image caption (四)Transformer
Transformer:《attention is all your need》
Attention机制将任意位置的两个单词的距离转换成1,有效的解决了NLP中棘手的长期依赖问题。
Transformer的结构在NLP领域中已经得到了广泛应用,并且作者已经发布在TensorFlow的tensor2tensor库中
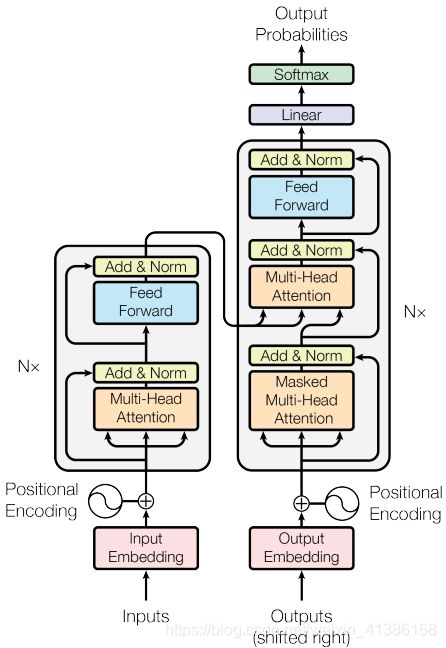
Encoder:(可并行)
1)输入:
单词 Embedding
位置 Embedding(因为 Transformer 不采用 RNN 的结构,而是使用全局信息,不能利用单词的顺序信息)
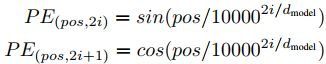
2)结构:
Encoder=6*layer
layer = multi-head self-attention (+residual connection + layer normalisation) {self-attention中取Q,K,V相同}
+ fully connected feed-forward network(+residual connection + layer normalisation)
a. multi-head self-attention mechanism:
X(512维)->Q,K,V(64维)

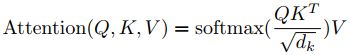
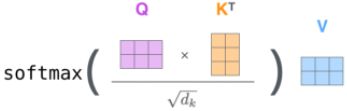
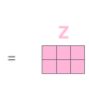
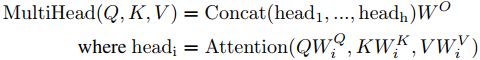
相当于 h 个不同的self-attention的集成

b. fully connected feed-forward network:
![]()
象形变换再各个位置相同,但在各层参数不同。相当于使用了两个内核大小为1的卷积
Dncoder:(时序输出)
Decoder=6*layer
layer = masked multi-head Attention(+residual connection + layer normalisation) {确保预测第i个位置时不会接触到未来的信息}
+ multi-head attention (+residual connection + layer normalisation) {K,V来自encoder,Q来自上一位置decoder的输出}
+ fully connected feed-forward network(+residual connection + layer normalisation)
输出:linear+softmax
代码分析:http://nlp.seas.harvard.edu/2018/04/03/attention.html
代码网络结构:https://www.cnblogs.com/shizhh/p/11189952.html
BERT (Bidirectional Encoder Representations from Transformers)
代码:https://github.com/google-research/bert
BERT通过在海量的语料的基础上运行自监督学习方法为单词学习一个好的特征表示。
在特定的NLP任务中,可以直接使用BERT的特征表示作为该任务的词嵌入特征(作为Word2Vec的转换矩阵)。
所以BERT提供的是一个供其它任务迁移学习的模型,该模型可以根据任务微调(在BERT的基础上再添加一个输出层)或者固定之后作为特征提取器。
自监督任务:MLM和NSP
1)Masked Language Model(MLM)
在训练时随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词。
2)Next Sentence Prediction(NSP)
判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。
Relation Networks for Object Detection
https://github.com/msracver/Relation-Networks-for-Object-Detection
提出模块object relation module 来描述object之间的关系,从而以attention的形式附加到原来的特征上最后进行回归和分类
N个object的两种特征集合:fA 常规的图像特征(appearance feature)(df=1024),fG 位置特征(geometric feature)![]()
the relation feature of the whole object set with respect to the nth object: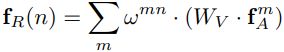 (2) Wv是一个线性变换操作,在代码中用1*1的卷积层实现。
(2) Wv是一个线性变换操作,在代码中用1*1的卷积层实现。
不同object之间的关系权重: (3) 归一化操作在源码中是通过softmax层实现。
(3) 归一化操作在源码中是通过softmax层实现。
object的图像特征权重(appearance weight)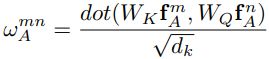 (4) WKfA 与 WQfA 通过全连接层实现 (dk=64)
(4) WKfA 与 WQfA 通过全连接层实现 (dk=64)
object的位置特征权重(geometric weight)![]() (5)
(5)
EG将4维的坐标信息embedding成高维坐标信息(dg=64),主要由一些cos函数和sin函数构成。WG通过全连接层实现;max操作类似relu层,对位置特征权重做一定的限制
4维特征: ![]() 尺度归一化和log操作,具有平移缩放不变性
尺度归一化和log操作,具有平移缩放不变性
![]() (Nr=16) (6)
(Nr=16) (6)

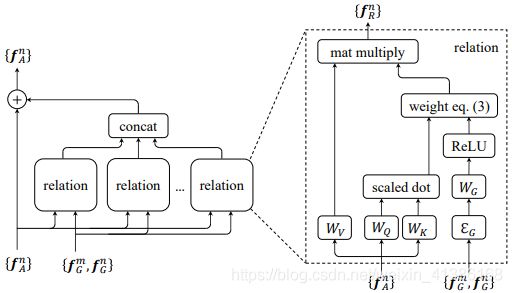
Image Captioning: Transforming Objects into Words
https://github.com/yahoo/object_relation_transformer
输入: image feature vectors
1) input embedding layer: a fully-connected layer (to reduce the dimension from 2048 to dmodel = 512) + a ReLU + a dropout layer.
2) The first encoder layer : the embedded feature vectors are used as input tokens.
The encoder layers 2 to 6: use the output tokens of the previous encoder layer as the input to the current layer
3)Each encoder layer : a multi-head self-attention layer + a small feed-forward neural network.
a.Each self-attention layer : consists of 8 identical heads.
Each attention head:
X : contains all the input vectors x1...xN stacked into a matrix
WQ, WK, WV: learned projection matrices
queries Q, keys K, values V for the N tokens: ![]()
The N × N attention weights for the appearance features: 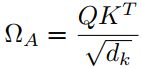 , whose elements
, whose elements ![]() are the attention weights between the m-th and n-th token.
are the attention weights between the m-th and n-th token.
dk = 64: the dimension of the key, query, and value vectors.
The output of the head: ![]()
The output of 8 heads are then concatenated and multiplied with a learned projection matrix ![]()
b.FFN(The point-wise feed-forward network): applied to each output of the attention layer ![]()
c. skip-connections and layer-norm are applied to the outputs of the self-attention and the feed-forward layer
4) modifying the attention weight matrix ![]()
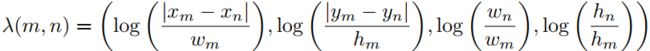
The geometric attention weights: ![]()
new combined attention weights: 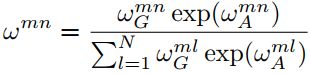
The output of the head: ![]()
Normalized and Geometry-Aware Self-Attention Network for Image Captioning
![]()
![]()
![]()
![]()
![]()
![]()
![]() (N × N)
(N × N)![]()
Normalized SA (NSA) in Encoder
输入分布变化造成的内部协变量偏移(internal covariate shift):对Q进行Instance Normalization (IN) in the 1D
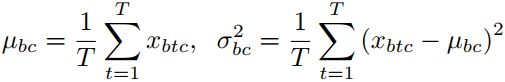
![]()
归一化

# x_shape:[B, C, H, W]
1)batchNorm 在batch上,对NHW做归一化;对小batchsize效果不好;
torch.nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
2)layerNorm 在通道方向上,对CHW归一化,主要对RNN作用明显;
torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True)
3)instanceNorm 在图像像素上,对HW做归一化,用在风格化迁移;
torch.nn.InstanceNorm1d/2d/3d(num_features, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)
Geometry-Aware SA (GSA) in Encoder
几何关系难以表达:将原有的attention weight扩展为两部分:the original content-based weight ;a new geometric bias。
将四维向量![]()
 映射到高维
映射到高维 ![]()
![]()
![]() (N × N)变为
(N × N)变为 ![]()
φ is the geometric attention function :
Content-independent geometric bias : ![]()
***Query-dependent geometric bias : ![]()
Key-dependent geometric bias : ![]()
变体:X-Linear Attention Networks for Image Captioning
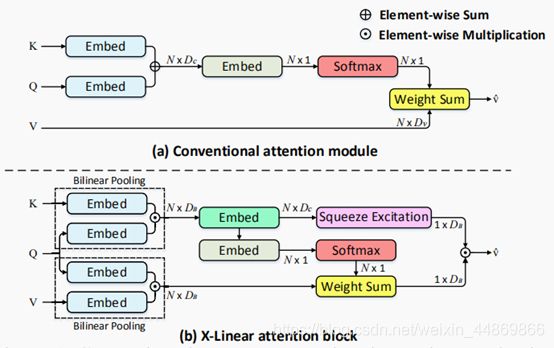
(a)传统的注意机制通过元素线性融合查询(Q)和密钥(K),并计算每个值(V)的空间注意权重,表征了查询和键之间的一阶交互。
(b)X线性注意块充分利用双线性池来捕捉两阶特征之间的相互作用,并测量空间和信道方向的注意分布。采用两个注意权重来积累双线性池在query和value上的增强值。
Meshed-Memory Transformer for Image Captioning