基于服务器部署的OCR在线识别应用
一、前言
前段时间,接了一个OCR在线识别的外包程序,在实现过程中遇到了很多麻烦,也走过很多弯路。在网络查阅了许多相关资料后,发现关于这一块知识详细而完整的文章不多,故写下此文,既是对前段时间的总结,也为今后有同样困扰的朋友提供一些帮助。
几经比较,本文最终决定使用百度的开源OCR框架作为基础,实现服务器部署以及端口调用。PaddleOCR是百度开源的OCR识别框架,采用Paddlehub可快速一键部署。PaddleOCR 的 github 地址:https://github.com/PaddlePaddle/PaddleOCR
二、准备
1、自备服务器,如果没有服务器使用ubuntu作为模拟服务器也行,本文使用的是阿里云服务器
2、在服务器内安装Python环境,建议直接安装Anaconda,可以省去很多时间
3、安装百度的PaddlePaddle,这是个所有百度框架的老大哥,只要你想使用百度的框架产品,这个是必备的
4、安装百度的PaddleHub,这是PaddlePaddle的头号小老弟,安装这个后才能一键部署PaddleOCR
5、安装第三方库shapely、pyclipper,这是运行PaddleOCR的依赖库,没有他们PaddleOCR运行不了
6、安装百度的PaddleOCR框架,有基于移动端的识别框架,也有基于服务端的识别框架,本文使用服务端框架
三、详细步骤
1、配置Python环境
对于初始的服务器来说,其内置的Python版本一般为2.7,已经不再适用当前环境所需的要求,所以需要重新安装新版本的Python环境。为了方便,我直接使用了Anaconda,它把Python和一些常用的库有集合起来了,不需要后续再一个个下载安装。下面进行第一步,下载Anaconda安装包。建议使用使用清华的镜像下载,速度会快很多,清华园镜像地址
将镜像下载进自己的服务器内,我新建了一个Downloads目录专门来存放下载下来的文件

把Anaconda的安装包下载下列后,只需要执行一个bash命令即可: bash Anaconda3-2020.02-Linux-x86_64.sh。然后就是根据提示,要么回车要么输入 yes 。由于笔者写文的时候,环境已经配置好了,没有保留Anaconda的安装截图,如果中途没有报错,一般就是安装成功了。要验证也非常简单,只需要输入:anaconda -V 和 conda -V ,有显示相对应的版本号就算成功了,如下图。

因为有用到图像处理,所以还需要安装一个openCV,安装步骤也非常简单,一句命令即可
pip install opencv-python
2、安装PaddlePaddle
PaddlePaddle是百度旗下的一个人工智能开发框架,功能类似于tensorflow和PyTorch等等。对于PaddlePaddle的安装和使用,百度有给出非常简单而清楚的使用教程,教程链接:https://www.paddlepaddle.org.cn/install/quick#show_info ,这里给出了各个系统各个环境对应的安装教程,笔者也是根据这份教程进行简易安装的。
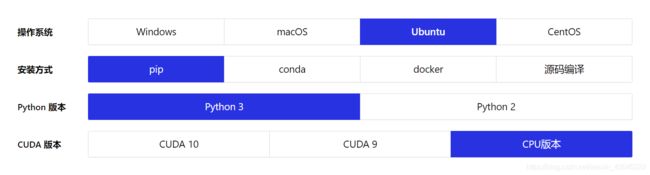
- 需要确认您的 Ubuntu 14.04/16.04/18.04 是 64 位操作系统*
- 确认您需要安装 PaddlePaddle 的 Python 是您预期的位置,因为您计算机可能有多个 Python
which python3
(根据您的环境您可能需要替换本说明中所有命令行中的 python3 为 python ,或者替换为具体的 Python 路径)
- 同时检查 Python 3 的版本,确认是 3.5.1+/3.6/3.7:
python3 --version
- 确认 Python 有对应的 pip,检查 Python 对应的 pip 的版本,确认是 9.0.1+:
python3 -m ensurepip
python3 -m pip --version
- 确认 Python 和 pip 是 64 bit,并且处理器架构是x86_64架构,目前PaddlePaddle不支持arm64架构
下面的两个命令分别输出的是 “64bit” 和 “x86_64” 即可:
python3 -c "import platform;print(platform.architecture()[0]);print(platform.machine())"
- 执行以下命令安装(推荐使用百度源):
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple
或
python3 -m pip install paddlepaddle -i https://pypi.tuna.tsinghua.edu.cn/simple
验证信息
使用 python3 进入python解释器,输入import paddle.fluid ,再输入 paddle.fluid.install_check.run_check()。
如果出现 Your Paddle Fluid is installed successfully!,说明您已成功安装。
如果顺利的话,大概几分钟就可以安装成功了,安装教程非常简单。
3、安装PaddleHub
paddlehub安装就极其简单了,一句命令就行:pip install paddlehub,如果担心自己安装的版本不是最新版,也可以使用paddlehub的更新命令:pip install paddlehub --upgrade -i https://pypi.tuna.tsinghua.edu.cn/simple
4、安装第三方库shapely、pyclipper
理论上来说,在没有意外的情况下,使用下面两句话就可以安装成功了。安装后检验的方式也非常简单,使用 python 进入python解释器,尝试导入两个库,没有报错就说明安装成功了!
pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple

这里插个题外话,笔者最开始使用paddlehub是在自己的windows系统上,在windows上安装shapely,不能直接使用上面这句命令,对于在windows上安装shapely需要先去相应的网站下载其whl文件,再进行pip安装才行,笔者最开始被这个问题困扰许久,所以有用windows系统安装shapely的朋友,可以直接百度windows下安装shapely的教程。windows所需要的whl文件下载地址如下:https://www.lfd.uci.edu/~gohlke/pythonlibs/#shapely
5、安装PaddleOCR
前面的东西都搞定后,当然就是我们的主角登场啦!如果前面的东西都安装没有问题后,那么安装PaddleOCR就变的十分简单了,前面有提到,PaddleOCR是PaddlePaddle的小老弟,那么PaddleOCR也可以算是Paddlehub的小老弟,有了Paddlehub,安装相应的OCR框架就是一句命令的事情。
在安装之前有一个小科普,PaddleHub现已开源OCR文字识别的预训练模型主要有两种:移动端的超轻量模型、服务器端的精度更高模型,从名字也可以大致知道,前者适用于安卓端,后者适用于服务端;前者速度高,后者精度高。对于这两个模型的安装和使用,百度也给了非常非常详细的教程。
移动端的超轻量模型:仅有8.6M,chinese_ocr_db_crnn_mobile。
服务器端的精度更高模型:识别精度更高,chinese_ocr_db_crnn_server。
所接的外包程序有明确的精度需求,所以选择了服务端的OCR预训练模型,下面给出安装服务端的安装命令:
hub install chinese_ocr_db_crnn_server==1.0.3
6、发布PaddleOCR
官网给出的发布命令如下:
hub serving start -m chinese_ocr_db_crnn_server
根据官网给出的发布命令,虽然可以发布成功,但是存在一个很大的问题:我们必须一直开启着这个窗口,并且不能继续执行下一条命令。这对我们来说,执行和调用就非常不方便了,所以考虑将这个进程放入后台,放入后台的命令如下:
nohup hub serving start -m chinese_ocr_db_crnn_server &
nohup:加在一个命令的最前面,表示不挂断的运行命令;&:加载一个命令的最后面,表示这个命令放在后台执行
四、调用
1、Python的调用
import requests
import json
import cv2
import base64
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
# 发送HTTP请求
data = {'images':[cv2_to_base64(cv2.imread("图片地址"))]}
headers = {"Content-type": "application/json"}
url = "http://xxx(服务器ip):8866/predict/chinese_ocr_db_crnn_server"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(r.json()["results"])
这是官方教程给出的Python调用模板,非常简单优雅的代码。但是由于笔者要开始一个在线扫一扫应用,所以使用安卓语言进行调用,于是在这个代码的基础上进行语言转换。
2、Java的调用
package test;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import java.nio.charset.Charset;
import java.text.ParseException;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.http.HttpResponse;
import org.apache.http.HttpStatus;
import org.apache.http.client.HttpClient;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.entity.StringEntity;
import org.apache.http.impl.client.DefaultHttpClient;
import org.apache.http.util.EntityUtils;
import com.alibaba.fastjson.JSONArray;
import com.alibaba.fastjson.JSONObject;
import sun.misc.BASE64Encoder;
public class InvoiceOcr {
//接口地址
private static String apiURL = "http://xxxx:8866/predict/chinese_ocr_db_crnn_server";
//private Log logger = LogFactory.getLog(this.getClass());
private HttpClient httpClient = null;
private HttpPost method = null;
private long startTime = 0L;
private long endTime = 0L;
private int status = 0;
/**
* 接口地址
*
* @param url
*/
public InvoiceOcr(String url) {
if (url != null) {
this.apiURL = url;
}
if (apiURL != null) {
httpClient = new DefaultHttpClient();
method = new HttpPost(apiURL);
}
}
/**
* 调用 API
*
* @param parameters
* @return
*/
public String post(String parameters) {
String body = null;
if (method != null & parameters != null && !"".equals(parameters.trim())) {
try {
// 建立一个NameValuePair数组,用于存储欲传送的参数
method.addHeader("Content-type","application/json");
method.setHeader("Accept", "application/json");
method.setEntity(new StringEntity(parameters, Charset.forName("UTF-8")));
startTime = System.currentTimeMillis();
HttpResponse response = httpClient.execute(method);
endTime = System.currentTimeMillis();
int statusCode = response.getStatusLine().getStatusCode();
//logger.info("statusCode:" + statusCode);
//logger.info("调用API 花费时间(单位:毫秒):" + (endTime - startTime));
if (statusCode != HttpStatus.SC_OK) {
//logger.error("Method failed:" + response.getStatusLine());
status = 1;
}
body = EntityUtils.toString(response.getEntity(),"utf-8");
} catch (IOException e) {
// 网络错误
status = 3;
System.out.println(e);
} finally {
//logger.info("调用接口状态:" + status);
}
}
return body;
}
public static void main(String[] args) throws ParseException {
InvoiceOcr ac = new InvoiceOcr(apiURL);
JSONArray arry = new JSONArray();
JSONObject j = new JSONObject();
arry.add(imageToBase64("E:\\DESK_LIVE\\20200907\\first\\image2.png"));
j.put("images",arry);
String result = ac.post(j.toJSONString());
System.out.println(result);
}
public static String imageToBase64(String path) {
byte[] data = null;
// 读取图片字节数组
try {
InputStream in = new FileInputStream(path);
data = new byte[in.available()];
in.read(data);
in.close();
} catch (IOException e) {
e.printStackTrace();
}
// 对字节数组Base64编码
BASE64Encoder encoder = new BASE64Encoder();
return encoder.encode(data);// 返回Base64编码过的字节数组字符串
}
/**
* 0.成功 1.执行方法失败 2.协议错误 3.网络错误
*
* @return the status
*/
public int getStatus() {
return status;
}
/**
* @param status
* the status to set
*/
public void setStatus(int status) {
this.status = status;
}
/**
* @return the startTime
*/
public long getStartTime() {
return startTime;
}
/**
* @return the endTime
*/
public long getEndTime() {
return endTime;
}
}
现在知道为什么说python代码很优雅了吧!以上代码还需要五个配套的架包,架包名称如下:commons-codec-1.9.jar、commons-logging-1.2.jar、fastjson-1.2.67.jar、httpclient-4.5.jar、httpcore-4.4.1.jar,并且将其关联到相应的lib目录下。
五、结果展示
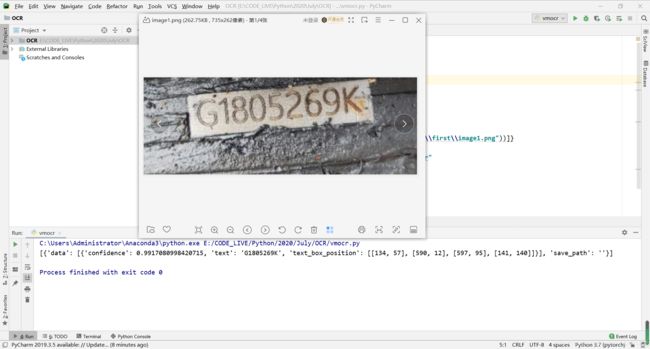
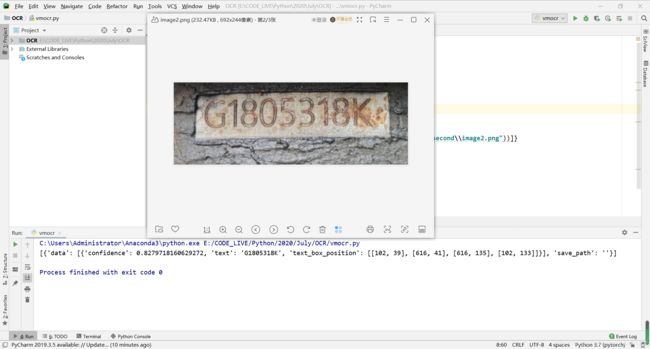
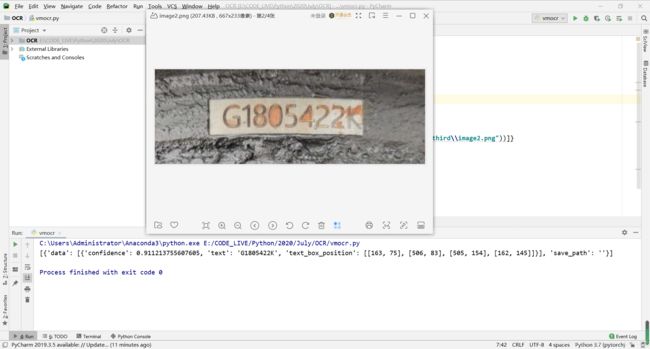
可以看到图片越来越模糊,但是识别的精确度依旧很高,满足用户需求,模型效率表现良好!
自此,本次小结就到此结束了,可以看到整个过程并不困难,复现起来也十分简单,所以如果你觉得有意思,不如动手试试看,做一个自己的在线OCR识别应用程序。