一. 什么是模块(module)?
在实际应用中,有时程序所要实现功能比较复杂,代码量也很大。若把所有的代码都存储在一个文件中,则不利于代码的复用和维护。一种更好的方式是将实现不同功能的代码分拆到多个文件中分别进行存储,这样使得结构更加清晰,更易于维护。
为了实现这些需求,Python将一系列相关的代码组织在一起存储在一个文件中,这就是 模块(module)。最常见的模块是以.py“为后缀的文件(即用Python编写的代码文件),文件名就是模块名。当然模块还有一些其他的形式,例如”.so"文件、“.dll” 文件等,但初学者几乎接触不到。在一个模块中可以定义变量、函数、类等,也能包含可执行代码。Python中的模块可以分成3类:(1)Python内置的模块;(2)第三方模块;(3)用户自定义的模块。
看一个简单的例子,我们可以自定义一个加法模块add,文件名为“add.py”。
#
# @file add.py
#
def add(a,b):
return a + b
然后在当前目录中,通过import语句导入该模块,格式为import 模块名,之后就可以使用模块中定义的add函数进行运算了。
>>> import add >>> add.add(3, 5) >>> 8
注:上图第二条语句中的第1个add表示的是add模块,第2个add表示的是该模块中定义的add函数。
二. 模块是如何组织的?
Python中包含各种各样功能的模块,数量繁多。若把所有模块都放到一个目录中则很难使用和维护,例如容易产生模块名冲突的问题。因此我们需要一种合理的组织方式来提高模块的结构性和可维护性。Python是通过包来组织模块的。
什么是包(package)呢?包本质上就是一个目录(文件夹),目录名就是包名。 在包中可以包含多个子目录(子包)或模块。
例如我们可以将自定义的加法模块add、减法模块sub、乘法模块mul和除法模块dev组织成一个包arithmetic,包的架构如下图所示。

再比如在音频数据处理中,会用到很多模块来实现对音频数据的不同处理。我们就可以设计一个包——sound来组织这些模块,其下面又包含了3个子包effects、filters和formats,分别对应不同类型的功能模块,包的架构如下所示。

注:可以发现包中通常都包含一个__init__.py文件。在Python3.x中,这并不是必需的,__init__.py文件的作用将在后面进行介绍。
三. 如何导入模块?
要使用模块必须先进行导入,导入模块有两类方式:
方式一:import …
import […包].模块 [as 模块别名]
例如,import add,import arithmetic.add,import sound.filters.equalizerimport 包 [as 包别名]
例如,import arithmetic
方式二:from … import …
from 包.[…包] import 模块 [as 模块别名] / *
例如,from arithmetic import add,from arithmetic import *from […包].模块 import 变量/函数/类 [as 别名]/ *
例如,from arithmetic.add import add,from arithmetic.add import * 四. 每种导入方式有何区别?
上述两类模块导入的方式有什么区别呢?我们在实际编程时,该选择哪种方式导入模块呢?要回答这个问题,我们就需要了解模块导入背后的运行机制。在讲解这个机制之前,先简单介绍一下命名空间的概念。
1. 命名空间
命名空间(namespace)是映射到对象的名称 ,大多使用字典来实现。命名空间是在不同的时刻创建的,且拥有不同的生命周期。在Python语言中,有3类命名空间:内置命名空间、全局命名空间和局部命名空间。
内置命名空间(build-in namespace)
内置命名空间记录了以下信息:

内置命名空间中最常用的就是内置函数了,如下所示:

内置命名空间在Python解释器启动时创建,直至Python解释器退出都有效。 因此,Python解释器一旦启动,所有的内置函数不需要import,就可直接使用。
全局命名空间(global namespace)
用来记录模块级的变量、常量、函数、类以及其他导入的模块,可通过 globals() 函数查看。全局命名空间在读取模块定义时创建,通常也会持续到Python解释器退出。

可以看到,在全局命名空间中已经包含了一些名称,例如:
__name__
__doc__
__loader__
__spec__
__annotations__
__buitins__
这些名称都以双下划线开头和结尾,表示这是系统为每个模块自动生成的。这里重点介绍一下 __name__ 。它用来标识所在模块的名字,可能有两种取值:若该模块是当前正在运行的模块,则 __nam__ 的取值为 ‘__main__’; 若该模块不是正在运行的模块而是通过 import 语句导入的模块,则 __name__ 的取值为该模块的名称。在Python程序中,会经常看到如下语句:
if __name__ == 'main':
该语句的作用是:导入该模块时条件不成立,因而不会执行该语句后面的代码。
局部命名空间(local namespace)
用来记录函数或类中定义的变量、常量等,可通过 locals() 函数查看。
def func(a):
b = 2
c = a + b
print(locals())
>>> func(3)
{'a': 3, 'b': 2, 'c': 5}
函数的局部命名空间在调用该函数时创建,在函数返回或抛出不在函数内部处理的异常时销毁。
当Python解释器解释运行程序时,如遇到某个名称(如变量x)时,就会在所有命名空间中进行查找以确定其所映射的对象。查找的顺序如下:
- 查找局部命名空间。若找到,则停止。
- 若存在父函数,则查找父函数的局部命名空间(闭包)。若找到,则停止。
- 查找全局命名空间。若找到,则停止。
- 查找内置命名空间。若找到,则停止;若还找不到,Python将报错NameError 。
2. import … 的运行机制 import […包].模块 [as 模块别名]
这条语句的执行过程包括以下几个步骤:
(1)判断要导入的模块是否已被加载
导入模块时要分两种情况处理:第一情况是该模块之前已经被加载到内存中了;第二种情况时该模块尚未被加载到内存中。如何判断是哪种情况呢?这就需要用到数据结构 sys.modules。
sys模块包含系统级的信息,像正在运行的Python版本(sys.version)、系统级选项、最大允许递归的深度(sys.getrecursionlimit() 和 sys.setrecursionlimit() ) 。sys.modules 是一个全局字典,Python程序启动时就被加载到了内存中。sys.modules记录当前所有已加载模块的信息,字典的键字就是模块名,键值就是模块对象。
>>> import sys
>>> sys.modules
{'sys': , 'builtins': , '_frozen_importlib': , '_imp': , '_thread': , '_warnings': , '_weakref': , '_io': , 'marshal': , 'posix': , '_frozen_importlib_external': , 'time': , 'zipimport': , '_codecs': , 'codecs': , 'encodings.aliases': , 'encodings': , 'encodings.utf_8': , '_signal': , '_abc': , 'abc': , 'io': , '__main__': , '_stat': , 'stat': , '_collections_abc': , 'genericpath': , 'posixpath': , 'os.path': , 'os': , '_sitebuiltins': , 'apport_python_hook': , 'sitecustomize': , 'site': , 'readline': , 'atexit': , '_ast': , 'itertools': , 'keyword': , '_operator': , 'operator': , 'reprlib': , '_collections': , 'collections': , 'types': , '_functools': , 'functools': , 'contextlib': , 'enum': , 'ast': , '_opcode': , 'opcode': , 'dis': , 'collections.abc': , 'importlib._bootstrap': , 'importlib._bootstrap_external': , 'warnings': , 'importlib': , 'importlib.machinery': , '_sre': , 'sre_constants': , 'sre_parse': , 'sre_compile': , '_locale': , 'copyreg': , 're': , 'token': , 'tokenize': , 'linecache': , 'inspect': , 'rlcompleter': }
除了我们自己导入过的模块,Python在启动时已经预先加载了一些模块,其中大多都是内置(build-in)模块。内置模块是用C语言编写的,Python程序员必须依靠他们来实现系统级的功能,例如文件I/O等。内置模块是Python标准库的重要组成部分。
字典sys.modules对于加载模块起到了缓冲的作用,当使用 import 语句导入模块时,首先会在这个字典中进行查找,确定该模块是否已被加载到内存中。第一种情况:若模块已被加载,则只需将最外层包的名字添加到 import 语句所在模块的局部命名空间中,模块导入的过程就此结束。 第二种情况:若要导入的模块尚未被加载,则继续执行以下步骤。
(2)搜索要导入的模块
Python解释器首先会在内置模块中搜索同名的模块 (注:所以我们自定义的模块不应该与内置模块重名)。若没有找到,则在sys.path中的目录中进行搜索。sys.path是模块查找的路径列表,初始化为系统环境变量PYTHONPATH。
>>> import sys >>> sys.path ['', '/home/csl/test/py/2', '/usr/lib/python310.zip', '/usr/lib/python3.10', '/usr/lib/python3.10/lib-dynload', '/home/csl/.local/lib/python3.10/site-packages', '/usr/local/lib/python3.10/dist-packages', '/usr/lib/python3/dist-packages']
可以发现,sys.path列表的第一项path[0]是包含用于调用Python解释器的脚本的目录。如果脚本目录不可用(例如,交互调用解释器或从标准输入读取脚本),则path[0]是空字符串。path[0]将引导Python首先在当前目录中进行搜索。
若在当前目录中没有找到,则会在sys.path包含其他目录中依次搜索,这些目录中包含了已安装的第三方模块。若仍然没有找到,则会报错ModuleNotFoundError。
(3)加载要导入的模块
搜索到模块之后,接下来就是将其加载到内存中。如何进行加载呢?这里举例进行说明。
现在我们需要在main.py中导入自定义的arithmetic包中的 add 模块,其目录结构如下所示。

在main.py中,可以采用语句 “import arithmetic.add“ 实现。该语句进行模块加载的过程如下:
- 首先运行arithmetic包中的 __init__.py 文件(如果存在的话),该模块用到的所有对象都收录到一块新开辟的内存空间中。创建一个变量指向这个内存空间,用来引用其内容。变量的名字就是包名——arithmetic,从这个意义上说包其实也相当于一个模块。将arithmetic添加到sys.modules中。将arithmetic添加到main模块的局部命名空间中。
- 然后运行包arithmetic中要导入的模块add,该模块用到的所有对象也收录到一块新开辟的内存空间中。创建一个变量指向这个内存空间,用来引用其内容。若给模块起了别名,变量名就是模块别名;否则,变量名就是模块名。这里变量名就是模块名——add。将变量arithmetic.add 添加到sys.modules中。将add添加到arithmetic(__init__)模块的局部命名空间中。
下面来验证一下这个过程,在main.py中添加如下代码:
# # @file main.py # import arithmetic.add print(dir(),'\n') print(dir(arithmetic),'\n') print(dir(arithmetic.add),'\n')
代码中的 dir() 是一个内置函数,用于查找模块定义的名称,返回的结果是经过排序的字符串列表。
['__annotations__', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'arithmetic'] ['__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'add'] ['__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__', 'add']
可发现确实是将arithmetic 添加到了main模块的命名空间中,将add添加到了arithmetic的命名空间中。整个过程如下图所示:
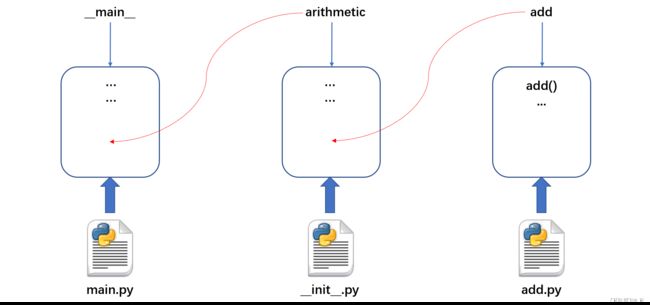
模块加载结束后,导入的模块就可以使用了。从上图也可以发现:在使用导入的模块中的对象时,前面必须加上包名和模块名。例如在main.py中使用add模块中定义的add函数,代码如下:
# # @file main.py # import arithmetic.add print(arithmetic.add.add(3,5))
import 包 [as 包别名]
这条语句的执行过程也是类似的。前面说过包本质上就是模块,导入包其实就是导入包下面的__init__模块。
注:若包中没有__init__.py 文件或者该文件为空,则只会将包名或者包别名添加到import语句所在模块的局部命名空间中,而不会导入包中的其他模块。
那使用语句 “import 包 [as 包别名]” 导入模块时 __init__.py 该如何编写呢?举个例子,包arithmetic中的add、sub、mul 和 dev四个模块,分别实现了加、减、乘、除四则运算。现在需要在main.py 文件中同时使用这四种运算,若采用语句“import […包].模块 [as 模块别名]”导入模块,代码如下:
# # @file main.py # import arithmetic.add import arithmetic.sub import arithmetic.mul import arithmetic.dev
也就是说当需要使用四则运算时,就需要把arithmeitc包中的模块逐个导入一遍,很麻烦!
可以采用“import 包 [as 包别名]” 导入模块,在 __init__.py 中添加如下代码:
# # @file __init__.py # import arithmetic.add import arithmetic.sub import arithmetic.mul import arithmetic.dev
此时,在main.py 文件只需编写代码:
# # @file main.py # import arithmetic
__init__.py 文件的作用不止于此。利用__init__.py,可以对外提供类型、变量和接口,对用户隐藏各个子模块的实现。一个模块的实现可能非常复杂,需要用很多个文件,甚至很多子模块来实现,但用户可能只需要知道一个类型和接口。就像我们的arithmetic例子中,用户只需要知道四则运算有add、sub、mul、dev四个接口,并不需要关心它们是怎么实现的,也没有必要去了解arithmetic中是如何组织各个子模块的。由于各个子模块的实现有可能非常复杂,而对外提供的类型和接口有可能非常的简单,我们就可以通过这个方式来对用户隐藏实现,同时提供非常方便的使用。
在编写__init__.py 文件时,应遵循以下原则:(1) 不要污染现有的命名空间。使用模块的一个目的就是为了避免命名冲突,如果在使用__init__.py时违背这个原则,则是反其道而为之,也没有使用模块的必要了。(2)只在__init__.py中编写必要的代码,不要做没必要的运算。
3. from … import … 的运行机制
第二类导入方式 “from … import …” 的运行包括以下步骤:
- 首先也是通过sys.modules判断要导入的模块是否已经加载过。
- 若尚未加载,则按照 “内置模块 --> sys.path路径列表中包含的模块” 的顺序进行搜索。
- 加载要导入的模块。
其中,前面两步与第一种方式 “import …” 是相同的;只是第3步,二者有所区别。因此,接下来只须介绍第3步模块加载这部分内容,仍用前面的例子进行说明。

from 包.[…包] import 模块 [as 模块别名] / *
在main.py中导入自定义的arithmetic包中的 add 模块,采用这种方式可写成 “from arithmetic import add”。该语句的模块加载过程如下:
首先运行arithmetic包中的 __init__.py 文件(如果存在的话),该模块用到的所有对象都收录到一块新开辟的内存空间中。创建一个变量指向这个内存空间,用来引用其内容。变量的名字就是包名——arithmetic。将arithmetic添加到sys.modules中。(注:这里不会将arithmetic添加到main模块的局部命名空间中。)
然后运行包arithmetic中要导入的模块add,该模块用到的所有对象也收录到一块新开辟的内存空间中。创建一个变量指向这个内存空间,用来引用其内容。若给模块起了别名,变量名就是模块别名;否则,变量名就是模块名。这里变量名就是模块名——add。将变量arithmetic.add 添加到sys.modules中。将add添加到main模块的局部命名空间中。
同样可以验证一下这个过程:
# # @file main.py # import from arithmetic import add print(locals())
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7f0f9af417e0>, '__spec__': None, '__annotations__': {}, '__builtins__': , '__file__': '/home/csl/test/py/2/main.py', '__cached__': None, 'add': }
可以发现该执行后,main模块的局部命名空间中确实增加了"add"这个名称,其所对应的就是arithmetic包中的add模块。因而,在main模块中,可以直接使用模块名来引用模块中的对象。
# # @file main.py # import from arithmetic import add print(add.add(3,5))
如果要在main中导入arithmetic包中的add、sub、mul、dev 四个模块,使用 “from … import …” 语句也是可以的。除了逐个进行导入的方法,还可以采用如下方法实现:
(1)在main.py 文件中添加以下代码:
# # @file main.py # import from arithmetic import *
在包arithmetic中的__init__.py文件中,将变量 __all__ 设置为要导入的模块列表:
# # @file __init__.py # __all__ = ['add', 'sub', 'mul', 'dev']
__all__ 通常是与 * 配合使用的。若在__init__.py文件中没有设置__all__变量,语句 “import from arithmetic import *” 仅会执行包arithmetic中的__init__.py文件。
from […包].模块 import 变量/函数/类 [as 别名]/ *
使用“from … import …” 语句不仅可以精确地从包中导入某些模块,还可以精确地从模块中导入某些对象(如变量、函数、类等)。例如在main.py文件中,需要使用arithmetic包里面add模块中定义的加法函数add(), 就可以写成“import from arithmetic.add import add” 。该语句会直接将add模块中的add() 函数的名字直接添加到main模块的局部命名空间中。
# # @file main.py # import from arithmetic.add import add print(locals())
{'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7f62f74697e0>, '__spec__': None, '__annotations__': {}, '__builtins__': , '__file__': '/home/csl/test/py/2/main.py', '__cached__': None, 'add': }
因此,在main中可以直接使用函数名add完成加法运算:
# # @file main.py # import from arithmetic.add import add print(add(3,5))
注:如果要导入一个模块中所有的对象,可以写成 “from […包].模块 import *”
五. 导入模块时的一些注意事项
1. 绝对导入与相对导入
第四部分在介绍 “import 包 [as 包别名]” 时,说过在main.py 中导入arithmetic中的add、sub、mul、dev四个模块可以采用如下方式实现:

# # @file __init__.py # import arithmetic.add import arithmetic.sub import arithmetic.mul import arithmetic.dev
# # @file main.py # import arithmetic
其中,__init__.py文件就是使用绝对路径名来导入模块的,称为绝对导入。这种导入方式中,要导入模块的路径都是从"根节点"开始的。“根节点的位置”由sys.path中的路径决定。
在这个例子中,__init__.py 要导入模块的绝对路径就是:“sys.path中的当前路径/arithmetic/add”, “sys.path中的当前路径/arithmetic/sub” …
与绝对导入相对的是相对导入,即使用相对路径名导入模块。在这个例子中,__init__.py 要导入的add 、sub、mul、dev模块都位于同一个路径下。因此,__init__.py采用相对导入的代码如下:
# # @file __init__.py # from . import add from . import sub from . import mul from . import dev
其中, “.” 就表示当前路径。另外,“..” 表示上一级路径。
使用相对导入的好处是:只需关心要导入模块的相对位置。因此,即便将包arithmetic的名字修改,采用相对导入的方式仍然可以正确运行。而若采用绝对导入,则必须同步修改__init__.py的代码。需要注意的是:采用相对导入的模块不能在包的内部直接运行(会报错)。关于相对导入的更多信息,可参考使用相对路径名导入包中子模块。
2. 重新加载模块
导入模块后,模块就已经被加载到内存中了,此后若对模块代码进行了改动,读取的内容仍然是内存中原来的结果。此时,需要使用imp.reload()来重新加载先前加载的模块。
>>> import arithmetic.add >>> import imp >>> imp.reload(arithmetic.add)
3. 模块的循环导入问题
模块的导入必须是单链的,而不能有循环导入,否则就会出错。

具体原理参考Python 史上最详解的 导入(import)
六. 参考资料
以上是我学习Python中import语句相关知识的总结(运行环境: 操作系统ubuntu22.04, Python版本 3.10.6),其中可能存在错误。在学习的过程中主要参考了以下资料:
Python–模块与包(https://article.itxueyuan.com/lMj6K)
__init__.py的神奇用法(https://zhuanlan.zhihu.com/p/115350758)
Python 3.x | 史上最详解的 导入(import)(https://blog.csdn.net/weixin_38256474/article/details/81228492)
Python Cookbook 3rd Edition Documentation(https://python3-cookbook.readthedocs.io/zh_CN/latest/index.html)
Modules(https://docs.python.org/3/tutorial/modules.html)
python 内置命名空间、标准库、模块相关概念 (https://www.cnblogs.com/goldsunshine/p/15085333.html)
到此这篇关于Python中import语句用法详解的文章就介绍到这了,更多相关Python import语句用法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!