《动手学》-单机多卡、分布式,batch_size和learning rate的设置说明
目录
- 1.理论
- 2.代码
-
- 2.1从零自己实现
- 2.2 调用api简洁实现
- 3.QA
- 分布式
- 【重点】
1.理论



4是绿线,5是橙线。这里key-value假设是内存。
注意这里batch_size是在每个

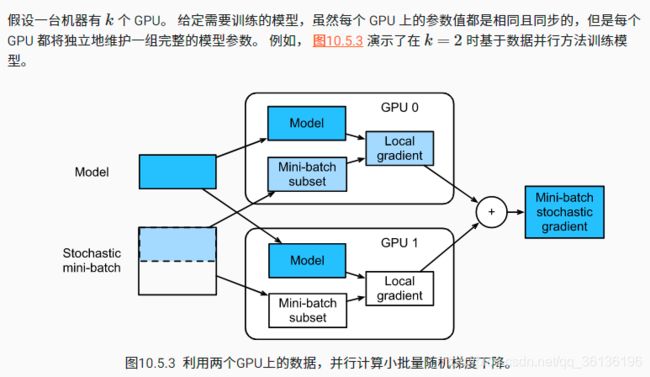

解释:可以显著地增大batch_size,同时也可相应地提高学习率。
2.代码
2.1从零自己实现
%matplotlib inline
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
# 初始化模型参数
scale = 0.01
W1 = torch.randn(size=(20, 1, 3, 3)) * scale
b1 = torch.zeros(20)
W2 = torch.randn(size=(50, 20, 5, 5)) * scale
b2 = torch.zeros(50)
W3 = torch.randn(size=(800, 128)) * scale
b3 = torch.zeros(128)
W4 = torch.randn(size=(128, 10)) * scale
b4 = torch.zeros(10)
params = [W1, b1, W2, b2, W3, b3, W4, b4]
# 定义模型
def lenet(X, params):
h1_conv = F.conv2d(input=X, weight=params[0], bias=params[1])
h1_activation = F.relu(h1_conv)
h1 = F.avg_pool2d(input=h1_activation, kernel_size=(2, 2), stride=(2, 2))
h2_conv = F.conv2d(input=h1, weight=params[2], bias=params[3])
h2_activation = F.relu(h2_conv)
h2 = F.avg_pool2d(input=h2_activation, kernel_size=(2, 2), stride=(2, 2))
h2 = h2.reshape(h2.shape[0], -1)
h3_linear = torch.mm(h2, params[4]) + params[5]
h3 = F.relu(h3_linear)
y_hat = torch.mm(h3, params[6]) + params[7]
return y_hat
# 交叉熵损失函数
loss = nn.CrossEntropyLoss(reduction='none')
数据同步
def get_params(params, device):
new_params = [p.clone().to(device) for p in params]
for p in new_params:
p.requires_grad_()
return new_params
new_params = get_params(params, d2l.try_gpu(0))
print('b1 weight:', new_params[1])
print('b1 grad:', new_params[1].grad)
def allreduce(data):
for i in range(1, len(data)):
data[0][:] += data[i].to(data[0].device)
for i in range(1, len(data)):
data[i] = data[0].to(data[i].device)
data = [torch.ones((1, 2), device=d2l.try_gpu(i)) * (i + 1) for i in range(2)]
print('before allreduce:\n', data[0], '\n', data[1])
allreduce(data)
print('after allreduce:\n', data[0], '\n', data[1])
数据分发
data = torch.arange(20).reshape(4, 5)
devices = [torch.device('cuda:0'), torch.device('cuda:1')]
split = nn.parallel.scatter(data, devices)
print('input :', data)
print('load into', devices)
print('output:', split)
#@save
def split_batch(X, y, devices):
"""将`X`和`y`拆分到多个设备上"""
assert X.shape[0] == y.shape[0]
return (nn.parallel.scatter(X, devices), nn.parallel.scatter(y, devices))
训练
def train_batch(X, y, device_params, devices, lr):
X_shards, y_shards = split_batch(X, y, devices)
# 在每个GPU上分别计算损失
ls = [
loss(lenet(X_shard, device_W),
y_shard).sum() for X_shard, y_shard, device_W in zip(
X_shards, y_shards, device_params)]
for l in ls: # 反向传播在每个GPU上分别执行
l.backward()
# 将每个GPU的所有梯度相加,并将其广播到所有GPU
with torch.no_grad():
for i in range(len(device_params[0])):
allreduce([device_params[c][i].grad for c in range(len(devices))])
# 在每个GPU上分别更新模型参数,因为放到某一个gpu上做,和放到各个gpu上做,效果都一样
for param in device_params:
d2l.sgd(param, lr, X.shape[0]) # 在这里,我们使用全尺寸的小批量
def train(num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
# 将模型参数复制到`num_gpus`个GPU
device_params = [get_params(params, d) for d in devices]
num_epochs = 10
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
timer = d2l.Timer()
for epoch in range(num_epochs):
timer.start()
for X, y in train_iter:
# 为单个小批量执行多GPU训练
train_batch(X, y, device_params, devices, lr)
torch.cuda.synchronize()
timer.stop()
# 在GPU 0上评估模型
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(
lambda x: lenet(x, device_params[0]), test_iter, devices[0]),))
print(f'test acc: {animator.Y[0][-1]:.2f}, {timer.avg():.1f} sec/epoch '
f'on {str(devices)}')
train(num_gpus=1, batch_size=256, lr=0.2)
train(num_gpus=2, batch_size=256, lr=0.2)
2.2 调用api简洁实现
import torch
from torch import nn
from d2l import torch as d2l
#@save
def resnet18(num_classes, in_channels=1):
"""稍加修改的 ResNet-18 模型。"""
def resnet_block(in_channels, out_channels, num_residuals,
first_block=False):
blk = []
for i in range(num_residuals):
if i == 0 and not first_block:
blk.append(
d2l.Residual(in_channels, out_channels, use_1x1conv=True,
strides=2))
else:
blk.append(d2l.Residual(out_channels, out_channels))
return nn.Sequential(*blk)
# 该模型使用了更小的卷积核、步长和填充,而且删除了最大池化层。
net = nn.Sequential(
nn.Conv2d(in_channels, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64), nn.ReLU())
net.add_module("resnet_block1", resnet_block(64, 64, 2, first_block=True))
net.add_module("resnet_block2", resnet_block(64, 128, 2))
net.add_module("resnet_block3", resnet_block(128, 256, 2))
net.add_module("resnet_block4", resnet_block(256, 512, 2))
net.add_module("global_avg_pool", nn.AdaptiveAvgPool2d((1, 1)))
net.add_module("fc",
nn.Sequential(nn.Flatten(), nn.Linear(512, num_classes)))
return net
net = resnet18(10)
# 获取GPU列表
devices = d2l.try_all_gpus()
# 我们将在训练代码实现中初始化网络
def train(net, num_gpus, batch_size, lr):
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
devices = [d2l.try_gpu(i) for i in range(num_gpus)]
def init_weights(m):
if type(m) in [nn.Linear, nn.Conv2d]:
nn.init.normal_(m.weight, std=0.01)
net.apply(init_weights)
#不加这行代码可能会报错,先把模型放到gpu0上再做
net.to(devices[0])
# 在多个 GPU 上设置模型
net = nn.DataParallel(net, device_ids=devices)
trainer = torch.optim.SGD(net.parameters(), lr)
loss = nn.CrossEntropyLoss()
timer, num_epochs = d2l.Timer(), 10
animator = d2l.Animator('epoch', 'test acc', xlim=[1, num_epochs])
for epoch in range(num_epochs):
net.train()
timer.start()
#以下都会通过nn.DataParallel进行数据同步,数据分发操作
for X, y in train_iter:
trainer.zero_grad()
X, y = X.to(devices[0]), y.to(devices[0])
l = loss(net(X), y)
l.backward()
trainer.step()
timer.stop()
animator.add(epoch + 1, (d2l.evaluate_accuracy_gpu(net, test_iter),))
print(f'test acc: {animator.Y[0][-1]:.2f}, {timer.avg():.1f} sec/epoch '
f'on {str(devices)}')
train(net, num_gpus=1, batch_size=256, lr=0.1)
train(net, num_gpus=2, batch_size=512, lr=0.2)
3.QA
- Q:小批量分到多GPU计算后,模型结果怎么合到一起?
梯度加起来后,模型只有一份,只在一个地方被更新。模型参数保证是一致的 - 每个GPU保存模型参数和梯度,因此,样本数会变少,常把batch_size调成gpu数的倍数
- 默认是将模型参数放到cpu的内存上,需要先挪到GPU
- 数据读入的时间是一定的,即使多GPU并行,这个时间也不会少,通信时间占比较大
- 数据多样性不够的时候,无法用大的batch_size的,因为里边会有很多相似的数据,算是无效数据
- learning rate可以稍微大一点,前期的抖动不影响后边的精度。
- Q:两个GPU训练时,最后的梯度是把两个GPU上的梯度相加吗?A:是的,因为mini-batch计算,就是多个样本的梯度求和的结果。
- Q:验证集上准确率震荡较大,主要是lr影响较大。
分布式
通过网络去传输数据,性能瓶颈在网络传输上。
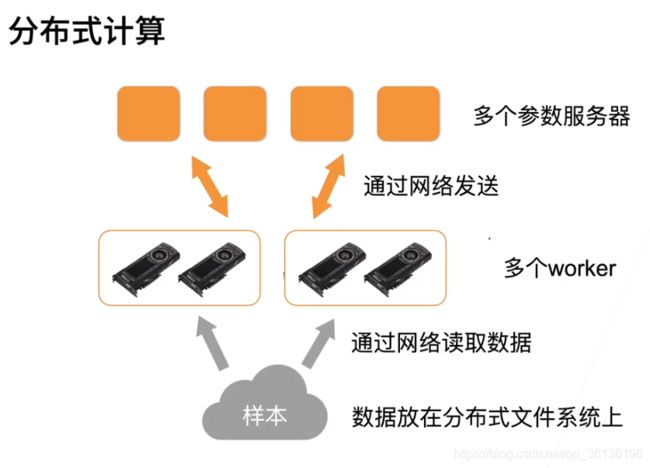
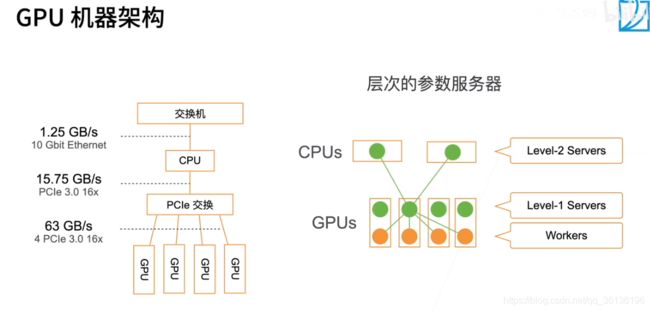
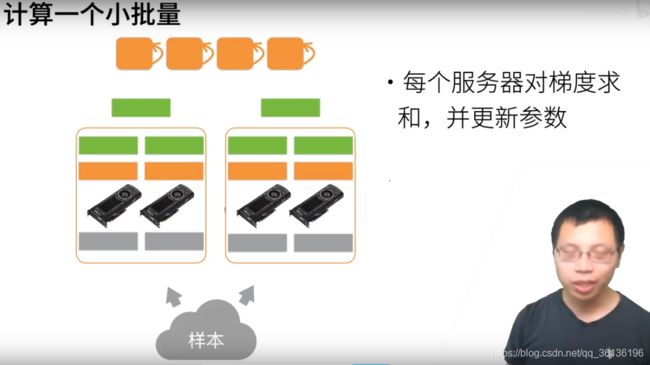


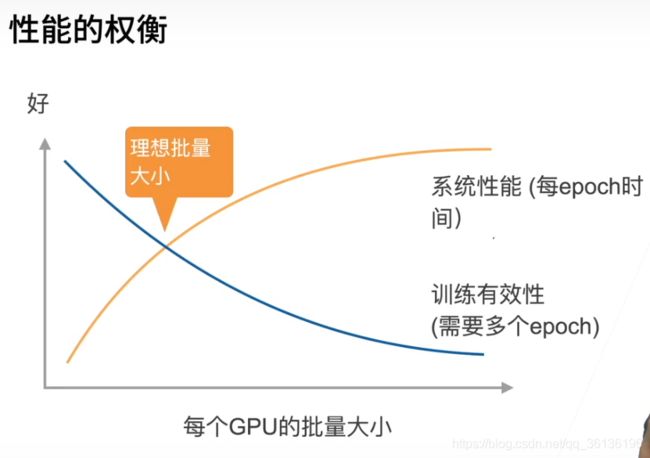

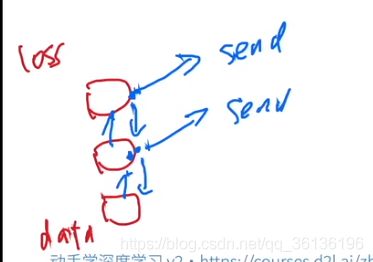
【重点】
Q:batch_size越大,训练的有效性曲线是下降的?
A:极端情况,数据集就一个样本,复制了一万份。batch_size不管多大都是一样的,每个样本的梯度都是一样的,假设需要到某一个accuracy的话,如果batch_size为1,需要10个epoch才能到达,那么,即使batch_size为10,仍然需要10个epoch才能到达,而后者计算的数量是前者的10倍。所以,还是需要看数据集的多样性。