从鹅厂实例出发!分析Go Channel底层原理

本文是基于Go1.18.1源码的学习笔记。Channel的底层源码从Go1.14到现在的Go1.19之间几乎没有变化,这也是Go最早引入的组件之一,体现了Go并发思想:
Do not communicate by sharing memory; instead, share memory by communicating.不要通过共享内存来通信,⽽应通过通信来共享内存。
 结论
结论
还是先给出结论,没时间看分析过程的同学至少可以看一眼结论:
1. Channel本质上是由三个FIFO(First In FirstOut,先进先出)队列组成的用于协程之间传输数据的协程安全的通道;FIFO的设计是为了保障公平,让事情变得简单,原则是让等待时间最长的协程最有资格先从channel发送或接收数据;
2. 三个FIFO队列依次是buf循环队列,sendq待发送者队列,recvq待接收者队列。buf循环队列是大小固定的用来存放channel接收的数据的队列;sendq待发送者队列,用来存放等待发送数据到channel的goroutine的双向链表,recvq待接收者队列,用来存放等待从channel读取数据的goroutine的双向链表;sendq和recvq可以认为不限大小;
3. 跟函数调用传参本质都是传值一样,channel传递数据的本质就是值拷贝,引用类型数据的传递也是地址拷贝;有从缓冲区buf地址拷贝数据到接收者receiver栈内存地址,也有从发送者sender栈内存地址拷贝数据到缓冲区buf;
4. Channel里面参数的修改不是并发安全的,包括对三个队列及其他参数的访问,因此需要加锁,本质上,channel就是一个有锁队列;
5. Channel 的性能跟 sync.Mutex 差不多,没有谁比谁强。Go官方之所以推荐使用Channel进行并发协程的数据交互,是因为channel的设计理念能让程序变得简单,在大型程序、高并发复杂的运行状况中也是如此。

从一个线上的内存泄漏问题谈起
去年底,团队有个线上服务发生了一个故障,该服务部署在K8S集群的容器里,通过Prometheus监控界面看到本服务的Pod的内存使用量呈锯齿状增长,达到服务设置的内存上限16G后,就会发生容器重启,看现象是发生了内存泄漏。
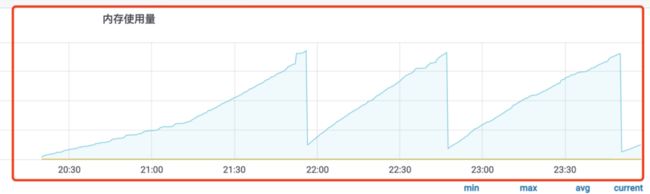
线上服务的代码经过简化,基本逻辑如下:
package main
import (
"errors"
"fmt"
)
func accessMultiService() (data string, err error) {
respAChan := make(chan string) //无缓冲channel
go func() {
serviceAResp, _ := accessServiceA()
respAChan <- serviceAResp
}()
_, serviceBErr := accessServiceB()
if serviceBErr != nil {
return "", errors.New("service B response error")
}
_, serviceCErr := accessServiceC()
if serviceCErr != nil {
return "", errors.New("service C response error")
}
respA := <- respAChan
fmt.Printf("service A resp is: %s\n", respA)
return "success", nil
}
func accessServiceA() (string, error) {
return "service A result", nil
}
func accessServiceB() (string, error) {
return "service B result", errors.New("service B error")
}
func accessServiceC() (string, error) {
return "service C result", nil
}经过排查,是在起的一个goroutine访问 A 服务时,使用了一个无缓冲的channel respAChan,在后续的访问服务B,C时,发生了异常导致父协程返回,A服务的子协程里的无缓冲channel respAChan一直没有goroutine去读它,导致它一直被阻塞,无法被释放,随着请求数的增多,它所在的goroutine会一直占用内存,直到达到容器内存上限,使容器崩溃重启。
解决办法可以是:将无缓冲的channel改成有缓冲channel,并且在写入数据后关闭它,这样就不会发生goroutine一直阻塞,无法被释放的问题了。
respAChan := make(chan string, 1) //改为有缓冲channel
go func() {
serviceAResp, _ := accessServiceA()
respAChan <- serviceAResp
close(respAChan) //写入后关闭channel
}()从这个问题可以知道尽管大家都用过channel,却也容易因使用不当而导致线上故障。
Channel是什么?怎么用?
首先是channel分为两类:
1.无缓冲channel,可以看作“同步模式”,发送方和接收方要同步就绪,只有在两者都 ready 的情况下,数据才能在两者间传输(后面会看到,实际上就是内存拷贝)。否则,任意一方先行进行发送或接收操作,都会被挂起,等待另一方的出现才能被唤醒。
2.有缓冲channel称为“异步模式”,在缓冲槽可用的情况下(有剩余容量),发送和接收操作都可以顺利进行。否则,操作的一方(如写入)同样会被挂起,直到出现相反操作 (如接收)才会被唤醒。
channel的基本用法有:
1.读取 <- chan
2.写入 chan <-
3.关闭 close(chan)
4.获取channel长度 len(chan)
5.获取channel容量 cap(chan)
还有一种select非阻塞访问方式,从所有的case中挑选一个不会阻塞的channel进行读写操作,或是default执行。

Channel设计思想
Go语言的并发模型是CSP(Communicating Sequential Processes,通信顺序进程),提倡通过通信共享内存而不是通过共享内存而实现通信。
如果说goroutine是Go程序并发的执行体,channel就是它们之间的连接。channel是可以让一个goroutine发送特定值到另一个goroutine的通信机制。
下面有关并发讨论中的线程可以替换为进程、协程或函数,本质上都是同时对同一份数据的竞争。
先弄清楚并发和并行的区别:多线程程序在一个核的CPU上运行,就是并发。多线程程序在多个核的CPU上运行,就是并行。
单纯地将线程并发执行是没有意义的。线程与线程间需要交换数据才能体现并发执行线程的意义。
多个线程之间交换数据无非是两种方式:共享内存加互斥锁;先进先出(FIFO)将资源分配给等待时间最长的线程。
共享内存加互斥锁是C++等其他语言采用的并发线程交换数据的方式,在高并发的场景下有时候难以正确的使用,特别是在超大型、巨型的程序中,容易带来难以察觉的隐藏的问题。Go语言采用的是后者,引入channel以先进先出(FIFO)将资源分配给等待时间最长的goroutine,尽量消除数据竞争,让程序以尽可能顺序一致的方式运行。
关于理解让程序尽量顺序一致的含义,可以看看Go语言内存模型采用的一个传统的基于happens-before对读写竞争的定义:
1.修改由多个goroutines同时访问的数据的程序必须串行化这些访问。
2.为了实现串行访问, 需要使用channel操作或其他同步原语(如sync和sync/atomic包中的原语)来保护数据。
3.go语句创建一个goroutine,一定发生在goroutine执行之前。
4.往一个channel中发送数据,一定发生在从这个channel 读取这个数据完成之前。
5.一个channel的关闭,一定发生在从这个channel读取到零值数据(这里指因为close而返回的零值数据)之前。
6.从一个无缓冲channel的读取数据,一定发生在往这个channel发送数据完成之前。
如果违反了这种定义,Go会让程序直接panic或阻塞,无法往后执行。
有人说,Go没有采用共享内存加互斥锁进行协程之间的通信,是因为这种方式性能太差,其实不是,因为channel本质也是一个有锁的队列,采用channel进行协程之间的通信,主要是为了减少数据竞争,在大型程序、高并发的复杂场景下,以简单的原理实现的组件,更能让程序尽量按符合预期的、不易出错的方式执行。
Go 中用于并发协程同步数据的组件主要分为 2 大类,一个是 sync 和sync/atomic包里面的,如sync.Mutex、sync.RWMutex、sync.WaitGroup等,另一个是 channel。只有channel才是Go语言推荐的并发同步的方式,是一等公民,用户使用channel甚至不需要引入包名。

Channel结构
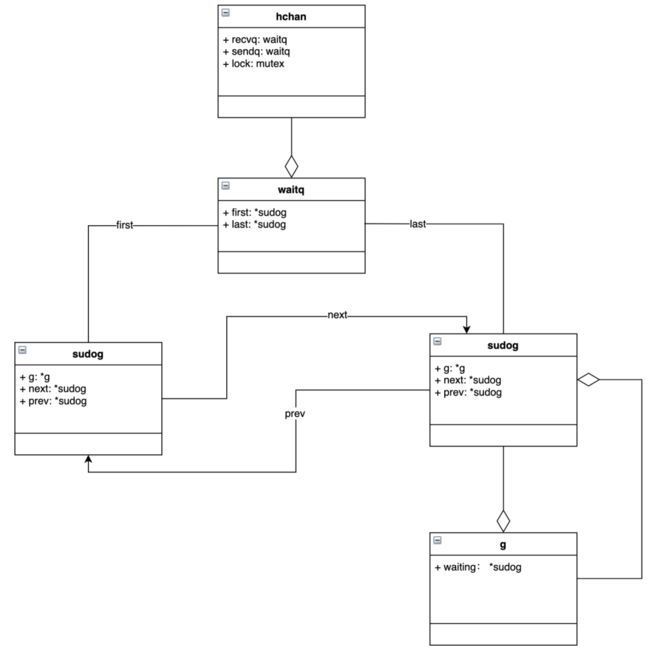
channel的底层数据结构是hchan,在src/runtime/chan.go 中。
type hchan struct {
qcount uint // 队列中所有数据总数
dataqsiz uint // 循环队列大小
buf unsafe.Pointer // 指向循环队列的指针
elemsize uint16 // 循环队列中元素的大小
closed uint32 // chan是否关闭的标识
elemtype *_type // 循环队列中元素的类型
sendx uint // 已发送元素在循环队列中的位置
recvx uint // 已接收元素在循环队列中的位置
recvq waitq // 等待接收的goroutine的等待队列
sendq waitq // 等待发送的goroutine的等待队列
lock mutex // 控制chan并发访问的互斥锁
}qcount代表chan中已经接收但还没被读取的元素的个数;
dataqsiz代表循环队列的大小;
buf 是指向循环队列的指针,循环队列是大小固定的用来存放chan接收的数据的队列;
elemtype 和 elemsiz 表示循环队列中元素的类型和元素的大小;
sendx:待发送的数据在循环队列buffer中的位置索引;
recvx:待接收的数据在循环队列buffer中的位置索引;
recvq 和 sendq 分别表示等待接收数据的 goroutine 与等待发送数据的 goroutine;
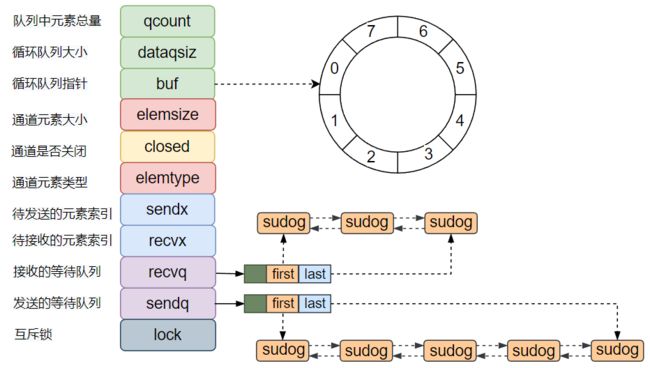
sendq 和 recvq 存储了当前 Channel 由于缓冲区空间不足而阻塞的 Goroutine 列表,这些等待队列使用双向链表 waitq 表示,链表中所有的元素都是 sudog 结构:
type waitq struct {
first *sudog
last *sudog
}sudog代表着等待队列中的一个goroutine,G与同步对象(指chan)关系是多对多的。一个 G 可以出现在许多等待队列上,因此一个 G 可能有多个sudog。并且多个 G 可能正在等待同一个同步对象,因此一个对象可能有许多 sudog。sudog 是从特殊池中分配出来的。使用 acquireSudog 和 releaseSudog 分配和释放它们。

创建Chan
Channel的创建会使用make关键字:
ch := make(chan int, 10)编译器编译上述代码,在检查ir节点时,根据节点op不同类型,进行不同的检查,源码如下:
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
......
case ir.OMAKECHAN:
n := n.(*ir.MakeExpr)
return walkMakeChan(n, init)
......
}编译器会将 make(chan int, 10) 表达式转换成 OMAKE 类型的节点,并在类型检查阶段将 OMAKE 类型的节点转换成 OMAKECHAN 类型,该类型节点会调用walkMakeChan函数处理:
func walkMakeChan(n *ir.MakeExpr, init *ir.Nodes) ir.Node {
size := n.Len
fnname := "makechan64"
argtype := types.Types[types.TINT64]
if size.Type().IsKind(types.TIDEAL) || size.Type().Size() <= types.Types[types.TUINT].Size() {
fnname = "makechan"
argtype = types.Types[types.TINT]
}
return mkcall1(chanfn(fnname, 1, n.Type()), n.Type(), init, reflectdata.TypePtr(n.Type()), typecheck.Conv(size, argtype))
}上述代码默认调用makechan64()函数。如果在make函数中传入的 channel size 大小在 int 范围内,推荐使用 makechan()。因为 makechan() 在 32 位的平台上更快,用的内存更少。
makechan64() 方法在src/runtime/chan.go,只是判断一下传入的入参 size 是否还在 int 范围之内:
func makechan64(t *chantype, size int64) *hchan {
if int64(int(size)) != size {
panic(plainError("makechan: size out of range"))
}
return makechan(t, int(size))
}最终创建 channel 调用的还是runtime.makechan() 函数:
func makechan(t *chantype, size int) *hchan {
elem := t.elem
// 检查数据项大小不能超过 64KB
if elem.size >= 1<<16 {
throw("makechan: invalid channel element type")
}
// 检查内存对齐是否正确
if hchanSize%maxAlign != 0 || elem.align > maxAlign {
throw("makechan: bad alignment")
}
// 缓冲区大小检查,判断是否溢出
mem, overflow := math.MulUintptr(elem.size, uintptr(size))
if overflow || mem > maxAlloc-hchanSize || size < 0 {
panic(plainError("makechan: size out of range"))
}
var c *hchan
switch {
case mem == 0:
// 队列或者元素大小为 zero 时,无须创建buf环形队列.
c = (*hchan)(mallocgc(hchanSize, nil, true))
// 竞态检查,利用这个地址进行同步操作.
c.buf = c.raceaddr()
case elem.ptrdata == 0:
// 元素不是指针,分配一块连续的内存给hchan数据结构和缓冲区buf
c = (*hchan)(mallocgc(hchanSize+mem, nil, true))
// 表示hchan后面在内存里紧跟着就是buf环形队列
c.buf = add(unsafe.Pointer(c), hchanSize)
default:
// 元素包含指针,单独分配环形队列buf
c = new(hchan)
c.buf = mallocgc(mem, elem, true)
}
// 设置元素个数、元素类型给创建的chan
c.elemsize = uint16(elem.size)
c.elemtype = elem
c.dataqsiz = uint(size)
lockInit(&c.lock, lockRankHchan)
if debugChan {
print("makechan: chan=", c, "; elemsize=", elem.size, "; dataqsiz=", size, "\n")
}
return c
}上面这段 makechan() 代码主要目的是生成 *hchan 对象。重点关注 switch-case 中的 3 种情况:
1.当队列或者元素大小为 0 时,调用 mallocgc() 在堆上为 channel 开辟一段大小为 hchanSize 的内存空间;
2.当元素类型不是指针类型时,调用 mallocgc() 在堆上为 channel 和底层 buf 缓冲区数组开辟一段大小为 hchanSize + mem 连续的内存空间;
3.默认情况元素类型中有指针类型,调用 mallocgc() 在堆上分别为 channel 和 buf 缓冲区分配内存。
这里需要解释下:当存储在 buf 中的元素不包含指针时,hchan 中也不包含 GC 关心的指针。buf 指向一段相同元素类型的内存,elemtype 固定不变。受到垃圾回收器的限制,指针类型的缓冲 buf 需要单独分配内存。
channel本身是引用类型,其创建全部调用的是 mallocgc(),在堆上开辟的内存空间,说明 channel 本身会被 GC 自动回收。

发送数据
向 channel 中发送数据使用 ch <- 1 代码,编译器在编译它时,会把它解析成OSEND节点:
func walkExpr1(n ir.Node, init *ir.Nodes) ir.Node {
switch n.Op() {
......
case ir.OSEND:
n := n.(*ir.SendStmt)
return walkSend(n, init)
......
}对OSEND节点会调用 walkSend()函数处理:
func walkSend(n *ir.SendStmt, init *ir.Nodes) ir.Node {
n1 := n.Value
n1 = typecheck.AssignConv(n1, n.Chan.Type().Elem(), "chan send")
n1 = walkExpr(n1, init)
n1 = typecheck.NodAddr(n1)
return mkcall1(chanfn("chansend1", 2, n.Chan.Type()), nil, init, n.Chan, n1)
}运行时的chansend1()函数实际调用的是chansend():
func chansend1(c *hchan, elem unsafe.Pointer) {
chansend(c, elem, true, getcallerpc())
}chansend()函数的主要逻辑是:
1.在chan为 nil 未初始化的情况下,对于select这种非阻塞的发送,直接返回 false;对于阻塞的发送,将 goroutine 挂起,并且永远不会返回。
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
// 如果chan为nil
if c == nil {
// 对于select这种非阻塞的发送,直接返回
if !block {
return false
}
// 对于阻塞的通道,将 goroutine 挂起
gopark(nil, nil, waitReasonChanSendNilChan, traceEvGoStop, 2)
throw("unreachable")
}
......
}2.非阻塞发送的情况下,当 channel 不为 nil,并且 channel 没有关闭时,如果没有缓冲区且没有接收者receiver,或者缓冲区已经满了,返回 false。
if !block && c.closed == 0 && full(c) {
return false
}full() 方法作用是判断在 channel 上发送是否会阻塞,用来判断的参数是qcount,c.recvq.first,dataqsiz,前两个变量都是单字长的,所以对它们单个值的读操作是原子性的。dataqsiz字段,它在创建完 channel 以后是不可变的,因此它可以安全的在任意时刻读取。
func full(c *hchan) bool {
// 如果循环队列大小为0
if c.dataqsiz == 0 {
// 假设指针读取是近似原子性的,这里用来判断没有接收者
return c.recvq.first == nil
}
// 队列满了
return c.qcount == c.dataqsiz
}3.接下来,对chan加锁,判断chan不是关闭状态,再从recvq队列中取出一个接收者,如果接收者存在,则直接向它发送消息,绕过循环队列buf,此时,由于有接收者存在,则循环队列buf一定是空的。
......
// 对chan加锁
lock(&c.lock)
// 检查chan是否关闭
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("send on closed channel"))
}
// 从 recvq 中取出一个接收者
if sg := c.recvq.dequeue(); sg != nil {
// 如果接收者存在,直接向该接收者发送数据,绕过循环队列buf
send(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true
}
......send() 函数主要完成了 2 件事:调用 sendDirect() 函数将数据拷贝到了接收者的内存地址上;调用 goready() 将等待接收的阻塞 goroutine 的状态从 Gwaiting 或者 Gscanwaiting 改变成 Grunnable。
func send(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
......
if sg.elem != nil {
// 直接把要发送的数据拷贝到receiver的内存地址
sendDirect(c.elemtype, sg, ep)
sg.elem = nil
}
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 唤醒等待的接收者goroutine
goready(gp, skip+1)
}4.回到chansend()方法,接下来是有缓冲区的异步发送的逻辑。
// 如果缓冲区没有满,直接将要发送的数据复制到缓冲区
if c.qcount < c.dataqsiz {
// 找到要发送数据到循环队列buf的索引位置
qp := chanbuf(c, c.sendx)
......
// 数据拷贝到循环队列中
typedmemmove(c.elemtype, qp, ep)
// 将待发送数据索引加1,由于是循环队列,如果到了末尾,从0开始
c.sendx++
if c.sendx == c.dataqsiz {
c.sendx = 0
}
// chan中元素个数加1,释放锁返回true
c.qcount++
unlock(&c.lock)
return true
}如果缓冲区buf还没有满,调用 chanbuf() 获取 sendx 索引的元素指针值。调用 typedmemmove() 方法将发送的值拷贝到缓冲区 buf 中。拷贝完成,增加 sendx 索引下标值和 qcount 个数。
5.如果执行前面的步骤还没有成功发送,就表示缓冲区没有空间了,而且也没有任何接收者在等待。后面需要将 goroutine 挂起然后等待新的接收者了。
// 缓冲区没有空间,对于select这种非阻塞调用直接返回false
if !block {
unlock(&c.lock)
return false
}
// 下面的逻辑是将当前goroutine挂起
// 调用 getg()方法获取当前goroutine的指针,用于绑定给一个 sudog
gp := getg()
// 调用 acquireSudog()方法获取一个 sudog,可能是新建的 sudog,也有可能是从缓存中获取的。设置好sudog要发送的数据和状态。比如发送的 Channel、是否在 select 中和待发送数据的内存地址等等。
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.waiting = mysg
gp.param = nil
// 调用 c.sendq.enqueue 方法将配置好的 sudog 加入待发送的等待队列
c.sendq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
// 调用gopark方法挂起当前goroutine,状态为waitReasonChanSend,阻塞等待channel接收者的激活
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanSend, traceEvGoBlockSend, 2)
// 最后,KeepAlive() 确保发送的值保持活动状态,直到接收者将其复制出来
KeepAlive(ep)6.chansend()方法最后的代码是当goroutine唤醒以后,解除阻塞的状态。
func chansend(c *hchan, ep unsafe.Pointer, block bool, callerpc uintptr) bool {
......
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
closed := !mysg.success
gp.param = nil
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
mysg.c = nil
releaseSudog(mysg)
if closed {
if c.closed == 0 {
throw("chansend: spurious wakeup")
}
panic(plainError("send on closed channel"))
}
return true
}综上所述:
1.首先select这种非阻塞的发送,判断两种情况;
2.然后是一般的阻塞调用,先判断recvq等待接收队列是否为空,不为空说明缓冲区中没有内容或者是一个无缓冲channel;
3.如果recvq有接收者,则缓冲区一定为空,直接从recvq中取出一个goroutine,然后写入数据,接着唤醒 goroutine,结束发送过程;
4.如果缓冲区有空余的位置,写入数据到缓冲区,完成发送;
5.如果缓冲区满了,那么就把发送数据的goroutine放到sendq中,进入睡眠,等待该goroutine被唤醒。

接收数据
从channel中接收数据的代码是:
i <- ch
i, ok <- ch经过编译器的处理,会解析成ORECV节点,后者会在类型检查阶段被转换成 OAS2RECV 类型。最终,这两种不同的 channel 接收方式会转换成 runtime.chanrecv1 和 runtime.chanrecv2 两种不同函数的调用,但是最终核心逻辑还是在 runtime.chanrecv 中。
下面直接看chanrecv()方法的逻辑:
1.chanrecv()方法有两个返回值,selected, received bool,前者表示是否接收到值,后者表示接收的值是否关闭后发送的。有三种情况:如果是非阻塞的情况,没有数据可以接收,则返回 (false,flase);如果 chan 已经关闭了,将 ep 指向的值置为 0值,并且返回 (true, false);其它情况返回值为 (true,true),表示成功从 chan 中获取到了数据,且是chan未关闭发送。
// If block == false and no elements are available, returns (false, false).
// Otherwise, if c is closed, zeros *ep and returns (true, false).
// Otherwise, fills in *ep with an element and returns (true, true).
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
}2.首先判断如果chan为空,且是select这种非阻塞调用,那么直接返回 (false,false),否则阻塞当前的goroutine。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
// 如果c为空
if c == nil {
// 如果c为空且是非阻塞调用,那么直接返回 (false,false)
if !block {
return
}
//阻塞当前的goroutine
gopark(nil, nil, waitReasonChanReceiveNilChan, traceEvGoStop, 2)
throw("unreachable")
}
......
}3.如果是非阻塞调用,通过empty()方法原子判断是无缓冲chan或者是chan中没有数据且chan没有关闭,则返回(false,false),如果chan关闭,为了防止检查期间的状态变化,二次调用empty()进行原子检查,如果是无缓冲chan或者是chan中没有数据,返回 (true, false),这里的第一个true表示chan关闭后读取的 0 值。
//非阻塞调用,通过empty()判断是无缓冲chan或者是chan中没有数据
if !block && empty(c) {
// 如果chan没有关闭,则直接返回 (false, false)
if atomic.Load(&c.closed) == 0 {
return
}
// 如果chan关闭, 为了防止检查期间的状态变化,二次调用empty()进行原子检查,如果是无缓冲chan或者是chan中没有数据,返回 (true, false)
if empty(c) {
if raceenabled {
raceacquire(c.raceaddr())
}
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
}func empty(c *hchan) bool {
// c.dataqsiz 是不可变的
if c.dataqsiz == 0 {
return atomic.Loadp(unsafe.Pointer(&c.sendq.first)) == nil
}
return atomic.Loaduint(&c.qcount) == 0
}4.接下来阻塞调用的逻辑,chanrecv方法对chan加锁,判断chan如果已经关闭,并且chan中没有数据,返回 (true,false),这里的第一个true表示chan关闭后读取的 0 值。
......
// 对chan加锁
lock(&c.lock)
// 如果已经关闭,并且chan中没有数据,返回 (true,false)
if c.closed != 0 && c.qcount == 0 {
if raceenabled {
raceacquire(c.raceaddr())
}
unlock(&c.lock)
if ep != nil {
typedmemclr(c.elemtype, ep)
}
return true, false
}
......5.接下来,从发送队列中获取一个等待发送的 goroutine,即取出等待队列队头的 goroutine。如果缓冲区的大小为 0,则直接从发送方接收值。否则,对应缓冲区满的情况,从队列的头部接收数据,发送者的值添加到队列的末尾(此时队列已满,因此两者都映射到缓冲区中的同一个下标)。这里需要注意,由于有发送者在等待,所以如果有缓冲区,那么缓冲区一定是满的。
......
// 从发送者队列获取等待发送的 goroutine
if sg := c.sendq.dequeue(); sg != nil {
//在 channel 的发送队列中找到了等待发送的 goroutine,取出队头等待的 goroutine。如果缓冲区的大小为 0,则直接从发送方接收值。否则,对应缓冲区满的情况,从队列的头部接收数据,发送者的值添加到队列的末尾(此时队列已满,因此两者都映射到缓冲区中的同一个下标)
recv(c, sg, ep, func() { unlock(&c.lock) }, 3)
return true, true
}func recv(c *hchan, sg *sudog, ep unsafe.Pointer, unlockf func(), skip int) {
if c.dataqsiz == 0 {
if raceenabled {
racesync(c, sg)
}
if ep != nil {
// 从发送者sender里面拷贝数据
recvDirect(c.elemtype, sg, ep)
}
} else {
// 队列是满的
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
racenotify(c, c.recvx, sg)
}
// 从缓冲区拷贝数据给接收者receiver
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
// 从发送者sender拷贝数据到缓冲区
typedmemmove(c.elemtype, qp, sg.elem)
c.recvx++
if c.recvx == c.dataqsiz {
c.recvx = 0
}
c.sendx = c.recvx // c.sendx = (c.sendx+1) % c.dataqsiz
}
sg.elem = nil
gp := sg.g
unlockf()
gp.param = unsafe.Pointer(sg)
sg.success = true
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
// 唤醒发送者
goready(gp, skip+1)
}recv()方法先判断chan是否无缓冲,如果是,则直接从发送者sender那里拷贝数据,如果有缓存区,由于有发送者,此时缓冲区的循环队列一定是满的,会先从缓冲区拷贝数据给接收者receiver,然后将发送者的数据拷贝到缓冲区,满足FIFO。最后,唤醒发送者的goroutine。
6.接下来,是异步接收逻辑,如果缓冲区有数据,直接从缓冲区接收数据,即将缓冲区recvx指向的数据复制到ep接收地址,并且将recvx加1。
......
// 如果缓冲区有数据
if c.qcount > 0 {
// 直接从缓冲区接收数据
qp := chanbuf(c, c.recvx)
if raceenabled {
racenotify(c, c.recvx, nil)
}
// 接收数据地址ep不为空,直接从缓冲区复制数据到ep
if ep != nil {
typedmemmove(c.elemtype, ep, qp)
}
typedmemclr(c.elemtype, qp)
// 待接收索引加1
c.recvx++
// 循环队列,如果到了末尾,从0开始
if c.recvx == c.dataqsiz {
c.recvx = 0
}
// 缓冲区数据减1
c.qcount--
unlock(&c.lock)
return true, true
}
......7.然后,是缓冲区没有数据的情况;如果是select这种非阻塞读取的情况,直接返回(false, false),表示获取不到数据;否则,会获取sudog绑定当前接收者goroutine,调用gopark()挂起当前接收者goroutine,等待chan的其他发送者唤醒。
......
// 如果是select非阻塞读取的情况,直接返回(false, false)
if !block {
unlock(&c.lock)
return false, false
}
// 没有发送者,挂起当前goroutine
// 获取当前 goroutine 的指针,用于绑定给一个 sudog
gp := getg()
// 调用 acquireSudog() 方法获取一个 sudog,可能是新建的 sudog,也有可能是从缓存中获取的。设置好 sudog 要发送的数据和状态
mysg := acquireSudog()
mysg.releasetime = 0
if t0 != 0 {
mysg.releasetime = -1
}
mysg.elem = ep
mysg.waitlink = nil
gp.waiting = mysg
mysg.g = gp
mysg.isSelect = false
mysg.c = c
gp.param = nil
// 将配置好的 sudog 加入待发送的等待队列
c.recvq.enqueue(mysg)
atomic.Store8(&gp.parkingOnChan, 1)
// 挂起当前 goroutine
gopark(chanparkcommit, unsafe.Pointer(&c.lock), waitReasonChanReceive, traceEvGoBlockRecv, 2)
......8.最后,当前goroutine被唤醒,完成chan数据的接收,之后进行参数检查,解除chan绑定,并释放sudog。
func chanrecv(c *hchan, ep unsafe.Pointer, block bool) (selected, received bool) {
......
// 当前goroutine被唤醒,完成chan数据的接收,之后进行参数检查,解除chan绑定,并释放sudog
if mysg != gp.waiting {
throw("G waiting list is corrupted")
}
gp.waiting = nil
gp.activeStackChans = false
if mysg.releasetime > 0 {
blockevent(mysg.releasetime-t0, 2)
}
success := mysg.success
gp.param = nil
mysg.c = nil
releaseSudog(mysg)
return true, success
}综上分析,从chan接收数据的流程如下:
1.也是先判断select这种非阻塞接收的两种情况(block为false);然后是加锁进行阻塞调用的逻辑;
2.同步接收:如果发送者队列sendq不为空,且没有缓存区,直接从sendq中取出一个goroutine,读取当前goroutine中的消息,唤醒goroutine, 结束读取的过程;
3.同步接收:如果发送者队列sendq不为空,说明缓冲区已经满了,移动recvx指针的位置,取出一个数据,同时在sendq中取出一个goroutine,拷贝里面的数据到buf中,结束当前读取;
4.异步接收:如果发送者队列sendq为空,且缓冲区有数据,直接在缓冲区取出数据,完成本次读取;
5.阻塞接收:如果发送者队列sendq为空,且缓冲区没有数据。将当前goroutine加入recvq,进入睡眠,等待被发送者goroutine唤醒。

关闭Chan
关闭chan的代码是close(ch),编译器会将其转为调用 runtime.closechan() 方法。
func closechan(c *hchan) {
// 如果chan为空,此时关闭它会panic
if c == nil {
panic(plainError("close of nil channel"))
}
// 加锁
lock(&c.lock)
// 如果chan已经关闭了,再次关闭它会panic
if c.closed != 0 {
unlock(&c.lock)
panic(plainError("close of closed channel"))
}
if raceenabled {
callerpc := getcallerpc()
racewritepc(c.raceaddr(), callerpc, abi.FuncPCABIInternal(closechan))
racerelease(c.raceaddr())
}
// 设置chan的closed状态为关闭
c.closed = 1
// 申明一个存放所有接收者和发送者goroutine的list
var glist gList
//获取recvq里的所有接收者
for {
sg := c.recvq.dequeue()
if sg == nil {
break
}
if sg.elem != nil {
typedmemclr(c.elemtype, sg.elem)
sg.elem = nil
}
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
// 放入队列glist中
glist.push(gp)
}
// 获取所有发送者
for {
sg := c.sendq.dequeue()
if sg == nil {
break
}
sg.elem = nil
if sg.releasetime != 0 {
sg.releasetime = cputicks()
}
gp := sg.g
gp.param = unsafe.Pointer(sg)
sg.success = false
if raceenabled {
raceacquireg(gp, c.raceaddr())
}
// 放入队列glist中
glist.push(gp)
}
unlock(&c.lock)
// 唤醒所有的glist中的goroutine
for !glist.empty() {
gp := glist.pop()
gp.schedlink = 0
goready(gp, 3)
}
}关闭chan的步骤是:
1.先检查异常情况,当 Channel 是一个 nil 空指针或者关闭一个已经关闭的 channel 时,Go 语言运行时都会直接 panic。
2.关闭的主要工作是释放所有的接收者和发送者:将所有的接收者 readers 的 sudog 等待队列(recvq)加入到待清除队列 glist 中。注意这里是先回收接收者,因为从一个关闭的 channel 中读数据,不会发生 panic,顶多读到一个默认零值。再回收发送者 senders,将发送者的等待队列 sendq 中的 sudog 放入待清除队列 glist 中。注意这里可能会产生 panic,因为往一个关闭的 channel 中发送数据,会产生 panic。
 总结
总结
Channel是基于有锁队列实现数据在不同协程之间传输的通道,数据传输的方式其实就是值传递,引用类型数据的传递是地址拷贝。
有别于通过共享内存加锁的方式在协程之间传输数据,通过channel传递数据,这些数据的所有权也可以在goroutine之间传输。当 goroutine 向 channel 发送值时,我们可以看到 goroutine 释放了一些值的所有权。当一个 goroutine 从一个 channel 接收到一个值时,可以看到 goroutine 获得了一些值的所有权。
channel常见的读写异常情况如下表所示:
| channel操作 | chan为nil | 关闭的chan | 非空、未关闭的chan |
| 读 <- chan | 阻塞 | 里面的内容读完了,之后获取到的是类型的零值 | 阻塞或正常读取数据。缓冲型 channel 为空或非缓冲型 channel 没有等待发送者时会阻塞 |
| 写 chan <- | 阻塞 | panic | 阻塞或正常写入数据。非缓冲型 channel 没有等待接收者或缓冲型 channel buf 满时会被阻塞 |
| 关闭 close(chan) | panic | panic | 关闭成功 |
粉丝福利,后台回复“参考资料”获得本篇作者推荐相关学习材料
腾讯工程师技术干货直达:
快收藏!最全GO语言实现设计模式【下】
如何成为优秀工程师之软技能篇
如何更好地使用Kafka?
一文带你深入了解HTTP
点击下方空白 ▼ 查看明日开发者黄历

summer
time
2022
/
07.23
![]()