论文笔记(TOP-DOWN)
论文笔记:摘要任务(长文本)--- LONG DOCUMENT SUMMARIZATION WITH TOP-DOWNAND BOTTOM-UP INFERENCE
- 介绍
-
- 摘要
- 简介
- Methods 方法
-
- 自底向上推理(Bottom-Up Inference)
- 自顶向下推理( Top-Down Inference)
-
- Token-Segment Cross-Attention
- 池化层(Pool Methods)
- 实验
介绍
论文:《LONG DOCUMENT SUMMARIZATION WITH TOP-DOWNAND BOTTOM-UP INFERENCE》
渣翻:《采用自上而下以及自下而上推理的长文本摘要》
摘要
文本摘要的目的是压缩长文档并保留关键信息。摘要模型成功的关键是对源文档中单词或标记的潜在表示的忠实推断。最近的大多数模型都是用transformer encoder来推断潜在表征的,这种方法仅仅是自下而上的。另外,基于self-attention-based的推理模型面临着与序列长度有关的二次复杂性问题。因此,作者提出了一个原则性的推理框架来改善这两个方面的总结模型(自下而上,长文档导致注意力计算耗时)。作者提出的框架假设了文档的层次潜在结构,其中顶层在粗粒度的时间尺度上捕获长期依赖,而底层的token级别保留了细节。重要的是,这种分层结构使得标记表征能够以自下而上和自上而下的方式被更新。在自下而上的过程中,标记表征是通过local self-attention来推断的,以利用其效率。然后,自上而下的修正被应用于允许标记捕捉长距离的依赖性。在一组不同的摘要数据集上证明了所提出的框架的有效性,包括叙事、对话、科学文件和新闻。模型实现了(1)相较于full attention Transformers,在短文档上具有竞争性或更好的性能,具有更高的内存和计算效率;以及(2)最近高效的Transformers模型·,广泛地在长文档摘要基准上达到SOTA级别的性能。还表明,与近期提出的GPT-3模型相比,模型可以总结整本书,并使用0.27%的参数(464M vs. 175B)和少得多的训练数据取得有竞争力的性能。结果表明了所提出的框架的普遍适用性和好处。
简介
文本摘要主要的两种方式:抽取式和生成式。提取摘要模型从源文档中提取显著的片段(如单词、句子)来形成摘要,而抽象摘要系统的目的是通过对文档进行调整来生成语义连贯和语言流畅的摘要。最近的研究表明,生成式模型由于抽取式模型,下面作者将focuses on 生成式摘要。
生成式摘要的主流方法——Seq2Seq model(两段式模型,2014),和任意一个RNNs(循环神经网络,1997)实例化的编码器-解码器架构,或者是最近的Transformers模型。编码器部分负责推断出输入文档的潜在表征,解码器负责生成摘要。该论文研究如何推断良好的潜在表征,提高其摘要能力。(重点)作者提出了一个框架:
-
(1)假定一个文档的多尺度潜在结构( 以 token 划分、以 sentence 划分、以 segment 划分…)
-
(2)协同使用自上而下以及自下而上的推理
在多尺度结构中,高级变量(如那些表示句子、片段的变量)以较粗的时间尺度和抽象的细节对文档进行建模,并且适合于捕获文档的长期依赖关系;相比之下低级变量(representing tokens)保留了详细信息,防止了摘要丢失关键细节。
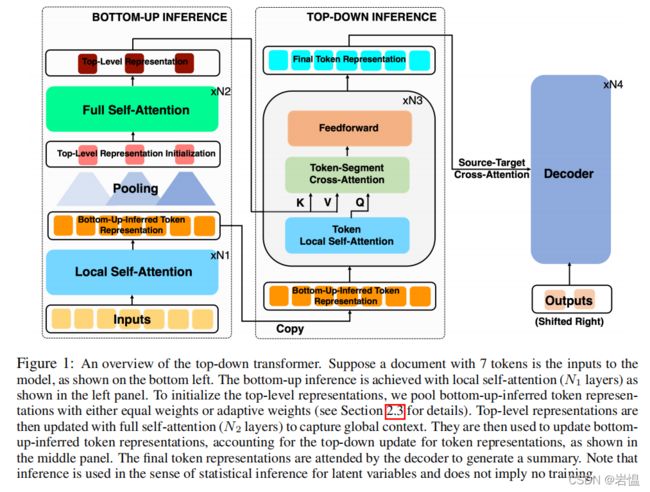
↑ top-down Transformers概述 ↑假设一个含7个token的输入文档作为模型的输入,先是采用局部注意力层(N1层)实现自底向上的推理(图中左下角所示),接着为了初始化自顶向下表示法,采用一个池化层,将自底向上的以相同权重或自适应权重推断的标记【没看懂,详情看章节2.3】
然后,需要初始化上层表征向量表示,接一个N2层的全注意力层用于更新顶层表征向量表示(更新隐藏层向量)实现捕获上下文全局信息。
Top-Level Representation 用于更新 Bottom-Up-Infered Token Repressentation(见上图中间部分)然后这些Token Repressentation会被用到解码器生成摘要。
【作者在这里推荐一下文章,顺带表达了自己的研究背景】
关于摘要生成的模型:Longformer、Pegesus、Bigbird(学习长文摘要的话,这几篇文章都值得看看)
Multi-level models:【关注的是抽取式摘要,并遵循自下而上的推理方法】(懒,不截了)
hierarchical top-down generative models:【这些模型中,在自下而上的路径分布参数中,高级随机变量的参数被计算为低级随机变量的函数,而在自上而下的路径分布参数中,低级变量的分布参数被作为高级变量的函数进行修正。虽然我们不假设文档潜在表示的随机性,但我们的编码器或推理模型遵循相同的想法来推断标记表示】
Transformers 模型 和 预训练模型:CamemBert【短文优势,长文劣势】
【【内容有点多,有机会看完再回来补充】】
Methods 方法
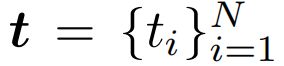
假设一个具有N个tokens的文档,作为输入。
自底向上推理(Bottom-Up Inference)
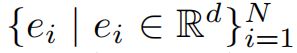
Input Embedding,使用N1层的局部注意力进行计算【局部注意力,第i个token(ti)只关注窗口大小为w附近的token】,所以局部注意力的复杂性由O(n^2)缩减到O(Nw)
局部注意力示意图,x、y轴,x=y即当前计算的token(深绿色),浅绿色则是当前关注的token。

自顶向下推理( Top-Down Inference)
【局部注意力的不足:很显然,局部注意力虽然效率提升了,但无法关注到全文信息。】
【为此,作者提出了这个自顶向下的推理方法】
作者将文档看作拥有二级多尺度(two-level multi-scale)的潜在结构;
那low level采用局部注意力机制计算;
top level 采用更粗糙的粒度(指的是区别token,采用sentences or segments),由于是使用大粒度,因此完全可以通过全局的自注意力计算。
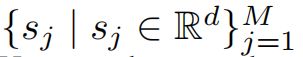
↑这个是top level representations(自顶向下的向量表示)在自注意力更新后的表达式。
【关于这个(top level representations)的初始化问题下面pooling method会提到】
在全注意力更新后的 top level representations 将被用于更新 bottom-up-inferred token representations 。然后下面 ↓ 这一部分就是一个N3层的top-down inference。

在这N3层的推理层中,每层都包括了3个转换:
(1) token local self-attention;
(2) token-segment cross-attention;
(3) feedforward。
(1) 和 (3) 都与自底向上的推理层或局部注意力层相同;
(2) 是 top 和 bottom 层之间交叉注意力计算【关键操作】
Token-Segment Cross-Attention
这这一层,每个ei都会通过交叉注意进行更新。
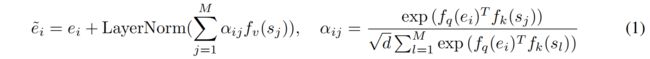
↑ 上图中的fk、fq、fv分别是query(查询)、key(键)、value(值)的线性映射。
(公式1只是为了明确概念,说明了一个注意力头的状况)
(采用多头注意力机制)
通过交叉注意力计算,将全局上下文信息注入到自底向上推理出来的表征向量 ei 当中(bottom-up-inferred token representations)生成具有全文感知的表征向量 ~ei ,
紧接着由解码器生成摘要。
为了实例化自顶向下的推理方法(Top-Down Inference),作者表示need to make two choices:
- the number of top-levels above the token level.
- the unit representation for each top-level.
↑解释↑:需要选择一个 top level,使得模型能应用full self-attention,一般的选择有句子、段落、章节,如何选?这取决于上面choice 1. 中提到的number。
但是,变长很麻烦(导致实现非常复杂以及有不可伸缩性),作者决定偷懒,使用一个简单粗暴的方法,top level 由固定长度的文档组成。【补充说明,top level不同粒度,实现结果也不同】
作者在这部分最后提到,
Top-Down Inference 在段级别(segment-level)的自注意力计算复杂度为 O(M^2),
标记-段(token-segment)的交叉注意力计算复杂度为 O(NM)
因此,整体的计算复杂度为 O ( Nw + M^2 + NM )
M是段数;w是窗口大小,作者表示在实践中采用较小的 w 和 M
池化层(Pool Methods)
(小结)如前所述,作者在当前的工作中使用了一个单一的顶层,由固定长度的段组成。
段表示(segment representations)通过池化标记表示( pooling token representations)进行初始化,承接前文中使用到的符号,假设一个分为 M 段的文档,第 j 段的嵌入初始化如下所示↓
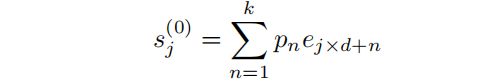
其中 k 是核大小(kernel size),d 是步幅(stride),pn 是第n个 token 的权重。下面是两种计算pn的方法。
平均池化(AvgPool):pn = 1/k (简单方便,结果不理想)
自适应权重(AdaPool)— 引用摘要来定义每个 token 的重要性来分配自适应权重。【为此作者学习了一个用参考摘要构建的标签的重要性标记器,3个步骤↓】
1.为重要性标记的训练标签:(1)文档和参考词的词化( word lemmatization)(2)如果文档单词出现在引用单词列表中并且不停止,则将其标记为重要;
2.训练一个 top-down 的transformer encoder(编码器)与构造的标签作为重要性标记;
3.使用Oracle权重训练摘要模型(即步骤1中构建的标签),并用学习标记器分配的自适应重要性权重进行测试。
作者在实验中还使用了OracleAdaPool,其中的权重是从步骤1和参考摘要中获得的。
如果 pn,当 n = 1…k 时, pn = 1 ,意味着没有形成有效的概率分布;
sj 可以在每个池窗口内的标准化权值分布计算。
然后这个 sj(0) 可以通过自注意力进行更新,然后被用于后续自顶向下的计算中。

实验
【自己去看】
【不过2022年4月13日,在paperwithcode中摘要任务,对arxiv数据集,SOTA级别,Rouge 得分 > 50 (首次)】