【论文阅读】风格迁移——UGATITU
UGATITU:Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
论文链接: Arxiv
作者及团队:Junho Kim, Minjae Kim, Hyeonwoo Kang, Kwanghee Lee;Clova AI Research, NAVER Corp
论文时间:ICLR 2020
code:Github(Pytorch)
目录
- UGATITU:Unsupervised Generative Attentional Networks with Adaptive Layer-Instance Normalization for Image-to-Image Translation
-
- 总览
- 研究背景
- 问题发现
- 1. Introduction
- 2. Related Work
-
- 注意力机制
- 类激活图(CAM,Class Activation Map)
- BN,IN及LN
- 3. Method
-
- GENERATOR
- D
- 4. Experiments
总览
提出无监督的image-to-image翻译方法,该方法以端到端方式引入了新的注意模块和新的可学习的正则化函数。注意模块根据辅助分类器获得的注意图,引导我们的模型将注意力集中在更重要的区域上,区分源域和目标域。不同于以往基于注意力的方法不能处理域间的几何变化,我们的模型既可以翻译需要整体变化的图像,也可以翻译需要较大形状变化的图像。此外,我们新的AdaLIN(自适应层实例归一化)函数帮助我们的注意力引导模型灵活地控制形状和纹理的变化量,通过数据集学习参数。实验结果表明,与现有的固定网络结构和超参数模型相比,该方法具有优越性。
研究背景
图像到图像的翻译旨在学习一种在两个不同域中映射图像的功能。由于该主题的广泛应用,因此在机器学习和计算机视觉领域受到了研究人员的广泛关注。包括图像修复,超分辨率,灰度图着色,风格迁移,当给出配对样本时,可以使用条件生成模型,以监督方式训练映射模型,在没有配对数据的无监督环境下,需要进行多项工作(Anoosheh等人(2018); Choi等人(2018); Huang等人(2018); Kim等人(2017); Liu等人( 2017); Royer等人(2017); Taigman等人(2017); Yi等人(2017); Zhu等人(2017))已成功使用共享潜在空间翻译了图像(Liu等人(2017) )和周期一致性假设(Kim等人(2017); Zhu等人(2017))。这些工作得到了进一步发展,以处理多模态任务(Huang等人(2018))。
问题发现
尽管取得了这些进步,但先前的方法仍显示出性能差异,具体取决于域之间形状和纹理的变化量。例如,它们对于映射局部纹理(例如photo2vangogh和photo2portrait)的样式转换任务是成功的,但通常对于野外图像中形状变化较大的图像翻译任务(例如,selfie2anime和cat2dog)而言是不成功的。因此,通常需要通过限制数据分布的复杂度来避免图像分割和对齐等预处理步骤(Huang等人(2018); Liu等人(2017))。此外,现有的方法(例如DRIT)(Lee等人(2018))不能通过固定的网络架构获得既保留形状的图像翻译(例如horse2zebra)也无法获得改变形状的图像平移(如cat2dog)的理想结果。网络结构或超参数设置需要针对特定的数据集进行调整。
1. Introduction
提出了一种新的无监督图像到图像的翻译方法,该方法在端到端的方式中加入了一个新的注意模块和一个新的可学习的归一化函数。该模型根据辅助分类器获得的注意图区分源域和目标域,引导翻译聚焦于更重要的区域,忽略较小的区域。这些注意图(attention maps)被嵌入到生成器和鉴别器中,以关注语义上重要的区域,从而促进形状的转换。注意力生成器中的注意图将注意力集中在两个域的特定区分区域上,而鉴别器中的注意图则通过关注目标域内真实图像和假图像之间的差异来进行微调。除了注意机制外,我们还发现,对于形状和纹理变化量不同的数据集,标准化函数的选择对转换结果的质量有显著影响。受批处理实例规范化(BIN)启发,提出自适应层实例归一化(AdaLIN),其参数在训练时通过自适应选择实例归一化(IN)和层归一化(LN)之间的适当比例从数据集学习。
本文贡献:
1、提出一种新的无监督图像到图像翻译方法,引入了新的注意模块和归一化函数,AdaLIN;
2、注意模块根据辅助分类器获得的注意图区分源域和目标域,帮助模型明确在哪里进行集中转换;
3、AdaLIN功能帮助注意力导向模型在不修改模型架构或超参数的情况下灵活控制形状和纹理的变化量。
2. Related Work
注意力机制
计算机视觉(computer vision)中的注意力机制(attention)的基本思想就是想让系统学会注意力——能够忽略无关信息而关注重点信息。近几年来,深度学习与视觉注意力机制结合的研究工作,大多数是集中于使用掩码(mask)来形成注意力机制。掩码的原理在于通过另一层新的权重,将图片数据中关键的特征标识出来,通过学习训练,让深度神经网络学到每一张新图片中需要关注的区域,也就形成了注意力。注意力机制一种是软注意力(soft attention),另一种则是强注意力(hard attention)。
- 软注意力的关键点在于,这种注意力更关注区域或者通道,而且软注意力是确定性的注意力,学习完成后直接可以通过网络生成,最关键的地方是软注意力是可微的,这是一个非常重要的地方。可以微分的注意力就可以通过神经网络算出梯度并且前向传播和后向反馈来学习得到注意力的权重。
- 强注意力与软注意力不同点在于,首先强注意力是更加关注点,也就是图像中的每个点都有可能延伸出注意力,同时强注意力是一个随机的预测过程,更强调动态变化。当然,最关键是强注意力是一个不可微的注意力,训练过程往往是通过增强学习(reinforcement learning)来完成的。
在计算机视觉中,很多领域的相关工作(例如,分类、检测、分割、生成模型、视频处理等)都在使用Soft Attention,这些工作也衍生了很多不同的Soft Attention使用方法。Attention机制的本质就是利用相关特征图学习权重分布,再用学出来的权重施加在原特征图之上最后进行加权求和。 不过施加权重的方式略有差别,大致总结为如下四点:
- 加权可以作用在原图上;
- 加权可以作用在空间尺度上,给不同空间区域加权;
- 加权可以作用在Channel尺度上,给不同通道特征加权;
- 加权可以作用在不同时刻历史特征上,结合循环结构添加权重,例如机器翻译,或者视频相关的工作。
类激活图(CAM,Class Activation Map)
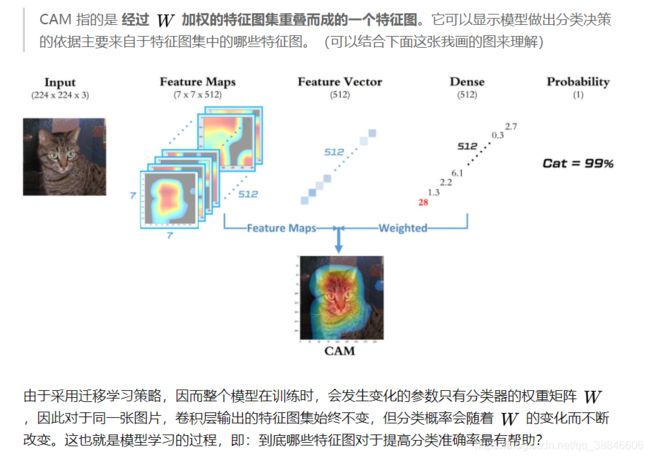
上面截图来自知乎,下面内容搬自CSDN博客。
CAM的网络架构,如下图所示。输入一张图片,然后经过CNN网络提取出许多feature map,每个fearure map都能够表示出整个网络的部分特征。这里的CNN网络可以使用VGG啊,或者google net系列的例如inception等等,但是有这样一个问题,我们认为feature map还保留着图片的空间信息,这也是为什么最后通过feature map的叠加可以得到class activation map的原因。而通常的网络中会选择全连接层进行图片特征图向特征向量的转换在这个转换过程中就会丢失空间信息。
所以文中采用global average pooling(GAP)来代替fully connected。然后将生成的这个值,最后通过一个全连接层实现相应的分类结果,相应的全连接层的权重称为相应的权重w1,w2.。。。。。
我们这样想最后生成的结果分类结果,其实就是pool之后的值与相应权重的乘积,相应的这个pool值是由GAP生成的,所以最后分类的结果可以看为是特征图与权重的乘积,这时候权重就代表了每个特征图对于最后结果的贡献程度,那么假如我们将特征图乘以权重直接相加,那么对于最后结果影响大的地方因该有相对较大的值,小的地方有相对较小的值,这个过程也就是CAM的原理讲解。具体的过程可以看图二的下面部分,了解具体操作。
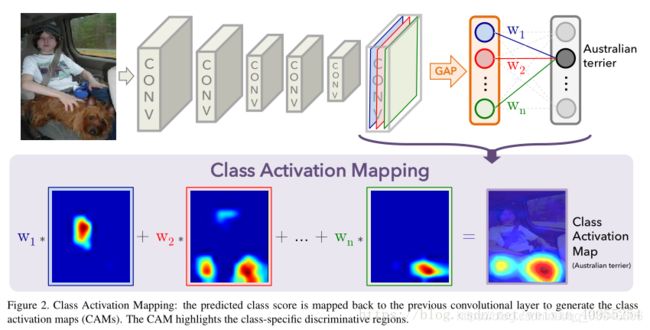
当然这里有几个地方需要说明,首先就是应用之前需要对模型进行预训练,才能够进行CAM接下来的操作。其次过于最后生成特征图的大小对于不同的基模型有不同的方案,比如Alexnet的1313,vgg的1414,Googlenet的14*14.所以对于我们所希望获得的原图,最后是需要进行resize的。
BN,IN及LN
对于图像风格迁移这类的注重每个像素的任务来说,每个样本的每个像素点的信息都是非常重要的,于是像BN这种每个批量的所有样本都做归一化的算法就不太适用了,因为BN计算归一化统计量时考虑了一个批量中所有图片的内容,从而造成了每个样本独特细节的丢失(BN是对同一个batch中所有data的同一个dim进行归一化)。同理对于LN这类需要考虑一个样本所有通道的算法来说可能忽略了不同通道的差异,也不太适用于图像风格迁移这类应用。
所以提出了Instance Normalization(IN),一种更适合对单个像素有更高要求的场景的归一化算法(IST,GAN等)。IN的算法非常简单,计算归一化统计量时考虑单个样本,单个通道的所有元素。IN(右)和BN(中)以及LN(左)的不同从图1中可以非常明显的看出。 N N N表示样本轴, C C C表示通道轴, F F F是每个通道的特征数量。以上来自知乎。
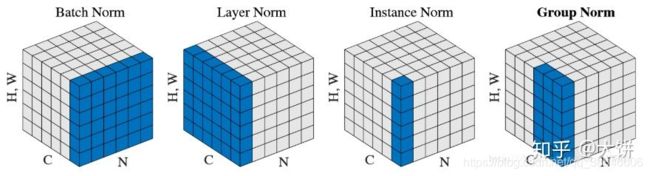
注:四种归一化的不同
BatchNorm: batch方向做归一化,计算 N ∗ H ∗ W N*H*W N∗H∗W的均值
LayerNorm: channel方向做归一化,计算 C ∗ H ∗ W C*H*W C∗H∗W的均值
InstanceNorm: 一个channel内做归一化,计算 H ∗ W H*W H∗W的均值
GroupNorm: 先将channel方向分group,然后每个group内做归一化,计算 ( C / / G ) ∗ H ∗ W (C//G)*H*W (C//G)∗H∗W的均值
GN与LN和IN有关,这两种标准化方法在训练循环(RNN / LSTM)或生成(GAN)模型方面特别成功。
3. Method
将注意力模块集成到生成器和判别器中。判别器中的注意力模块指导生成器关注于生成真实图像的关键区域。生成器中的注意力模块将注意力放在能够区分与其他域不同的区域。这里的注意力机制不是传统的 Attention 或者 Self-Attention 的方式通过计算全图的权重作为关注,而是采用全局和平均池化下的类激活图(Class Activation Map-CAM)来实现的,而AdaLIN的作用是帮助注意力引导模型灵活控制形状和纹理的变化量,从而提升模型的鲁棒性。
GENERATOR
x ∈ { X s , X t } x ∈ \{X_s, X_t\} x∈{Xs,Xt}代表样本来自于源域或目标域,翻译模型 G s → t G_{s \to t} Gs→t由编码器 E s E_s Es,解码器 G t G_t Gt及辅助分类器 η s \eta_s ηs组成, η s ( x ) \eta_s(x) ηs(x)代表 x x x来自 X s X_s Xs的概率。
在 U-GAT-IT 中,除了 GAP 也会使用 Global Maximum Pooling(GMP) 。这样神经网络除了注意 GAP 的整体区域外,也注意到小区域位置地方。GAP 与 GMP 出来结果会做 concatenate ,对应到各个 Encoder Feature Map 相乘。
IN比LN更容易保持原图像的语义信息,但是风格转换不彻底;LN风格转换更彻底,但是语义信息保存不足,因此才有了自适应的ILN层,控制IN和LN的比例;
D
4. Experiments
如图2 (b)所示,注意特征图帮助生成器将注意力集中在与目标区域更有区别的源图像区域,如眼睛和嘴巴。通过可视化鉴别器的局部注意图和全局注意图,我们可以看到鉴别器集中注意力判断目标图像真伪的区域,如图2 ©和(d)所示。图2 (e)所示的注意模块的结果验证了在图像翻译任务中利用注意特征图的优势效果。如果不使用如图2 (f)所示的注意力模块,则可以看到眼睛没有对准,或者在结果中根本没有进行翻译。
参考文献
https://kknews.cc/code/ja6kepl.html
https://bbs.cvmart.net/topics/2298