PyTorch中矩阵(二维张量)的线性代数运算
1 矩阵的形变及特殊矩阵的构造方法
矩阵的形变其实就是二维张量的形变方法,在此基础上本节将补充转置的基本方法。实际线性代数运算过程中,一些特殊矩阵,如单位矩阵、对角矩阵等相关创建方法如下:
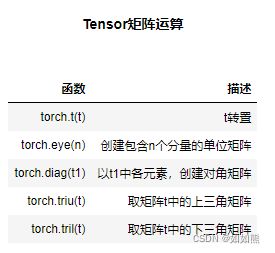
注:t1为一个矩阵,则 torch.t(t1) 与 t1.t()等效。
2 矩阵的基本运算
矩阵不同于普通的二维数组,其具备一定的线性代数含义,而这些特殊的性质,其实就主要体现在矩阵的基本运算上。常见的矩阵基本运算如下:
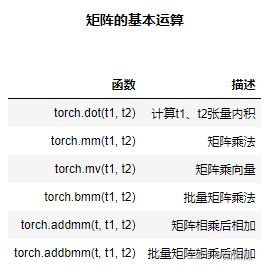
dot\vdot:点积计算。dot和vdot只能作用于一维张量,且对于数值型对象,二者计算结果并没有区别,两种函数只在进行复数运算时会有区别。
mm:矩阵乘法。矩阵乘法其实是一个函数簇,除了矩阵乘法以外,还有批量矩阵乘法、矩阵相乘相加、批量矩阵相乘相加等等函数。
mv:矩阵和向量相乘。PyTorch中提供了一类非常特殊的矩阵和向量相乘的函数,矩阵和向量相乘过程我们可以看成是先将向量转化为列向量然后再相乘,需要矩阵的列数和向量的元素个数相同。mv函数本质上提供了一种二维张量和一维张量相乘的方法,PyTorch中单独设置了一个矩阵和向量相乘的方法,从而简化了行/列向量的理解过程和将向量转化为列向量的转化过程。
bmm:批量矩阵相乘。所谓批量矩阵相乘,指的是三维张量的矩阵乘法。根据此前对张量结构的理解,我们知道,三维张量就是一个包含了多个相同形状的矩阵的集合。而三维张量的矩阵相乘,则是三维张量内部各对应位置的矩阵相乘。由于张量的运算往往涉及二维及以上,因此批量矩阵相乘也有非常多的应用场景。
addmm:矩阵相乘后相加。addmm函数结构:addmm(input,mat1,mat2,beta=1,alpha=1),输出结果:beta*input + alpha*(mat1*mat2)。
addbmm:批量矩阵相乘后相加。和addmm类似,都是先乘后加,并且可以设置权重。不同的是addbmm是批量矩阵相乘,并且,在相加的过程中也是矩阵相加,而非向量加矩阵。
注:addbmm会在原来三维张量基础之上,对其内部矩阵进行求和。
3 矩阵的线性代数运算
矩阵的基本运算是矩阵基本性质,矩阵的线性代数运算,则是我们利用矩阵数据类型在求解实际问题过程中经常涉及到的线性代数方法,具体相关函数如下:
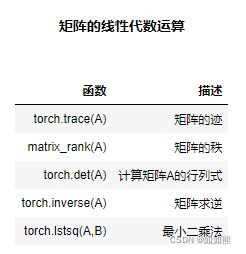
矩阵的迹:就是矩阵对角线元素之和,对于矩阵的迹来说,计算过程不需要是方阵。
矩阵的秩:指矩阵中行或列的极大线性无关数,且矩阵中行、列极大无关数总是相同的,任何矩阵的秩都是唯一值,满秩矩阵有线性唯一解等重要特性,而其他矩阵也能通过求解秩来降维,同时,秩也是奇异值分解等运算中涉及到的重要概念。torch.matrix_rank计算矩阵的秩。
矩阵的行列式:可以简单将其理解为矩阵的一个基本性质或者属性,通过行列式的计算,我们能够知道矩阵是否可逆,从而可以进一步求解矩阵所对应的线性方程。更加专业的解释,行列式作为一个基本数学工具,实际上就是矩阵进行线性变换的伸缩因子。
4 矩阵的分解
矩阵的分解也有很多种类,常见的例如QR分解、LU分解、特征分解、SVD分解等等,虽然大多数情况下,矩阵分解都是在形式上将矩阵拆分成几种特殊矩阵的乘积,但本质上,矩阵的分解都是在形式上将矩阵拆分成几种特殊矩阵的乘积,但本质上,矩阵的分解是去探索矩阵更深层次的一些属性。这里围绕特征分解和SVD分解展开讲解,逆矩阵也可以将其看成是一种矩阵分解的方式,分解之后的等式如:A = A*(A逆)*A
而大多数情况下,矩阵分解都是分解成形如下述形式:A = VUD
1)特征分解
特征分解中,矩阵分解形式为:=Λ−1,其中,Q和−1互为逆矩阵,并且Q的列就是A的特征值所对应的特征向量,而Λ为矩阵A的特征值按照降序排列组成的对角矩阵。
torch.eig函数:特征分解。

输出结果中,eigenvalues表示特征值向量,即A矩阵分解后的Λ矩阵的对角线元素值,并按照由大到小依次排列,eigenvectors表示A矩阵分解后的Q矩阵。特征值可以简单理解为对应列在矩阵中的信息权重,如果该列能够简单线性变换来表示其他列,则说明该列信息权重较大,反之则较小。特征值的大小表示某列向量能多大程度解读矩阵列向量的变异度,即所包含信息量。特征值一般用于表示矩阵对应线性方程组解空间以及数据降维。 在很多情况下,最大的一小部分特征值的和即可以约等于所有特征值的和,而通过矩阵分解的降维就是通过在Q、Λ 中删去那些比较小的特征值及其对应的特征向量,使用一小部分的特征值和特征向量来描述整个矩阵,从而达到降维的效果。当然,特征分解只能作用于方阵,而大多数实际情况下矩阵行列数未必相等,此时要进行类似的操作就需要采用和特征值分解思想类似的奇异值分解(SVD)。
矩阵分解方法到底具有什么样的意义?
所谓的特征值和特征向量,最重要的是理解“特征”这两个字。在图像处理中,有一种方法就是特征值分解。图像其实就是一个像素值组成的矩阵,假设有一个100*100的图像,对这个图像矩阵做特征值分解,其实是在提取这个图像中的特征,这些提取出来的特征是一个个的向量,即对应着特征向量。而这些特征在图像中到底有多重要,这个重要性则通过特征值来表示。 一个特征向量一定对应有一个特征值。矩阵其实就是一个线性变换,向量在经过矩阵A这个线性变换之后,新向量和原来的向量仍然保持在同一直线上,也就是说这个变换只是把向量的长度进行了改变而保持方向不变(在特征值是负数的情况下,新向量的方向是原来方向的反向,即180°反方向)。
所以归根到底,特征向量其实就是矩阵A本身固有的一些特征,本来一个矩阵就是一个线性变换,当把这个矩阵作用于一个向量的时候,通常情况绝大部分向量都会被这个矩阵A换得“面目全非”。但是偏偏刚好存在这么一些向量,被矩阵A变换之后居然还能保持原来的样子,于是这些向量就可以作为矩阵的核心代表了。我们可以说:一个变换(一个矩阵)可以由其特征值和特征向量完全表述,这是因为从数学上看,这个矩阵所有的特征向量组成了这个向量空间的一组基底。而矩阵作为变换的本质其实不就把一个基底下的东西变换到另一个基底表示的空间中么?
详细解释可参考如下博文:
所谓的特征值和特征向量
2)奇异值分解(SVD)
奇异矩阵和非奇异矩阵都是针对方阵而言的,方阵的行列式为0为奇异矩阵;若不为0称矩阵为非奇异矩阵。
奇异值分解是线性代数中一种重要的矩阵分解,奇异值分解则是特征分解在任意矩阵上的推广,它将一个维度为m*n的奇异矩阵A分解成三个部分:![]() ,其中U、V是两个正交矩阵,其中的每一列分别被称为左奇异向量和右奇异向量,他们和∑中对角线上的奇异值相对应,通常情况下我们只需要保留前k个奇异向量和奇异值即可,其中U是m*k矩阵,V是n*k矩阵,∑是k*k方阵,从而达到减少存储空间的效果,即
,其中U、V是两个正交矩阵,其中的每一列分别被称为左奇异向量和右奇异向量,他们和∑中对角线上的奇异值相对应,通常情况下我们只需要保留前k个奇异向量和奇异值即可,其中U是m*k矩阵,V是n*k矩阵,∑是k*k方阵,从而达到减少存储空间的效果,即![]()
torch.svd()为奇异值分解函数。
经过SVD分解,矩阵的信息能够被压缩至更小的空间内进行存储,从而为PCA(主成分分析)、LSI(潜在语义索引)等算法做好了数学工具层面的铺垫。