Jina 实例秀 —— 智能聊天机器人

Jina将开启一个全新的教程系列——实例秀。在这个系列中我们将进行Jina实际用例的教学,手把手教你把Jina用起来!
在本教程中,你将创建一个基于文本到文本模型的聊天机器人,了解这个示例的每个部分是如何工作的,以及如何使用不同数据集来创建自己的聊天机器人。(本例中使用新冠疫情的问答数据集)
Let's begin♀️
(文章末尾附有完整代码)
Jina安装和环境配置
运行下面的指令安装Jina
pip install jina[standard]Jina安装小提示:
推荐在一个新的python虚拟环境中安装Jina
再安装所需的环境依赖:
pip install click==7.1.2
pip install transformers==4.1.1
pip install torch==1.7.1目录创建和数据准备
首先,我们创建一个文件夹并命名为tutorial。然后点击“阅读原文”找到static文件夹的下载链接,下载好后复制到tutorial内。static中有用于呈现最后结果的CSS和HTML等文件。
下一步,我们将下载Kaggle中的COVID数据集。在一个完整的Jina搜索框架中,数据一般会先经过预处理。但因为我们的用例数据非常简单,不需要进一步处理这些数据。我们可以下载数据后直接用于后续的数据编码。
def download_data(targets, download_proxy=None, task_name='download covid-dataset'):
"""
Download data.
:param targets: target path for data.
:param download_proxy: download proxy (e.g. 'http', 'https')
:param task_name: name of the task
"""
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
if download_proxy:
proxy = urllib.request.ProxyHandler(
{'http': download_proxy, 'https': download_proxy}
)
opener.add_handler(proxy)
urllib.request.install_opener(opener)
with ProgressBar(task_name=task_name, batch_unit='') as t:
for key, value in targets.items():
if not os.path.exists(value['filename']):
urllib.request.urlretrieve(
value['url'], value['filename'], reporthook=lambda *x: t.update_tick(0.01)
)Flow的框架搭建及可视化
「Flow是Jina中的一个基本概念,可将其视为Jina中的管理器。它负责管理应用程序内运行的所有任务」
我们先将Flow的基本框架搭建好,再将其进行可视化。Flow的可视化有助于我们确保框架的完整性。我们在Flow的基本框架中添加了两个用于可视化的虚拟Executor, 并分别命名为MyTransformer和MyIndexer。
from jina import Flow, Document, Executor, requests
class MyTransformer(Executor):
@requests(on='/foo')
def foo(self, **kwargs):
print(f'foo is doing cool stuff: {kwargs}')
class MyIndexer(Executor):
@requests(on='/bar')
def bar(self, **kwargs):
print(f'bar is doing cool stuff: {kwargs}')
flow = (
Flow()
.add(name='MyTransformer', uses=MyTransformer)
.add(name='MyIndexer', uses=MyIndexer)
.plot('our_flow.svg')
)Flow框架搭建小提示:
这里的MyTransformer和MyIndever是虚拟的
Executor,只负责打印一行信息
flow.plot( )函数将搭建好的Flow进行可视化

搭建好了完整的Flow框架后,我们就要对Flow中的Executor进行具体功能的代码编写了。但我们今天不会深入讨论Executor的构造,你可以在“阅读原文”中找到包含本例Executor的代码文件executors.py的下载链接,下载好后复制到tutorial内即可。
运行和访问Flow
至此,我们就可以将Flow运行起来了:建立数据集的索引,并挂起当前进程等待后续的查询访问。
targets = {
'covid-csv': {
'url': args.index_data_url,
'filename': os.path.join(args.workdir, 'dataset.csv'),
}
}
with f, open(targets['covid-csv']['filename']) as fp:
f.index(from_csv(fp, field_resolver={'question': 'text'}))
# switch to REST gateway at runtime
f.use_rest_gateway(args.port_expose)
url_html_path = 'file://' + os.path.abspath(
os.path.join(
os.path.dirname(os.path.realpath(__file__)), 'static/index.html'
)
)
try:
webbrowser.open(url_html_path, new=2)
except:
pass # intentional pass, browser support isn't cross-platform
finally:
default_logger.success(
f'You should see a demo page opened in your browser, '
f'if not, you may open {url_html_path} manually'
)
if not args.unblock_query_flow:
f.block()Flow运行小提示:
为防止Flow运行后立即退出,需使用
flow.block( )挂起当前进程
使用from_csv加载数据集;使用
field_resolver将数据集的文本映射为
Document属性
开始聊天!
将所有的代码模块放在一个python文件app.py内并运行,你就会看到一个新页面自动在浏览器中打开,里面有一个智能问答机器人等待着跟你聊天!
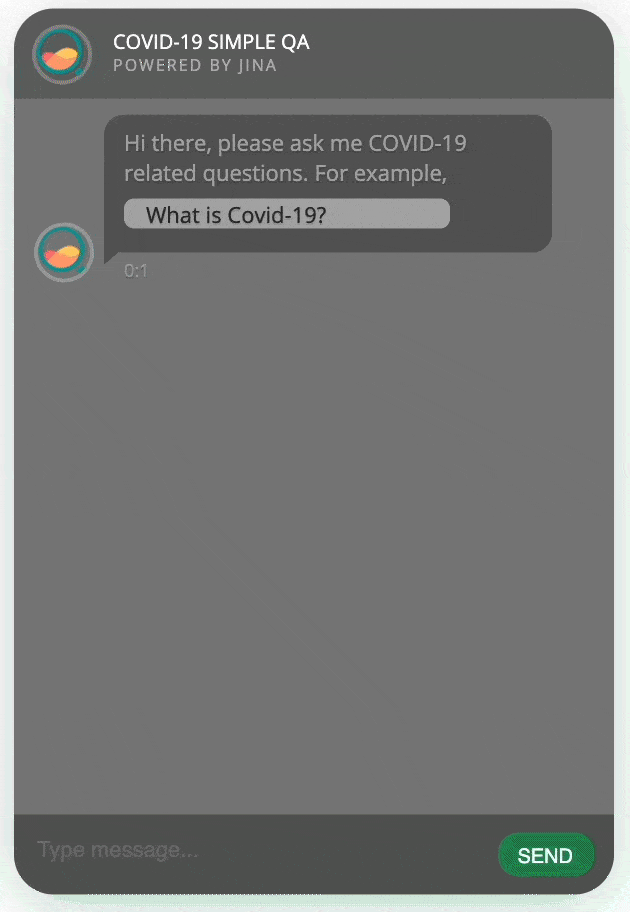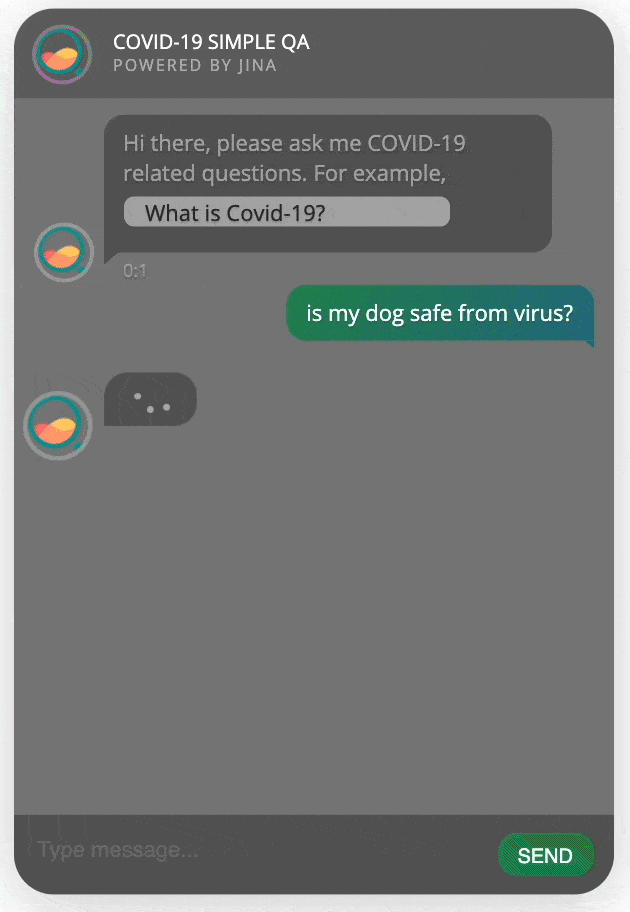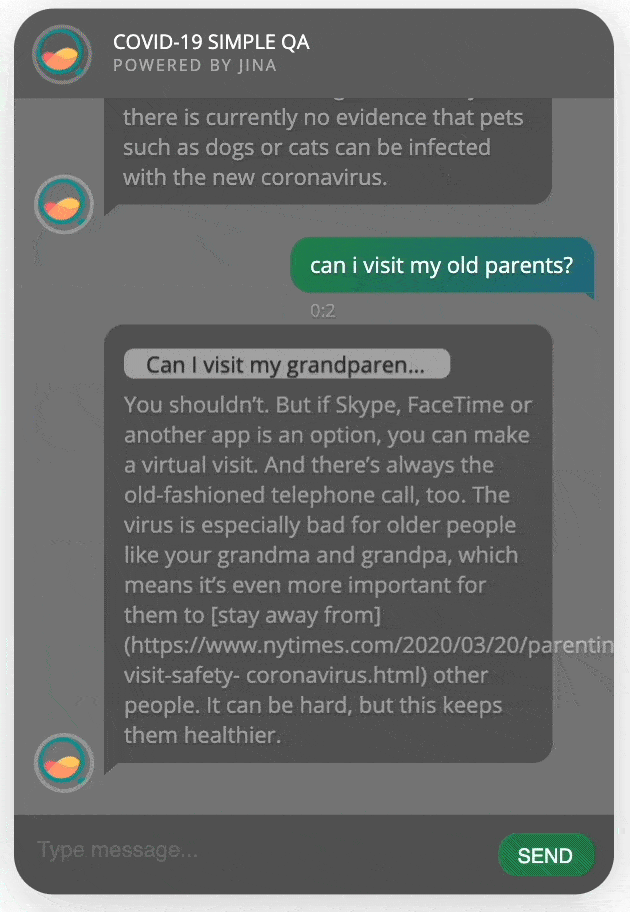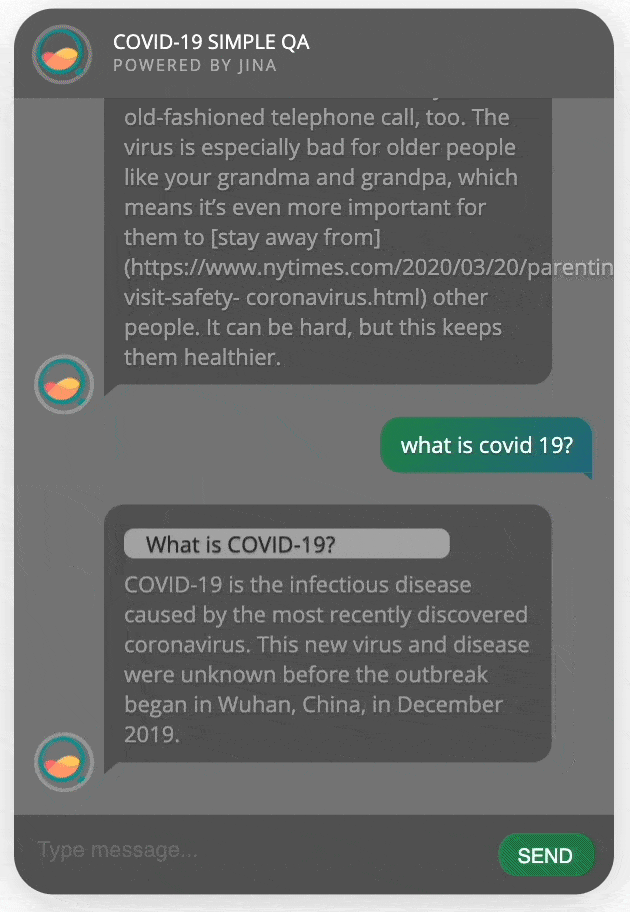
完整代码:
import os
import urllib.request
import webbrowser
from pathlib import Path
from jina import Flow, Executor
from jina.logging import default_logger
from jina.logging.profile import ProgressBar
from jina.parsers.helloworld import set_hw_chatbot_parser
from jina.types.document.generators import from_csv
if __name__ == '__main__':
from executors import MyTransformer, MyIndexer
else:
from .executors import MyTransformer, MyIndexer
def download_data(targets, download_proxy=None, task_name='download fashion-mnist'):
"""
Download data.
:param targets: target path for data.
:param download_proxy: download proxy (e.g. 'http', 'https')
:param task_name: name of the task
"""
opener = urllib.request.build_opener()
opener.addheaders = [('User-agent', 'Mozilla/5.0')]
if download_proxy:
proxy = urllib.request.ProxyHandler(
{'http': download_proxy, 'https': download_proxy}
)
opener.add_handler(proxy)
urllib.request.install_opener(opener)
with ProgressBar(task_name=task_name, batch_unit='') as t:
for k, v in targets.items():
if not os.path.exists(v['filename']):
urllib.request.urlretrieve(
v['url'], v['filename'], reporthook=lambda *x: t.update_tick(0.01)
)
def tutorial(args):
Path(args.workdir).mkdir(parents=True, exist_ok=True)
'''
Comment this to use the exectors you have in `executors.py`
class MyTransformer(Executor):
def foo(self, **kwargs):
print(f'foo is doing cool stuff: {kwargs}')
class MyIndexer(Executor):
def bar(self, **kwargs):
print(f'bar is doing cool stuff: {kwargs}')
'''
targets = {
'covid-csv': {
'url': args.index_data_url,
'filename': os.path.join(args.workdir, 'dataset.csv'),
}
}
# download the data
download_data(targets, args.download_proxy, task_name='download covid-dataset')
f = (
Flow()
.add(name='MyTransformer', uses=MyTransformer)
.add(name='MyIndexer', uses=MyIndexer)
.plot('test.svg')
)
with f, open(targets['covid-csv']['filename']) as fp:
f.index(from_csv(fp, field_resolver={'question': 'text'}))
# switch to REST gateway at runtime
f.use_rest_gateway(args.port_expose)
url_html_path = 'file://' + os.path.abspath(
os.path.join(
os.path.dirname(os.path.realpath(__file__)), 'static/index.html'
)
)
try:
webbrowser.open(url_html_path, new=2)
except:
pass # intentional pass, browser support isn't cross-platform
finally:
default_logger.success(
f'You should see a demo page opened in your browser, '
f'if not, you may open {url_html_path} manually'
)
if not args.unblock_query_flow:
f.block()
if __name__ == '__main__':
args = set_hw_chatbot_parser().parse_args()
tutorial(args)⭐️Jina实例秀系列教程将不断更新 ⭐️
⭐️敬请持续关注 ⭐️
点击下方 “阅读原文”,获得更详细的Jina 相关教程
往期系列教程

Jina 轻松学 —— Windows中安装Jina

Jina 轻松学 —— 深入Executor

Jina 轻松学 —— 部署和运行