Deep K-SVD Denoising
Deep K-SVD Denoising
文章目录
- Deep K-SVD Denoising
-
- Abstract
- INTRODUCTION
- THE K-SVD DENOISING ALGORITHM
- PROPOSED ARCHITECTURE
-
- A. Patch Denoising
- B. End-to-End Architecture
- C. Extension to Multiple Update
- EXPERIMENTAL RESULTS
-
- A. Training
- B. Denoising Performance
- C. The Network Inner Works
文章代码实现
Abstract
-
The question we address in this paper is whether K-SVD was brought to its peak in its original conception, or whether it can be made competitive again. The approach we take in answering this question is to redesign the algorithm to operate in a supervised manner .
本文讨论的问题是,K-SVD 是在其最初的概念中达到顶峰的,还是能够再次具有竞争力。我们在回答这个问题时采取的方法是重新设计算法,使其在有监督的情况下运行。
-
More specifically, we propose an end-to-end deep architecture with the exact K-SVD computational path, and train it for optimized denoising.
更具体地说,我们提出了一种具有精确 K-SVD 计算路径的端到端深度体系结构,并对其进行优化去噪训练。
-
Our work shows how to overcome difficulties arising in turning the K-SVD scheme into a differentiable, and thus learnable, machine.
我们的工作展示了如何克服在将 K-SVD 格式转化为可微的、因而是可学习的机器时所出现的困难。
INTRODUCTION
-
In this paper we concentrate on one specific regularization approach, as introduced in [11]: the use of sparse and redundant representation modeling of image patches – this is the K-SVD denoising algorithm, which stands at the center of this paper.
在本文中,我们集中讨论 [11] 中介绍的一种特定正则化方法:使用稀疏和冗余的图像块表示建模——这是 K-SVD 去噪算法,它是本文的核心。
-
Their algorithm starts by breaking the image into small fully overlapping patches, solving their MAP estimate (i.e., finding their sparse representation), and ending with a tiling of the results back together by an averaging.
他们的算法首先将图像分割成完全重叠的小块,求解它们的 MAP 估计(即找到它们的稀疏表示),最后通过平均值将结果平铺在一起。
-
As the MAP estimate relies on the availability of the dictionary, this work proposed two approaches, both harnessing the well-known K-SVD dictionary learning algorithm. The first option is to train off-line on an external large corpus of image patches, aiming for a universally good dictionary to serve all test images. The alternative, which was found to be more effective, suggests using the noisy patches themselves in order to learn the dictionary, this way adapting to the denoised image.
由于 MAP 估计依赖于字典的可用性,本研究提出了两种方法,都利用了著名的 K-SVD 字典学习算法。第一种选择是在外部大型图像补丁库上进行离线训练,目的是找到一个通用的好词典来为所有测试图像服务。另一种被发现更有效的方法是,建议使用噪声块本身来学习字典,这样可以适应去噪后的图像。
-
We aim to show that the K-SVD denoising algorithm canbe brought to perform far better by considering a differenttraining strategy.
我们的目的是证明,通过考虑不同的训练策略,K-SVD去噪算法可以获得更好的性能。
-
By following the exact K-SVD computational path, we preserve its global image prior. This includes
(i) breaking the image into small fully overlapping patches,
(ii) solving their MAP estimate as a pursuit that aims to get their sparse representation in a learned dictionary, and then
(ii) averaging the overlapping patches to restore the clean image.
A special care is given to the redesign of all these steps into a differentiable and learnable computational scheme.
通过遵循精确的 K-SVD 计算路径,我们保留了它的全局图像。这包括
(i) 将图像分割成完全重叠的小块,
(ii)将它们的 MAP 估计作为一种目标来解决,目的是在学习过的字典中获得它们的稀疏表示,然后
(ii)平均重叠的小块以恢复干净的图像。
特别注意将所有这些步骤重新设计为可微且可学习的计算方案。
-
Rather, our prime goal in this work is to offer an appealing bridge between classical methods in image processing and the new era of deep neural networks, with the hope to pave the way to followup work that will show the synergy that could exist between the two paradigms.
相反,我们这项工作的主要目标是在图像处理的经典方法和深度神经网络的新时代之间提供一座有吸引力的桥梁,希望为后续工作铺平道路,展示这两种范式之间可能存在的协同作用。
-
More specifically, by rewriting the chain of operations in the K-SVD algorithm in a differentiable manner, we are able to back-propagate through its parameters and obtain an algorithm which performs much better than all its earlier variants.
更具体地说,通过以可微的方式重写 K-SVD 算法中的操作链,我们能够通过其参数进行反向传播,并获得一种比其所有早期变体性能更好的算法。
THE K-SVD DENOISING ALGORITHM
- 参考文献 [Image Denoising Via Sparse and Redundant Representations Over Learned Dictionaries](G:\学习笔记\论文相关\参考文献\Image Denoising Via Sparse and Redundant Representations Over Learned Dictionaries.md)
PROPOSED ARCHITECTURE
-
In this work our goal is to design a network that reproduces the K-SVD denoising algorithm, while having the capacity to better learn its parameters.
在这项工作中,我们的**目标是设计一个能够重现 K-SVD 去噪算法的网络,同时能够更好地学习其参数**。
-
By reposing each of the operations within the K-SVD algorithm in a differentiable manner, we aim to be able to back-propagate through its parameters and obtain a version of the algorithm that outperforms its earlier variants.
通过以可微的方式在K-SVD算法中进行每个操作,我们的目标是能够通过其参数进行反向传播,并获得一个优于其早期变体的算法版本。
-
One of the main difficulties we encounter is the pursuit stage, in which we are supposed to replace the greedy OMP algorithm by an equivalent learnable alternative.
遇到的主要困难之一是追踪阶段,在这个阶段,我们**应该用一个等价的可学习的替代方案来取代贪婪的 OMP 算法**。
-
we can use the L1-based Iterated Soft-Thresholding Algorithm (ISTA), unfolded appropriately for several iterations
我们可以使用基于 L1 的迭代**软阈值算法(ISTA)**,对多次迭代进行适当的展开。
-
The equivalence in the ISTA case requires an identification of the appropriate regularization parameter λ k \lambda_{k} λk for each patch, which is a non-trivial task.
ISTA 情况下的等价性**需要为每个面片识别适当的正则化参数 λ k \lambda_{k} λk**,这是一项非常重要的任务。
A. Patch Denoising
-
We start by describing the three stages that perform the denoising of the individual patches.
我们首先描述了对单个面片进行去噪的三个阶段:
-
Sparse Coding(稀疏编码):
-
Given a patch y ∈ R p × p \mathbf{y} \in R^{\sqrt{p} \times \sqrt{p}} y∈Rp×p (held as a column vector of length p p p) corrupted by an additive zero-mean Gaussian noise with standard deviation σ \sigma σ , we aim to derive its sparse code according to a known dictionary D ∈ R p × m \mathbf{D} \in R^{p \times m} D∈Rp×m.
给定一个补丁 y ∈ R p × p \mathbf{y} \in R^{\sqrt{p} \times \sqrt{p}} y∈Rp×p(作为长度为 p p p 的列向量)被标准偏差为 σ \sigma σ 的加性零均值高斯噪声破坏,根据已知字典 D ∈ R p × m \mathbf{D} \in R^{p \times m} D∈Rp×m 推导出其稀疏编码。
可以使用 ISTA 算法。
-
The motivation to adopt a proximal gradient descent method, as done above, is the fact that it allows an unrolling of the sparse coding stage into a meaningful and learnable scheme
采用近似梯度下降法的动机是,它允许将稀疏编码阶段展开为一个有意义且可学习的方案
-
Moreover the iterative formula is operated on each patch, which means that it is just like a convolution in terms of operating on the whole image.
此外,迭代公式对每个面片进行运算,这意味着就对整个图像的运算而言,它就像一个卷积。
-
Because of these reasons, in this work we consider a learnable version of ISTA by keeping exactly the same recursion with a fixed number of iterations T T T , and letting c c c and D \mathbf{D} D become the learnable parameters.
由于这些原因,在这项工作中,我们考虑了一个可学习的 ISTA 版本,通过保持相同的迭代次数,使 c c c 和 D \mathbf{D} D 成为可学习的参数。
-
-
λ \lambda λ Evaluation( λ \lambda λ 评估):
-
This regularization coefficient depends not only on σ σ σ but also on the patch y \mathbf{y} y itself. Following the computational path of the K-SVD denoising algorithm in [11], we should set λ k λ_k λk for each patch y k \mathbf{y}_k yk so as to yield sparse representation with a controlled level of error, ∥ D α ^ k − y k ∥ 2 2 ≤ p σ 2 \| \mathbf{D}\hat{\alpha}_k - \mathbf{y}_k \|_2^2 \leq p\sigma^2 ∥Dα^k−yk∥22≤pσ2.
该正则化系数不仅取决于 σ σ σ,还取决于面片 y \mathbf{y} y 本身。按照[11]中 K-SVD 去噪算法的计算路径,我们应该为每个面片 y k \mathbf{y}_k yk 设置 λ k λ_k λk,以便产生具有受控误差水平的稀疏表示: ∥ D α ^ k − y k ∥ 2 2 ≤ p σ 2 \| \mathbf{D}\hat{\alpha}_k - \mathbf{y}_k \|_2^2 \leq p\sigma^2 ∥Dα^k−yk∥22≤pσ2。
-
As there is no closed-form solution to this evaluation of λ-s, we propose to learn a regression function from the patches y k \mathbf{y}_k yk to their corresponding regularization parameters λ k λ_k λk.
由于 λ-s 的计算没有封闭形式的解,我们建议从图像块 y k \mathbf{y}_k yk 学习一个回归函数到其相应的正则化参数 λ k λ_k λk。
-
A Multi-Layer Perceptron (MLP) network is used to represent this function, λ = f θ ( y ) λ = f_θ (y) λ=fθ(y), w h e r e θ θ θ is the vector of the parameters of the MLP
用多层感知器(MLP)网络表示该功能, λ = f θ ( y ) λ = f_θ (y) λ=fθ(y),其中 θ θ θ 是 MLP 参数的向量。
-
Our MLP consists of three hidden layers, each composed of a fully connected linear mapping followed by a ReLU (apart from the last layer). The input layer has p nodes, which is the dimension of the vectorized patch, and the output layer consists of a single node, being the regularization parameter.
我们的 MLP 由三个隐藏层组成,每个隐藏层由一个完全连接的线性映射和一个 ReLU 组成(除了最后一层)。输入层有 p 个节点,这是矢量化面片的维数,输出层由单个节点组成,作为正则化参数。
-
The overall structure of the network is given by the following expression, in which [a × b] symbolizes a multiplication by a matrix of that size: MLP: y \mathbf{y} y → [p × 2p] → ReLU → [2p × p] → ReLU → [p/2 × 1] → λ λ λ.
网络的整体结构由以下表达式给出,其中 [a×b] 表示乘以该大小的矩阵: y \mathbf{y} y → [p × 2p] → ReLU → [2p × p] → ReLU → [p/2 × 1] → λ λ λ.
-
-
Patch Reconstruction(图像块重建):
-
This stage reconstructs the cleaned version x ^ \hat{\mathbf{x}} x^ of the patch y \mathbf{y} y using D \mathbf{D} D and the sparse code α ^ \mathbf{\hat{\alpha}} α^ This is given by x ^ = D α ^ \hat{\mathbf{x}}=\mathbf{D}\hat{\mathbf{\alpha}} x^=Dα^.
此阶段使用 D \mathbf{D} D 和稀疏代码 α ^ \mathbf{\hat{\alpha}} α^ 重建 y \mathbf{y} y 的去噪版本 x ^ \hat{\mathbf{x}} x^。这由 x ^ = D α ^ \hat{\mathbf{x}}=\mathbf{D}\hat{\mathbf{\alpha}} x^=Dα^ 给出。
-
Note that in our learned network, the dictionary stands for a set of parameters that are shared in all locations where we multiply by either D \mathbf{D} D or D T \mathbf{D}^T DT .
请注意,在我们学习的网络中,字典代表一组参数,这些参数在我们乘以 D \mathbf{D} D 或 D T \mathbf{D}^T DT 的所有位置共享。
-
B. End-to-End Architecture
-
We start by breaking the input image into fully overlapping patches, then treat each corrupted patch via the above-described patch denoising stage, and conclude by rebuilding the image by averaging the cleaned version of these patches.
我们首先将输入图像分解为完全重叠的面片,然后通过上述图像块去噪阶段处理每个损坏的面片,最后通过平均这些图像块的清洁版本来重建图像。
-
In the last stage we slightly deviate from the original K-SVD, by allowing a learned weighted combination of the patches. Denoting by ω ∈ R p × p \mathbf{\omega} \in R^{\sqrt{p} \times \sqrt{p}} ω∈Rp×p this patch of weights, the reconstructed image is obtained by
在最后一个阶段,我们稍微偏离了原始的 K-SVD,允许对补丁进行学习加权组合。通过 w ∈ R p × p \mathbf{w} \in R^{\sqrt{p} \times \sqrt{p}} w∈Rp×p 表示该权重块,通过以下方法获得重建图像:
X ^ = ∑ k R k T ( w ⊙ x ^ k ) ∑ k R k T w \hat{\mathbf{X}}=\frac{\sum_{k} \mathbf{R}_{k}^{T}\left(\mathbf{w} \odot \hat{\mathbf{x}}_{k}\right)}{\sum_{k} \mathbf{R}_{k}^{T} \mathbf{w}} X^=∑kRkTw∑kRkT(w⊙x^k)
where ⊙ \odot ⊙ is the Schur product(其中 ⊙ \odot ⊙ 是 Schur 积,对应元素相乘),and the division is done element-wise.(这种划分是按元素进行的。) -
To conclude, the proposed network F F F is a parametrized function of θ θ θ (the parameters of the MLP network computing λ λ λ), c c c (the step-size in the ISTA algorithm), D \mathbf{D} D (the dictionary) and w w w (the weights for the patch-averaging).
总之,建议的网络 F F F 是 θ θ θ(MLP 网络计算 λ λ λ 的参数)、 c c c( ISTA 算法中的步长)、 D \mathbf{D} D(字典)和 w w w(面片平均的权重)的参数化函数。
-
The overall number of parameters stands on p ( 4 p + m + 3 / 2 ) + 1 p(4 p + m + 3/2) + 1 p(4p+m+3/2)+1(参数总数是 p ( 4 p + m + 3 / 2 ) + 1 p(4 p + m + 3/2) + 1 p(4p+m+3/2)+1))
-
Given a corrupted image Y \mathbf{Y} Y, the computation X ^ = F ( Y ) \hat{X}=F(\mathbf{Y}) X^=F(Y) returns a cleaned version of it.
给定损坏的图像 Y \mathbf{Y} Y,计算 X ^ = F ( Y ) \hat{X}=F(\mathbf{Y}) X^=F(Y) 将返回该图像的清理版本。
-
Training F F F is done by minimizing the loss function L = ∑ i ∥ X i − F ( Y i ) ∥ 2 2 L=\sum_i\|\mathbf{X}_i-F(\mathbf{Y}_i)\|_2^2 L=∑i∥Xi−F(Yi)∥22, with respect to all the above parameters.
训练 F F F 是通过最小化损失函数 L = ∑ i ∥ X i − F ( Y i ) ∥ 2 2 L=\sum_i\|\mathbf{X}_i-F(\mathbf{Y}_i)\|_2^2 L=∑i∥Xi−F(Yi)∥22,关于上述所有参数。
In the above objective, the set { X i } i \{\mathbf{X}_i\}_i {Xi}i stands for our training images, and { Y i } i \{\mathbf{Y}_i\}_i {Yi}i are their synthetically noisy versions, obtained by Y i = X i + V i \mathbf{Y}_i=\mathbf{X}_i+\mathbf{V}_i Yi=Xi+Vi, where V i \mathbf{V}_i Vi is a zero mean and white Gaussian iid noise vector.
C. Extension to Multiple Update
-
This diffusion process of repeated denoisings has been shown in [37] to improve the K-SVD denoising performance.
这种重复去噪的扩散过程如 [37] 所示,以提高 K-SVD 去噪性能。
-
However, the difficulty is in setting the noise level to target in each patch after the first denoising, as it is no longer p σ 2 pσ^2 pσ2.
然而,困难在于在第一次去噪后将每个面片中的噪声级设置为目标,因为它不再是 p σ 2 pσ^2 pσ2。
-
In our case, we adopt a crude version of the EPLL scheme, in which we disregard the noise level problem altogether, and simply assume that the λ λ λ evaluation stage takes care of this challenge, adjusting the MLP in each round to best predict the λ λ λ values to be used.
在我们的例子中,我们采用了 EPLL 方案的一个粗略版本,在该方案中,我们完全忽略了噪声级问题,并且简单地假设 λ λ λ 评估阶段处理了这个挑战,在每一轮中调整 MLP,以最佳地预测要使用的 λ λ λ 值。
-
Thus, our iterated scheme is trained end-to-end, and shares the dictionary across all denoising stages, while allowing a different λ λ λ evaluation network for each stage.
因此,我们的迭代方案是端到端训练的,并在所有去噪阶段共享字典,同时允许每个阶段使用不同的 λ λ λ 评估网络。
EXPERIMENTAL RESULTS
A. Training
-
Dataset(数据集)
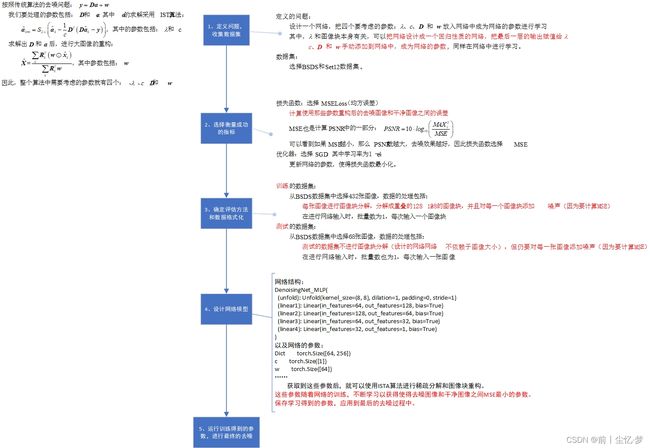
In order to train our model we generate the training data using the Berkeley segmentation dataset (BSDS) [28], which consists of 500 images.
为了训练我们的模型,我们使用伯克利分割数据集(BSDS)[28]生成训练数据,该数据集由 500 幅图像组成。
We split these images into a training set of 432 images and the validation/test set that consists of the remaining 68 images.
我们将这些图像分为 432 张图像的训练集和剩下 68 张图像的验证/测试集。
we test our proposed method on the benchmark Set12 – a collection of widely-used testing images.
我们在基准 **Set12(一组广泛使用的测试图像)**上测试我们提出的方法。
-
Training Settings(训练设置)
During training we randomly sample cropped images of size 128 × 128 128 \times 128 128×128 from the training set.
在训练期间,我们从训练集中随机抽取大小为 128 × 128 128 \times 128 128×128 的裁剪图像。
We add i.i.d. Gaussian noise with zero mean and a specified level of noise σ σ σ to each cropped image as the noisy input during training.
在训练过程中,我们将平均值为零的 i.i.d. 高斯噪声和指定水平的噪声 σ σ σ 添加到每个裁剪图像中,作为噪声输入。
We use SGD optimizer to minimize the loss function.
我们使用 SGD 优化器来最小化损失函数。
We set the learning rate as 1 e − 4 1e − 4 1e−4 and consider one cropped image as the minibatch size during training.
我们将学习率设置为 1 e − 4 1e− 4 1e−4,在训练期间考虑一个裁剪图像作为小批量大小。
We use the same initialization as in the K-SVD algorithm to initialize the dictionary D \mathbf{D} D, i.e the overcomplete DCT matrix.
我们使用与 K-SVD 算法相同的初始化来初始化字典 D \mathbf{D} D,即过完备DCT矩阵。
We also initialize the normalization paramater c c c of the sparse coding stage using the squared spectral norm of the DCT matrix.
我们还使用 DCT 矩阵的平方谱范数初始化稀疏编码阶段的归一化参数 c c c。
-
Test Setting(测试设置)
Our network does not depend on the input size of the image.
我们的网络不依赖于图像的输入大小。
Thus, in order to test our architecture’s performance, we simply add white Gaussian noise with a specified power to the original image, and feed it to the learned scheme.
因此,为了测试我们的架构的性能,我们只需向原始图像中添加具有指定功率的高斯白噪声,并将其输入学习的方案。
The metric used to determine the quality is the standard Peak-Signal-to-Noise (PSNR).
用于确定质量的指标是标准峰值信噪比(PSNR)。
B. Denoising Performance
C. The Network Inner Works
-
We turn to have a closer look at the parameters learned by our proposed network and the data flowing in it.
接下来,我们将更仔细地了解我们提出的网络所学习到的参数以及其中的数据流。
-
We do so by comparing the dictionary and the sparse codes
我们通过比较字典和得到的稀疏码来实现这一点
the distribution of the cardinalities of the sparse codes(稀疏码的基数分布 )