NLP实战之–螺蛳粉评论情感分析和建模分类
NLP实战之–螺蛳粉评论情感分析和建模分类
写在前面:
本文首发于我的微信公众号。新文章首发都会在微信公众号上。
自然语言处理(Natural Language Processing)是目前人工智能的大方向之一。上一篇文章提到的两大方向,计算机视觉(CV)和自然语言处理(NLP)。啥是自然语言?人们日常使用的语言就是自然语言呐,比如汉语,英语。那为啥要对自然语言做处理呢?当然是为了让计算机“智能化”啦。计算机可不认得什么英语、汉语的,你对着计算机喊一声,它肯定不理你。所以才要把自然语言处理成计算机认得的语言。
那什么样的语言,计算机才认得?答:二进制。因为计算机只能读取并且储存0和1。所以,自然语言处理(NLP),就是把咱们人类的语言(例如汉语、英语),处理成为计算机认得的语言。处理完之后能做啥?这就涉及到NLP的应用了,这个应用范围是在是太广范了。有文本分类、机器翻译、情感分析、问答系统、对话系统、知识图谱等等。
硬核实战:
为啥选择螺蛳粉评论做分析?因为最近的一个多月螺蛳粉吃得有点上头,每天都要吃一顿,不吃不舒服。干脆,索性整点好玩的,做一下这个螺蛳粉评论。
还记得,上一篇文章的机器学习流程,跟西红柿炒番茄,啊不,是西红柿炒鸡蛋流程一样的。
机器学习: 数据采集—>数据清洗—>特征工程—>数据建模。
西红柿炒鸡蛋:采集西红柿和鸡蛋—>清洗—>切西红柿、将蛋搅拌—>开炒
第一步,采集数据。
采集数据,最简单粗暴的办法,上百度找,去一些竞赛网搜,比如kaggle、和鲸社区、阿里天池。果不其然,真的有。
点进去,一看,竟然才只有两千条数据。这也太少了吧…
那我再重新去淘宝复制一些(手动复制是不可能的,当然得用爬虫啊)。干脆选一样的店铺把,我就进去李子柒淘宝店铺里面找了个螺蛳粉的,往下拉,直接看到了总评数:200万条评论。这么多,我只要一万就肯定够用了!
很快,我终于知道为什么别人的那个数据集只有两千条了。因为淘宝只能展示最近的两千条评论。也就是说,你最多只能复制最新的2千条。

好吧,新爬下来的两千加上下载的两千,总共4千条,勉强能用吧。
第二步,数据清洗。
清洗数据,没啥操作,就是删除一些重复的、缺失的评论。删完了之后大概还有3960条。

第三步,情感分析
这里跟上边提到的机器学习步骤不太一样。不过没关系,问题不大。
情感分析简单理解就是在文中找到具有各种感情色彩属性的词,统计每个属性的词的个数,哪个类多,这段话就属于哪个属性。这个情感分析部分主要是从以下七个角度对评论进行分析:品牌、物流、包装、产品原料、食用口感、保质期、性价比。具体思路就是,用一个新表格,对情感正负面打分并且把得分存进来。从上述几个角度分析,每个角度都建一个情感词库,遍历每个词库,找到评论中含有该词就进行打分。
1.创建情感词库
词库是啥?词库可以简单理解为一个个“词”的表格。表格里面存的是一些带有情感色彩的词,例如正面情感的属性词“好吃”,负面情感的属性词“太臭”。
2.创建角度词库
为什么要用角度的词库?因为淘宝的评论是有类别的,比如说,评论里面提到了“快递”这个词,就把它分为物流那一类。里面的评论,大致可以分为以下的几个角度。

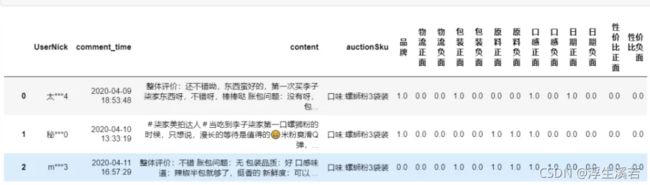
3.遍历词库,找出相应的词进行打分。
先从角度词库,找到属于这个角度的评论,再从情感词库里面,把正负面情感词的次数统计出来。最后进行汇总。统计出来的大概就是这样。
4.数据可视化
数据都在一个表格,不直观,那就把数据,处理一下,做个可视化的图形。
然后做成了下边这个样子。
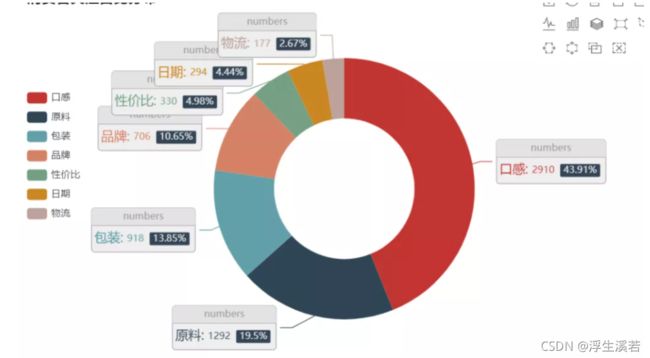
显然,比表格好看多了。这先大概放两张图吧

5.情感分析结论
把结论写出来,基本上就做完了情感分析了。
这里数据通过的分析得出,螺蛳粉,真的好吃!而且好评占大部分。当然消费者最关心的就是口感和原料,最为看重。
第四步,数据打标签
先对上面打分表的数据打上标签。标签,1代表好评,0代表差评。有了标签,计算机才能更精准的认识哪些是好评和差评。那么问题是,怎么打标签?怎么判断好评差评?上面的打分表格里面的角度有物流、包装、产品原料、食用口感、保质期、性价比。刚好6个方面,当每一条评论的正面情感总得分比负面情感总得分大,那就是正面>负面,也就好评。反之则为差评。因为初始的数据集,没有标签,所以得要自己打上标签。
第五步,样本均衡
什么是样本均衡?为什么要进行样本均衡?
首先我们看一下这个有标签的数据,就是已经分好了好评和差的数据。
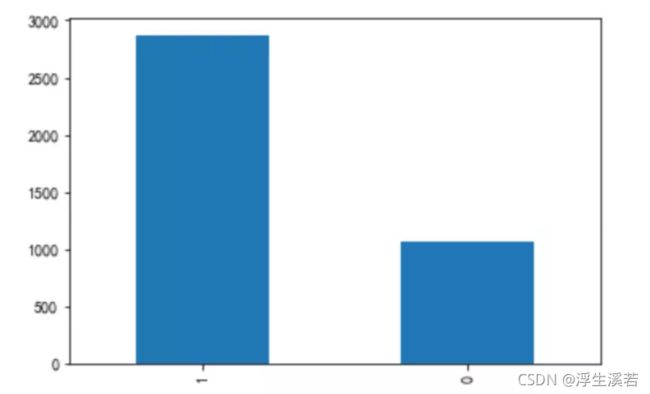
图中的标签1是好评,0是差评。这比例,极其不均衡。先是找数据的时候,数据集不够,自己又爬了2千条,然后数据标签还要打,现在发现了,样本比例又不均衡,还得做样本均衡处理。此刻心情复杂。

不做样本均衡的结果会咋样呢?后边再做解释。可以想象一下,假如你是人工验钞员,每天都是100元的真钞,大概一天几千张,假钞特别少,大概一天遇到几张,然后做了10天,第十一天的时候,突然加进来一半的假钞,这个时候你会按照往常的思维,认为假钞也是很少,这个时候你分的真钞里面就会多了那些你自以为是真钞的假钞。(当然,现实中做这种事可不能马虎)这不就出大错乱了吗?
样本均衡的操作,过采样和欠采样。这里的欠采样是指减少正例的数量,使得数据平衡,再进一步分类。而过采样是指增加反例的数目平衡数据,再分类。
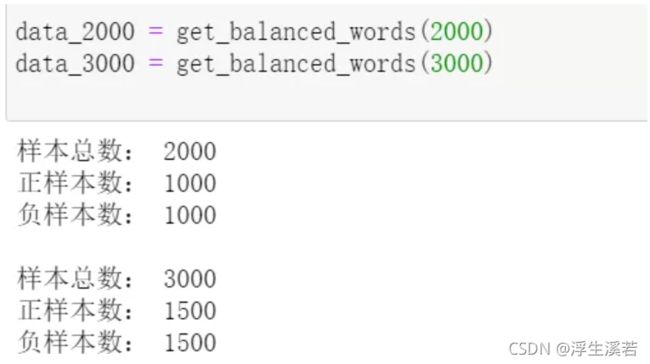
终于,做好了样本均衡,新的数据集分类两个。欠采样数据集总共2000条,过采样数据集总共3000条。
第六步,特征工程
对,这个步骤终于来咯。前面的打标签,样本均衡,是一些其他的意外情况的小步骤。一般的机器学习步骤里面,并不需要这些的。
特征工程,顾名思义,是对原始数据进行一系列工程处理,将其提炼为特征,作为输入,供算法和模型使用。实际上进行特征工程,目的就是将文本数据,变成0,1,让计算机能看懂。
1.切分数据集
在这之前,进行切分数据集。就是分好用来训练,和用来测试的数都有多少。我选择的是,75%做训练集和25%做测试集。训练集,那就是作为训练的,测试集,放进训练好的模型进行评测,看看模型的正确率咋样。严格上来说,切分数据集可以在特征工程之后进行,也就是建立模型之前。在这篇文章,我只讲述我的做法流程。
2.词向量转换
前面说过,计算机只能认0,1的数据。所以要将文本,转化为0,1的数据。这里采用TF-IDF方案。TF-IDF是对每个词进行处理得到的是一个概率向量。
3.特征筛选,降维
特征筛选,就是舍弃一些无用的特征。比如猫,特征有尾巴,爪子,毛色,还有猫年龄。然而,猫年龄对判断它是不是猫,对结果影响不大,一年是猫,十年也是猫。这个时候就可以把猫龄去掉。
降维,目的是减少计算量。特征维度太高,处理起来计算时间长,所以选择降维处理。在经过降维处理后,原来是3200个维度,降到了400维度。(降到1000维度太大,计算时间长,降到100维度,太小,可能误差大,影响结果)
第七步,建立模型
建模步骤,终于到了!采用逻辑回归和XGBoost模型。先分别建模,结果不好就进行模型融合(两种模型结合)。逻辑回归(Logistic Regression)是一种用于解决二分类(0 or 1)问题的机器学习方法。XGBoost(eXtreme Gradient Boosting)极致梯度提升,是基于GBDT的一种算法。GBDT,梯度提升决策树(Gradient Boosting Decision Tree,GBDT)是一种基于boosting集成思想的加法模型。Boosting算法通过改变训练样本的权重,学习多个分类器,并将这些分类器进行线性组合,提高分类性能。简答点理解,就是XGBoost是多个弱的分类器结合的,形成一个强的分类器。
1.训练模型
分别将两个数据集(过采样和欠采样的数据集)作为训练,搭建LR(逻辑回归)和XGBoost模型
2.模型评估
将测试集放入模型检测。结果如下,这种图,也称ROC曲线图。怎么看这个图?ROC曲线越靠拢(0,1)点,越偏离45度对角线越好。(曲线与x轴形成的面积越大,表示模型越好)
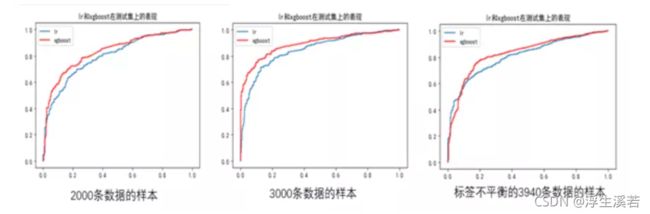
至于结果咋样,那必然是3000条数据的样本最好呀。
3.模型融合
模型融合,是比较常见的优化模型方法。因为单个模型的效果,也许不如几个模型融合之后的效果。这里采用XGBoost+LR策略。顾名思义,先将已有特征训练XGBoost模型,然后利用XGBoost模型学习到的树来构造新特征,最后将新的特征扔到LR模型进行训练。
具体融合过程如下:
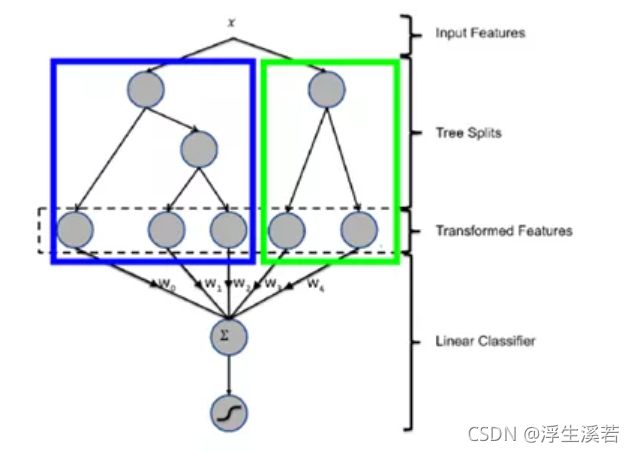
图中x为输入特征,经过两棵树后走到叶子节点。图中左边的树有三个叶子节点,右边的树有两个叶子节点,因此对于输入x,假设其在左子树落在第一个节点,在右子树落在第二个节点,那么在左子树的one-hot编码为[1,0,0],在右子树的one-hot编码为[0,1],最终的特征为两个one-hot编码的组合[1,0,0,0,1]。最后将转化后的特征输入到线性分类器,即可训练的到一个基于组合特征的线性模型。补充一下,one-hot编码,也称独热编码,是一种将分类变量转换为数值向量格式的方法。每个类别在数值向量中都有自己的列或特征,并被转换为0和1的数值向量。
最终来看一下模型效果对比。
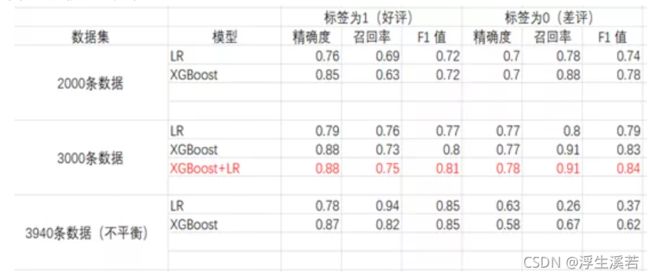
显而易见,模型融合的精确度是最高的(虽然在这提升不大,但是当你在十几万条数据上,提升1%的效果,那相当客观了)。精确度,就是正确的分类个数/总的样本数。
写在最后:
源码放GitHub,附上GitHub链接:https://github.com/zhuhui710/NLP-luosifen
实际上情感分析的难度并不大,难处在于数据的处理和情感词的提取。而模型搭建的效果并不是很好,也许是降维时候的维度数没选好,也可能是模型的参数,没能选到最优参数。特征工程,是决定算法模型上限,特征处理得好了,准确度就高一些。调参,是建模里面最费时的,因此机器学习和深度学习,也称为“炼丹”。(炼丹,参考太上老君炼丹,经过不断调整火候,最终成丹)。实际上这么几千条数据做分析并没有多大用处,这里就当学习了,毕竟我也是一边摸索一边学。