【基于Pytorch的手写汉字识别】
【写在前面的话】
小白一枚,在慢慢学习,通过【记录|总结|归纳】的方式但求点点进步,也希望能给看到看到这篇文章的人点点的理解上的帮助。存在不足之处、观点相右之处,欢迎指出,非常感谢。
记录信息
- 记录时间:2020.12.11
- 记录地点:图书馆六楼LJ0972靠窗位置
- 记录背景:基于之前对【手写汉字美学评估】的了解,认为手写汉字识别是神经网络学习入门的非常好的途径。加之自己对汉字有着非常深厚的情怀,热爱手写汉字。之前已有学习《深度学习入门:基于Python的理论与实现》的一点点基础,想进一步了解深度学习的框架。于是在课题上选择了基于深度学习框架【Pytorch】的手写汉字识别。往落地应用方向考虑,还可以继续做手写汉字的识别与审美鉴赏,我认为在当今这个很少需要动手写字的今天,手写汉字所展现的一些“字如其人”的特性,它的艺术价值,相比起实用价值,开始占据更多的比例。
引用说明
若此博客内容侵犯了您的权益,请及时与我联系
主要参考文章:
- 博主 陈小白233的 「Pytorch」CNN实现手写汉字识别
博主整理了数据集并通过百度网盘分享,可直接下载。 - 博主 知跃 的【Pytorch】基于CNN手写汉字的识别
博主简化了代码,非常适合小白入手,非常感谢
相关函数|库|工具的学习:
【正文内容|代码】
1.数据集整理与路径提取
博主【陈小白233】将数据集分享在百度云上:HWDB1数据集百度云版。但数据集较大,我使用的数据集其实只有前100个汉字,分别在100个文件夹下,文件夹名称对应汉字的标签,从0-99。此外还有测试数据test,总共是5973张单字图像,同样选取前100个汉字,标签一致,与文件夹名称对应。
为了后续的图像数据调用,提取出每张图片数据的路径。
def classes_txt(root, out_path, num_class=None):
# 创建一个存储文件夹名称的列表
dirs = os.listdir(root) # 列出根目录下所有类别所在文件夹名 # root目录下——test文件夹——有3755个文件夹
if not num_class: # 不指定类别数量就读取所有.不指定的时候num_class为空
num_class = len(dirs)
if not os.path.exists(out_path): # 输出文件路径不存在就新建
f = open(out_path, 'w') # 以“W”的方式在指定路径【out_path】创建一个输出文件。例如C:\\pytorch\\try.py
f.close()
# 如果文件中本来就有一部分内容,只需要补充剩余部分
# 如果文件中数据的类别数比需要的多就跳过
with open(out_path, 'r+') as f: # 打开输出txt文件
try:
end = int(f.readlines()[-1].split('\\')[-2]) + 1
# 读取txt文件所有行————取最后一行————以【/】为标志切割并取倒数第二个字符串——取整加一(因为文件是从0开始的)
except:
end = 0
if end < num_class - 1:
dirs.sort() # 对列表的对象[text文件夹下的3755个数据集文件夹名称]进行排序(没有返回值)
dirs = dirs[end:num_class] # 取排序之后的前num_class个数据作为新列表()
for dir in dirs: # [00000,....,00099](假设num_class为100个)(一个00000文件夹包含一个汉字的多个图片数据集)
files = os.listdir(os.path.join(root, dir)) # 生成{一个汉字对应多张图片}名称的【列表】
# 路径拼接成:C:\\pytorch\\writing\\HWDB1\\test/00000,也就是会自动加一个【/】.
for file in files: # 取单张图片的名称——对于图片文件会有【.png】后缀,文件夹则无后缀。
f.write(os.path.join(root, dir, file) + '\n') # 将单张图片的路径信息写入txt文件,并换行
2.数据定义和预处理
- 定义和记录汉字的标签信息。labels
- 利用transform图像预处理包,对图像进行预处理:大小统一设置为64*64、数据类型转换为Pytorch可处理的tensor形式、单通道灰度图像模式。读取图像数据,将可视化的图像处理为数字信息用于计算。images
transform初始化设置:
# 由于数据集图片尺寸不一,因此要进行resize(重设大小)
# 此处先设置transform的参数
# ToTensor():将PIL.Image读的图片(或者numpy的ndarray)转换成(C,H, W)的Tensor格式,并且归一化至[0~1]。(归一化至[0-1]是直接除以255)
# 通道的具体顺序与cv2读的还是PIL.Image读的图片有关系。PIL.Image:(R, G, B)。cv2:(B,G,R)
# Grayscale:将图像转换为灰度图像
transform = transforms.Compose([transforms.Resize((64, 64)), # 将图片大小重设为 64 * 64
transforms.Grayscale(),
transforms.ToTensor()])
读取图像数据信息:
class MyDataset(Dataset):
def __init__(self, txt_path, num_class, transforms=None):
super(MyDataset, self).__init__() # 继承父类的初始化函数,即继承了父类的对象
images = [] # 存储图片路径
labels = [] # 存储类别名,在本例中是数字
# 打开上一步生成的txt文件
with open(txt_path, 'r') as f:
# 遍历f的每一行line,生成新的list,line for line in ...是为了对遍历的每一行做处理的
for line in f: # 本身就是一行一行读取。
if int(line.split('\\')[-2]) >= num_class: # 只读取前 num_class 个类
break
# 由于此处本就是一行一行读取,不去掉换行符的话,会多一个换行————即多一行空格
line = line.strip('\n') # 移除字符串头尾指定的字符(默认为空格)——此处\n转义为换行
images.append(line) # 使用append()给images添加元素————储存单张图片路径
labels.append(int(line.split('\\')[-2])) # 比如00000对应汉字一;00008对应汉字不
# 两者蕴含的信息是前num_class个类别字的所有图片
# 这里不实际加载图片,只是指定图片的路径和标签
# 调用__getitem__时才会真正读取图片(用的PIL工具)
self.images = images # 图片的路径
self.labels = labels # 哪个汉字
self.transforms = transforms # 图片需要进行的变换,ToTensor()等等
# 在实例中:tensor;大小重置为64*64;灰度图像(所以输入通道是1!!!)
# 如果在类中定义了__getitem__()方法,那么他的实例对象(假设为P)就可以这样P[key]取值。
# 当实例对象做P[key]运算时,就会调用类中的__getitem__()方法。
# 真正去读取图片
def __getitem__(self, index):
image = Image.open(self.images[index]) # 用PIL.Image读取图像,打开为RGB模式(彩色图像模式,输入通道数为3)。
# 其中self.images[index])代表取某张图片的路径
label = self.labels[index] # 取某张图片的对应汉字的标签
if self.transforms is not None:
image = self.transforms(image) # 进行变换(变成灰度图像了,输入通道就是1)
return image, label
# 用于getitem函数中取{图像路径——对应汉字标签},即索引号。
def __len__(self):
return len(self.labels) # 获得lables的长度————也就是所有图片的数量。
3.搭建神经网络
需要注意层级之间参数的关联
class NetSmall(nn.Module):
# 卷积→池化→卷积→全连接→全连接→输出100个汉字的概率(略去了softmax层)
def __init__(self):
super(NetSmall, self).__init__() # 父类继承
self.conv1 = nn.Conv2d(1, 6, 3) # 3个参数分别是in_channels,out_channels,kernel_size,还可以加padding
# in_channels — 输入信号的通道;out_channels(int) – 卷积产生的通道;kerner_size - 卷积核|滤波器/卷积层窗口的尺寸
self.pool = nn.MaxPool2d(2, 2) # 池化层窗口大小,窗口移动的步长。(二者通常设置为相同,默认也是步长=窗口大小)
self.conv2 = nn.Conv2d(6, 16, 5) # 第二层的输入通道=第一层的输出通道
self.fc1 = nn.Linear(2704, 512) # linear是全连接层,2个参数分别是输入神经元数、输出神经元数。【与连接的两层神经元数量保持一致】
self.fc2 = nn.Linear(512, 84) # 使用的是Xavier权重初值
self.fc3 = nn.Linear(84, 100) # 100代表一次处理100个汉字(前100张有5973张图像)
'''
一层卷积层的几个参数:
in_channels=3:表示的是输入的通道数,由于是RGB型的,所以通道数是3. 此处实例输入通道设置为1,应该是RGB型后经过了某种处理
out_channels=96:表示的是输出的通道数,设定输出通道数的96(这个是可以根据自己的需要来设置的)
kernel_size=12:表示卷积核的大小是12x12的,也就是上面的 “F”, F=12
stride=4:表示的是步长为4,也就是上面的S, S=4
padding=2:表示的是填充值的大小为2,也就是上面的P, P=2
假如你的图像的输入size是256x256的,由计算公式知N=(256-12+2x2)/4+1=63,也就是输出size为63x63的
'''
# (64-3)/2取31,(31-5)/2取13,到第一层全连接层,13*13*16=2704
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 第一层:卷积+激活+池化
x = self.pool(F.relu(self.conv2(x))) # 第二层:卷积+激活+池化
x = x.view(-1, 2704) # view函数相当于numpy的reshape
x = F.relu(self.fc1(x)) # 全连接+激活
x = F.relu(self.fc2(x)) # 全连接+激活
x = self.fc3(x) # 全连接输出。不加softmax函数不影响分类结果
return x
4.模型训练方法
超参数定义
# 定义超参数
EPOCH = 10 # 训练次数。——即训练10次
# 一个epoch代表 所有训练数据/batch_size 进行学习的数据大小
BATCH_SIZE = 50 # 数据集划分。size of mini-batch
LR = 0.001 # 学习率
参数更新方法选择:
Adam参数更新方法效率高,随机梯度下降法SGD在此例中计算速读很慢。
optimizer = torch.optim.Adam(model.parameters(), lr=LR) # 参数优化方法选择
# optimizer = torch.optim.SGD(model.parameters(), lr=LR, momentum=0.9)
loss_func = nn.CrossEntropyLoss() # 分类误差计算函数————交叉熵误差损失函数
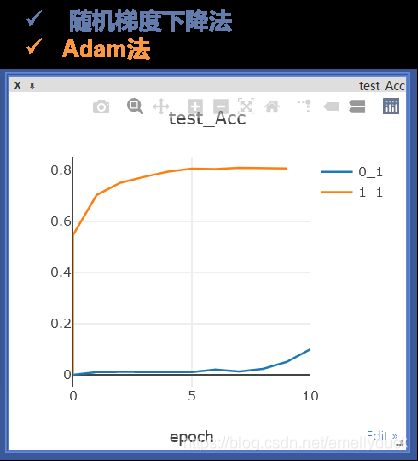
5.放入迭代器进行计算
将读出来的图片信息放入迭代器中,使得数据可以被batch操作。
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True) # 设置为50
test_loader = DataLoader(test_set, batch_size=5973, shuffle=True)
# shuffle – 设置为True时会在每个epoch(此处根据设置计算出来的是10)重新打乱数据(默认: False).
# 测试集为5973张(前100类汉字的test数据集数量)图片。一次性测试所有
# 测试数据只需要将所有放入,一次测完就好了(batch直接设置为5937)
# 所以不需要epoch的循环
for step, (x, y) in enumerate(test_loader): # x,y分别是图片和对应标签
test_x, labels_test = x.to(device), y.to(device)
6.可视化结果分析
使用可视化工具Visdom进行结果分析:
需要主义的是需先在命令行执行:
python -m visdom.server
# 命令行执行 python -m visdom.server
viz = visdom.Visdom(env='dev')
# 初始化
train_loss_x, train_loss_y = 0, 0
win1 = viz.line(X=np.array([train_loss_x]), Y=np.array([train_loss_y]), opts=dict(title='train_Loss', xlabel='epoch'))
test_acc_x, test_acc_y = 0, 0
win2 = viz.line(X=np.array([test_acc_x]), Y=np.array([test_acc_y]), opts=dict(title='test_Acc', xlabel='epoch'))
# train_acc_x, train_acc_y = 0, 0
# win3 = viz.line(X=np.array([train_acc_x]), Y=np.array([train_acc_y]), opts=dict(title='train_Acc'))
# 每个epoch更新一次
viz.line(X=np.array([epoch]), Y=np.array([tr_loss.data]), win=win1, update='append')
viz.line(X=np.array([epoch]), Y=np.array([tx_accuracy]), win=win2, update='append')
# viz.line(X=np.array([epoch]), Y=np.array([tr_accuracy]), win=win3, update='append')
训练数据损失值,以及测试数据识别准确度:
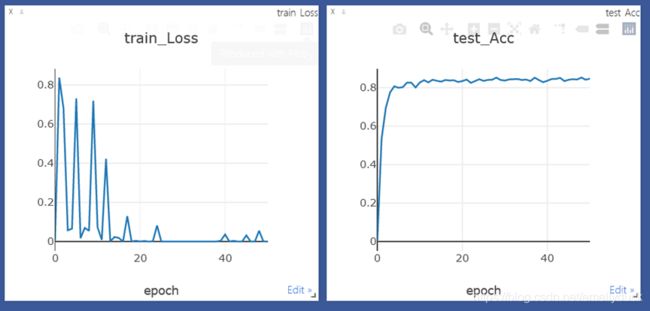
7.整体代码
import os
import torch
import visdom
import numpy as np
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms # 图像预处理包
from torch.utils.data import DataLoader, Dataset
from PIL import Image
# 命令行执行 python -m visdom.server
viz = visdom.Visdom(env='dev')
def classes_txt(root, out_path, num_class=None):
# 创建一个存储文件夹名称的列表
dirs = os.listdir(root) # 列出根目录下所有类别所在文件夹名 # root目录下——test文件夹——有3755个文件夹
if not num_class: # 不指定类别数量就读取所有.不指定的时候num_class为空
num_class = len(dirs)
if not os.path.exists(out_path): # 输出文件路径不存在就新建
f = open(out_path, 'w') # 以“W”的方式在指定路径【out_path】创建一个输出文件。例如C:\\pytorch\\try.py
f.close()
# 如果文件中本来就有一部分内容,只需要补充剩余部分
# 如果文件中数据的类别数比需要的多就跳过
with open(out_path, 'r+') as f: # 打开输出txt文件
try:
end = int(f.readlines()[-1].split('\\')[-2]) + 1
# 读取txt文件所有行————取最后一行————以【/】为标志切割并取倒数第二个字符串——取整加一(因为文件是从0开始的)
except:
end = 0
if end < num_class - 1:
dirs.sort() # 对列表的对象[text文件夹下的3755个数据集文件夹名称]进行排序(没有返回值)
dirs = dirs[end:num_class] # 取排序之后的前num_class个数据作为新列表()
for dir in dirs: # [00000,....,00099](假设num_class为100个)(一个00000文件夹包含一个汉字的多个图片数据集)
files = os.listdir(os.path.join(root, dir)) # 生成{一个汉字对应多张图片}名称的【列表】
# 路径拼接成:C:\\pytorch\\writing\\HWDB1\\test/00000,也就是会自动加一个【/】.
for file in files: # 取单张图片的名称——对于图片文件会有【.png】后缀,文件夹则无后缀。
f.write(os.path.join(root, dir, file) + '\n') # 将单张图片的路径信息写入txt文件,并换行
class MyDataset(Dataset):
def __init__(self, txt_path, num_class, transforms=None):
super(MyDataset, self).__init__() # 继承父类的初始化函数,即继承了父类的对象
images = [] # 存储图片路径
labels = [] # 存储类别名,在本例中是数字
# 打开上一步生成的txt文件
with open(txt_path, 'r') as f:
# 遍历f的每一行line,生成新的list,line for line in ...是为了对遍历的每一行做处理的
for line in f: # 本身就是一行一行读取。
if int(line.split('\\')[-2]) >= num_class: # 只读取前 num_class 个类
break
# 由于此处本就是一行一行读取,不去掉换行符的话,会多一个换行————即多一行空格
line = line.strip('\n') # 移除字符串头尾指定的字符(默认为空格)——此处\n转义为换行
images.append(line) # 使用append()给images添加元素————储存单张图片路径
labels.append(int(line.split('\\')[-2])) # 比如00000对应汉字一;00008对应汉字不
# 两者蕴含的信息是前num_class个类别字的所有图片
# 这里不实际加载图片,只是指定图片的路径和标签
# 调用__getitem__时才会真正读取图片(用的PIL工具)
self.images = images # 图片的路径
self.labels = labels # 哪个汉字
self.transforms = transforms # 图片需要进行的变换,ToTensor()等等
# 在实例中:tensor;大小重置为64*64;灰度图像(所以输入通道是1!!!)
# 如果在类中定义了__getitem__()方法,那么他的实例对象(假设为P)就可以这样P[key]取值。
# 当实例对象做P[key]运算时,就会调用类中的__getitem__()方法。
# 真正去读取图片
def __getitem__(self, index):
image = Image.open(self.images[index]) # 用PIL.Image读取图像,打开为RGB模式(彩色图像模式,输入通道数为3)。
# 其中self.images[index])代表取某张图片的路径
label = self.labels[index] # 取某张图片的对应汉字的标签
if self.transforms is not None:
image = self.transforms(image) # 进行变换(变成灰度图像了,输入通道就是1)
return image, label
# 用于getitem函数中取{图像路径——对应汉字标签},即索引号。
def __len__(self):
return len(self.labels) # 获得lables的长度————也就是所有图片的数量。
class NetSmall(nn.Module):
# 卷积→池化→卷积→全连接→全连接→输出100个汉字的概率(略去了softmax层)
def __init__(self):
super(NetSmall, self).__init__() # 父类继承
self.conv1 = nn.Conv2d(1, 6, 3) # 3个参数分别是in_channels,out_channels,kernel_size,还可以加padding
# in_channels — 输入信号的通道;out_channels(int) – 卷积产生的通道;kerner_size - 卷积核|滤波器/卷积层窗口的尺寸
self.pool = nn.MaxPool2d(2, 2) # 池化层窗口大小,窗口移动的步长。(二者通常设置为相同,默认也是步长=窗口大小)
self.conv2 = nn.Conv2d(6, 16, 5) # 第二层的输入通道=第一层的输出通道
self.fc1 = nn.Linear(2704, 512) # linear是全连接层,2个参数分别是输入神经元数、输出神经元数。【与连接的两层神经元数量保持一致】
self.fc2 = nn.Linear(512, 84) # 使用的是Xavier权重初值
self.fc3 = nn.Linear(84, 100) # 100代表一次处理100个汉字(前100张有5973张图像)
'''
一层卷积层的几个参数:
in_channels=3:表示的是输入的通道数,由于是RGB型的,所以通道数是3. 此处实例输入通道设置为1,应该是RGB型后经过了某种处理
out_channels=96:表示的是输出的通道数,设定输出通道数的96(这个是可以根据自己的需要来设置的)
kernel_size=12:表示卷积核的大小是12x12的,也就是上面的 “F”, F=12
stride=4:表示的是步长为4,也就是上面的S, S=4
padding=2:表示的是填充值的大小为2,也就是上面的P, P=2
假如你的图像的输入size是256x256的,由计算公式知N=(256-12+2x2)/4+1=63,也就是输出size为63x63的
'''
# (64-3)/2取31,(31-5)/2取13,到第一层全连接层,13*13*16=2704
def forward(self, x):
x = self.pool(F.relu(self.conv1(x))) # 第一层:卷积+激活+池化
x = self.pool(F.relu(self.conv2(x))) # 第二层:卷积+激活+池化
x = x.view(-1, 2704) # view函数相当于numpy的reshape
x = F.relu(self.fc1(x)) # 全连接+激活
x = F.relu(self.fc2(x)) # 全连接+激活
x = self.fc3(x) # 全连接输出。不加softmax函数不影响分类结果
return x
# 定义超参数
EPOCH = 10 # 训练次数。——即训练10次
# 一个epoch代表 所有训练数据/batch_size 进行学习的数据大小
BATCH_SIZE = 50 # 数据集划分。size of mini-batch
LR = 0.001 # 学习率
model = NetSmall()
# 网络的可学习参数可以通过model.parameters()返回————variable对象
optimizer = torch.optim.Adam(model.parameters(), lr=LR) # 参数优化方法选择
# optimizer = torch.optim.SGD(model.parameters(), lr=LR, momentum=0.9)
loss_func = nn.CrossEntropyLoss() # 分类误差计算函数————交叉熵误差损失函数
device = torch.device('cpu')
model.to(device)
root = 'C:\\Users\\viola\\Desktop\\pytorch\\writing\\HWDB1' # 我文件的储存位置
classes_txt(root + '\\train', root+'\\train.txt', 100)
classes_txt(root + '\\test', root+'\\test.txt', 100)
classes_txt(root + '\\self', root+'\\self.txt', 100)
# 由于数据集图片尺寸不一,因此要进行resize(重设大小)
# 此处先设置transform的参数
# ToTensor():将PIL.Image读的图片(或者numpy的ndarray)转换成(C,H, W)的Tensor格式,并且归一化至[0~1]。(归一化至[0-1]是直接除以255)
# 通道的具体顺序与cv2读的还是PIL.Image读的图片有关系。PIL.Image:(R, G, B)。cv2:(B,G,R)
# Grayscale:将图像转换为灰度图像
transform = transforms.Compose([transforms.Resize((64, 64)), # 将图片大小重设为 64 * 64
transforms.Grayscale(),
transforms.ToTensor()])
# 真正开始读图片
train_set = MyDataset(root + '/train.txt', num_class=100, transforms=transform) # num_class 选取100种汉字 提出图片和标签
test_set = MyDataset(root + '/test.txt', num_class=100, transforms=transform)
self_set = MyDataset(root + '/self.txt', num_class=100, transforms=transform)
# 将读出来的图片信息放入迭代器中—————使得数据可以被batch操作
train_loader = DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True) # 设置为50
test_loader = DataLoader(test_set, batch_size=5973, shuffle=True)
self_loader = DataLoader(self_set, batch_size=90, shuffle=True)
# shuffle – 设置为True时会在每个epoch(此处根据设置计算出来的是10)重新打乱数据(默认: False).
# 测试集为5973张(前100类汉字的test数据集数量)图片。一次性测试所有
# 测试数据只需要将所有放入,一次测完就好了(batch直接设置为5937)
# 所以不需要epoch的循环
for step, (x, y) in enumerate(test_loader): # x,y分别是图片和对应标签
test_x, labels_test = x.to(device), y.to(device)
for step, (x, y) in enumerate(self_loader): # x,y分别是图片和对应标签
self_x, labels_self = x.to(device), y.to(device)
# 初始化
train_loss_x, train_loss_y = 0, 0
win1 = viz.line(X=np.array([train_loss_x]), Y=np.array([train_loss_y]), opts=dict(title='train_Loss', xlabel='epoch'))
test_acc_x, test_acc_y = 0, 0
win2 = viz.line(X=np.array([test_acc_x]), Y=np.array([test_acc_y]), opts=dict(title='test_Acc', xlabel='epoch'))
# train_acc_x, train_acc_y = 0, 0
# win3 = viz.line(X=np.array([train_acc_x]), Y=np.array([train_acc_y]), opts=dict(title='train_Acc'))
for epoch in range(EPOCH): # train数据集有23802张图(前100种汉字)
epoch = epoch+1
for step, (x, y) in enumerate(train_loader):
train_x, labels_train = x.to(device), y.to(device)
output = model(train_x)
tr_loss = loss_func(output, labels_train) # 训练数据损失函数
optimizer.zero_grad() # 把梯度置零。等价为model.zero_grad()
tr_loss.backward() # 反向传播,计算当前梯度
optimizer.step() # 根据梯度更新网络参数
if step % 50 == 0:
# 验证训练出来的模型(参数)对测试数据的识别度
test_output = model(test_x)
pred_y_tx = torch.max(test_output, 1)[1].data.squeeze()
tx_accuracy = (pred_y_tx == labels_test).sum().item() / labels_test.size(0)
'''torch.max(test_output, 1):输出格式[tensor([最大值]),tensor([最大值的位置])]。参数1/0,输出行(方向)/列最大
test_output shape=5973*100(5973张图像,每张图是100个汉字的可能性)
torch.max(test_output, 1) shape=5973(图片数)*2。
torch.max(test_output, 1)[1] 取位置————即对应解算出来的汉字标签'''
'''训练数据的识别准确度
train_output = model(train_x)
pred_y_tr = torch.max(train_output, 1)[1].data.squeeze()
tr_accuracy = (pred_y_tr == labels_train).sum().item() / labels_train.size(0)'''
self_output = model(self_x)
pred_y_tse = torch.max(self_output, 1)[1].data.squeeze()
se_accuracy = (pred_y_tse == labels_self).sum().item() / labels_self.size(0)
print('Epoch:', epoch, '| train loss:%.4f' % tr_loss.data, '| test accuracy:', tx_accuracy, '| self accuracy:', se_accuracy)
# 输出训练次数、误差、
# 每个epoch更新一次
viz.line(X=np.array([epoch]), Y=np.array([tr_loss.data]), win=win1, update='append')
viz.line(X=np.array([epoch]), Y=np.array([tx_accuracy]), win=win2, update='append')
# viz.line(X=np.array([epoch]), Y=np.array([tr_accuracy]), win=win3, update='append')
print('Finish training')
【总结思考】
-
基于CPU计算速度特别慢,开始只使用了一小部分数据进行计算,测试准确率可以达到80%。增加训练数据,将测试识别准确率提高到了85%,但计算过慢没有继续增加数据计算。
基于这一点,目前想到两种改进方法:
①使用pickle模块保存训练过程的模型,便不需要反复等待漫长的过程
②换电脑用GPU计算。 -
最后试了一下识别自己收集的周围朋友的手写单字图像,效果不尽人意,识别率非常低。可能原因是手写汉字的背景坏境,直接作为数据将其与数据集同等处理的话,不同之处在于非字迹部分像素点不是255。如果能对图像进行预处理,识别效果可能会改善。