深入浅出ConcurrentHashMap详解
文章目录
- 1、前言
- 2、什么是ConcurrentHashMap
- 3、Put 操作
- 4、Get 操作
- 5、高并发线程安全
- 6、JDK8 的改进
-
- 6.1 结构改变
- 6.2 HashEntry 改为 Node
- 6.3 Put 操作的变化
- 6.4 Get 操作的变化
- 6.5 总结
1、前言
学习本章之前,先学习:深入浅出HashMap详解(JDK7)
简单回顾一下 HashMap 的结构:
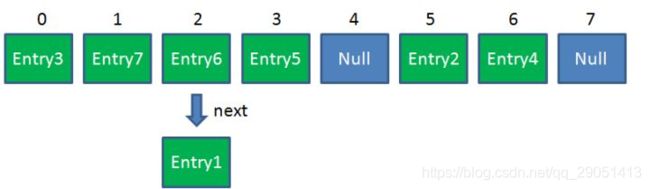
在 JDK7 下,高并发时,有可能出现下面的环形链表:
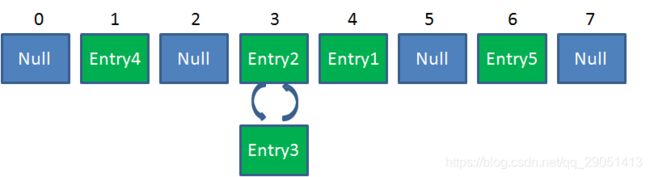
要避免 HashMap 的线程安全问题,有多个解决方法,比如改用 HashTable 或者 Collections.synchronizedMap() 方法。
但是这两者都有一个问题,就是性能,无论读还是写,他们两个都会给整个集合加锁,导致同一时间的其他操作阻塞。
ConcurrentHashMap 的优势在于兼顾性能和线程安全,一个线程进行写操作时,它会锁住一小部分,其他部分的读写不受影响,其他线程访问没上锁的地方不会被阻塞。
2、什么是ConcurrentHashMap
java.util.concurrent.ConcurrentHashMap属于 JUC 包下的一个集合类,可以实现线程安全。
它由多个 Segment 组合而成。Segment 本身就相当于一个 HashMap 对象。同 HashMap 一样,Segment 包含一个 HashEntry 数组,数组中的每一个 HashEntry 既是一个键值对,也是一个链表的头节点。
单一的 Segment 结构如下:
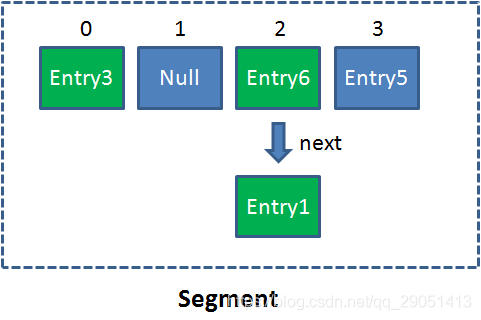
像这样的 Segment 对象,在 ConcurrentHashMap 集合中有多少个呢?有 2 的 N 次方个,共同保存在一个名为 segments 的数组当中。
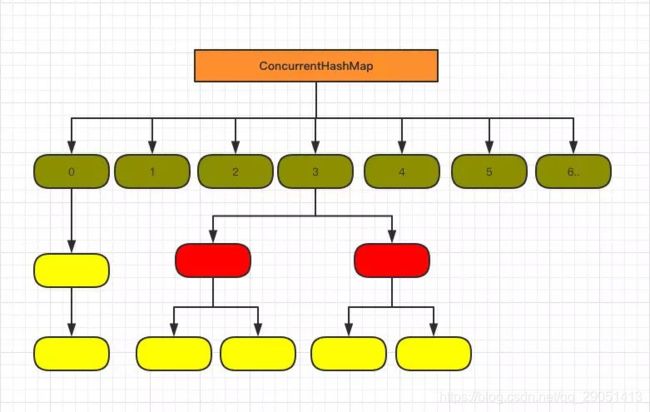
因此整个ConcurrentHashMap的结构如下:
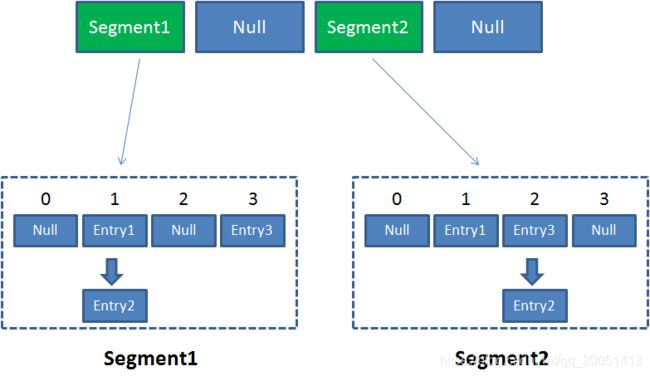
可以说,ConcurrentHashMap 是一个二级哈希表。在一个总的哈希表下面,有若干个子哈希表。
它的核心属性:
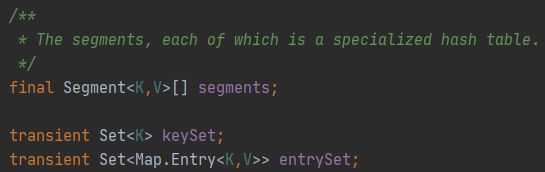
其中,Segment是它的一个内部类,主要组成如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// 和 HashMap 中的 HashEntry 作用一样,真正存放数据的桶
transient volatile HashEntry<K,V>[] table;
transient int count;
transient int modCount;
transient int threshold;
final float loadFactor;
// ...
}
HashEntry也是一个内部类,主要组成如下:
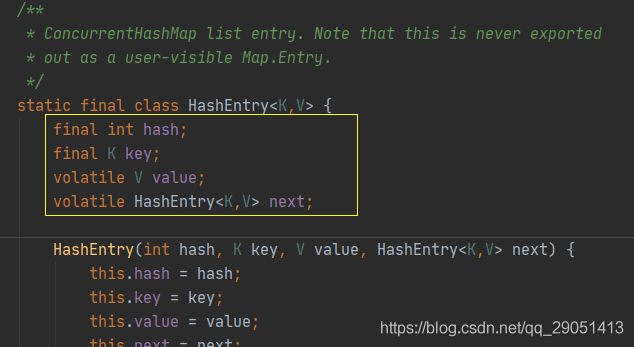
和 HashMap 的 Entry 基本一样,唯一的区别就是其中的核心数据如 value ,以及链表都是 volatile 修饰的,保证了获取时的可见性。
这里不介绍构造函数。
3、Put 操作
查看源码:

首先是通过 key 定位到 Segment,之后在对应的 Segment 中进行具体的 put。
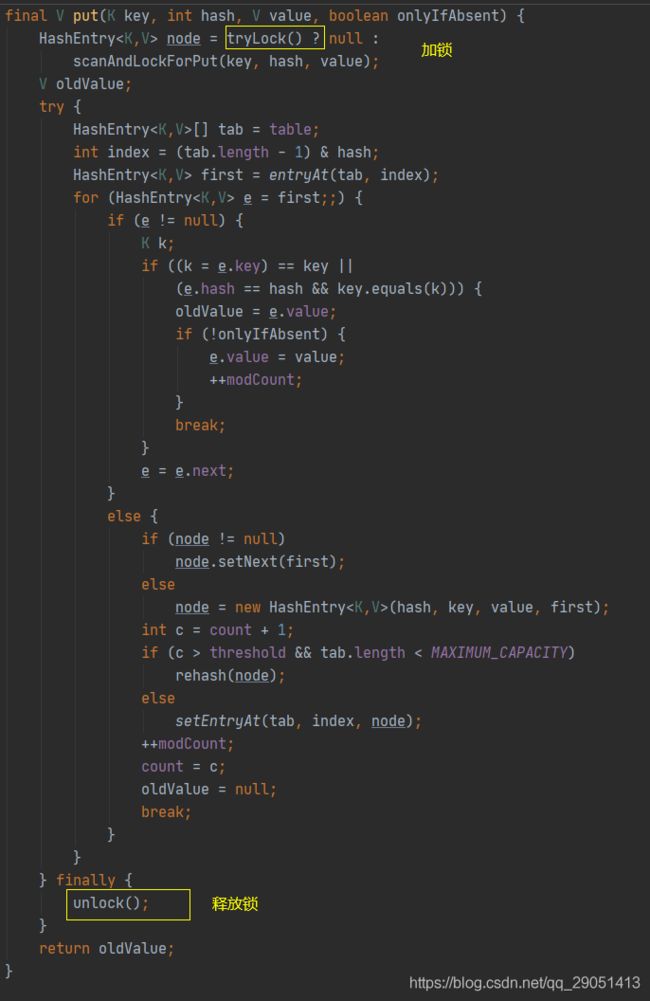
虽然 HashEntry 中的 value 是用 volatile 关键词修饰的,但是并不能保证并发的原子性,所以 put 操作时仍然需要加锁处理。
首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。
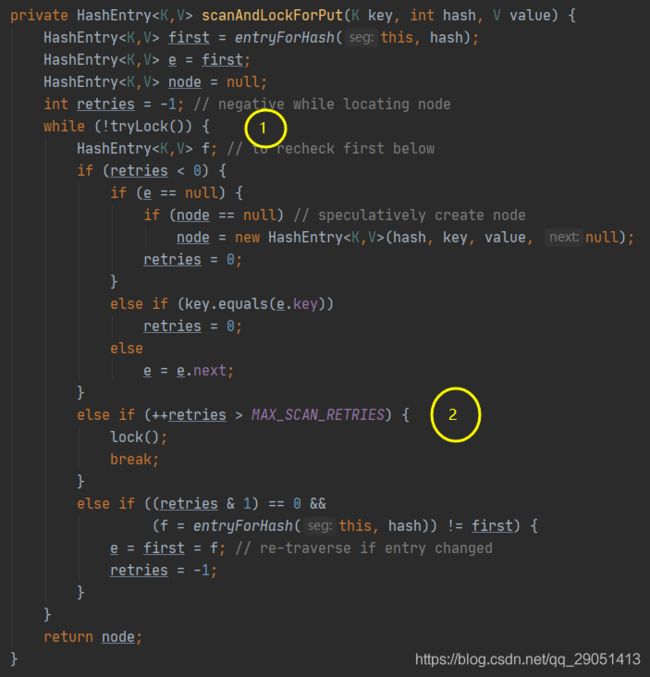
1、尝试自旋获取锁。
2、如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功。
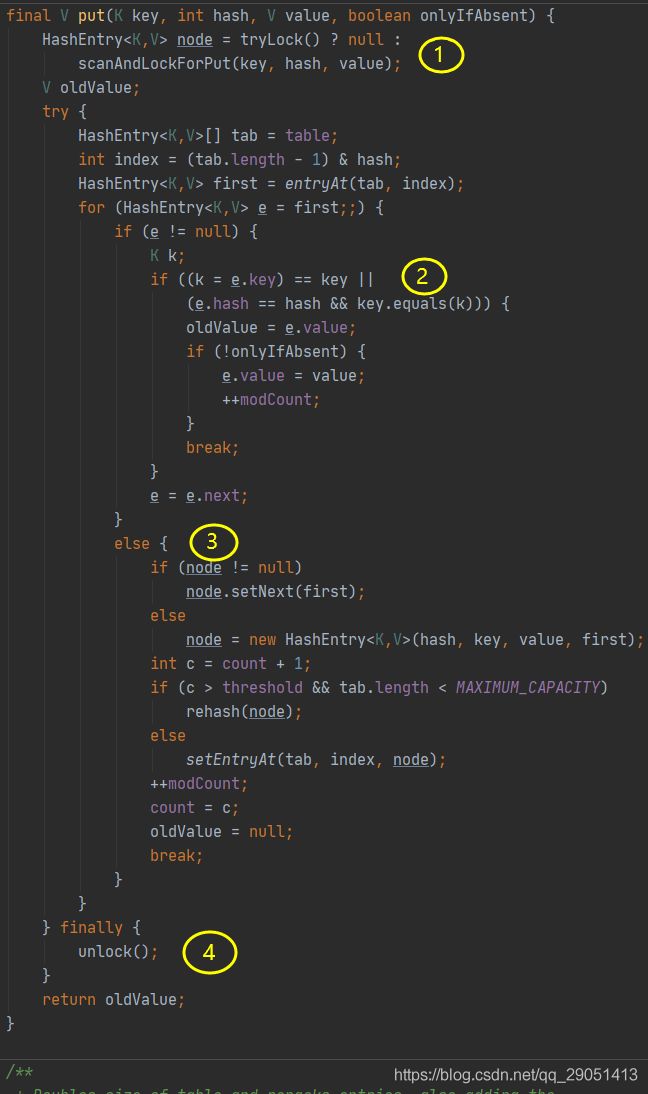
1、加锁操作;
2、遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
3、为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
4、释放锁;
4、Get 操作
源码: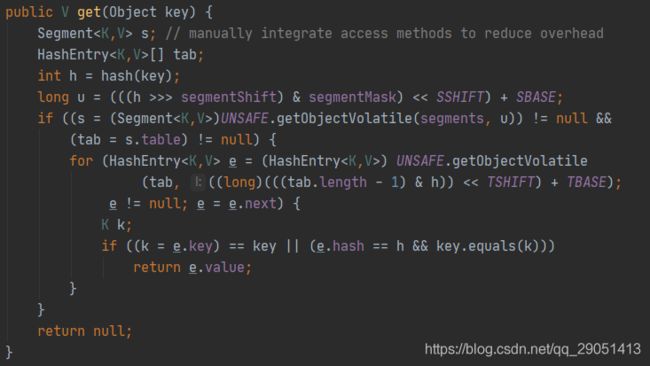
Get 操作比较简单:
1、Key 通过 Hash 之后定位到具体的 Segment;
2、再通过一次 Hash 定位到具体的元素上;
3、由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
5、高并发线程安全
Put 操作时,锁的是某个 Segment,其他线程对其他 Segment 的读写操作均不影响。因此解决了线程安全问题。
6、JDK8 的改进
以上介绍的是 JDK8 以前的情况,到了 JDK8 则有了一些改进。
6.1 结构改变
首先是结构上的变化,和 HashMap 一样,数组+链表改为数组+链表+红黑树。
6.2 HashEntry 改为 Node
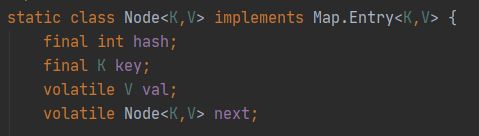
和 JDK7 的 HasEntry 作用相同,对 val 和 next 都用了 volatile 关键字,保证了可见性。
6.3 Put 操作的变化
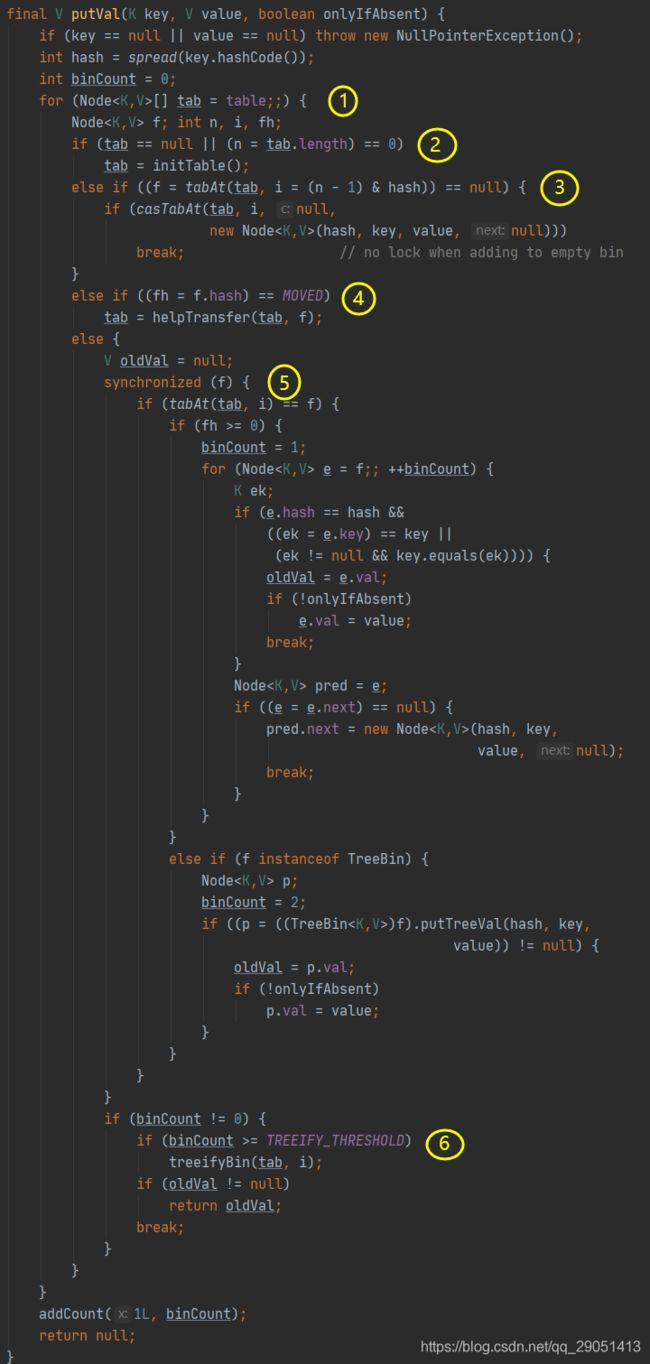
1、根据 key 计算出 hashcode,然后开始遍历 table;
2、判断是否需要初始化;
3、f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
4、如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
5、如果都不满足,则利用 synchronized 锁写入数据。
7、如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
6.4 Get 操作的变化
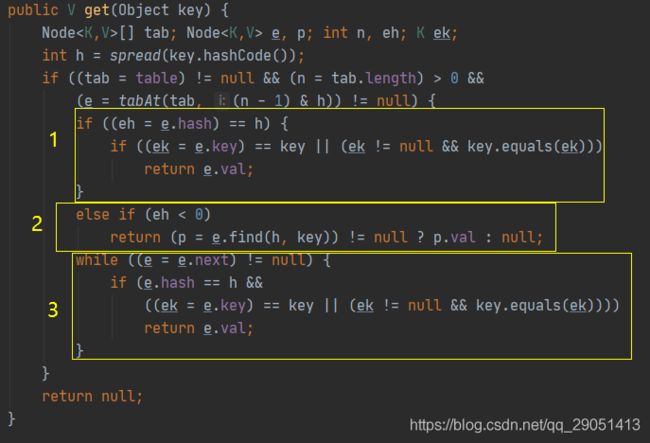
根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
如果是红黑树那就按照树的方式获取值。
都不满足那就按照链表的方式遍历获取值。
6.5 总结
1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。