 作为参数,对实际尺寸比例和预测框尺寸比例进行回归。因此最终中心预测是通过候选框的中心,T-Net的预测以及bounding-box预测网络预测结果的偏移量得到的。
Loss Functions
我们使用多任务loss来训练网络。
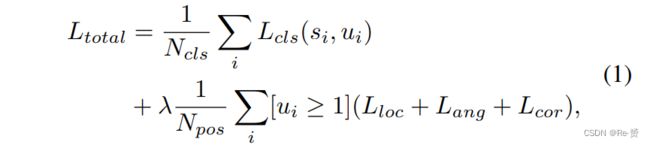


4. Experiments
略过
5. Concluding Remarks
We have proposed a new method operating on raw points. We seed each point with proposals, without loss of precious localization information from point cloud data. Then prediction for each proposal is made on the proposal feature with context information captured by large receptive field and point coordinates that keep accurate shape information. Our experiments have shown that our model outperforms state-of-the-art 3D detection methods in hard set by a large margin, especially for those high occlusion or crowded scenes.