机器学习(学习笔记)一
0.导学
机器学习:通过计算的手段,利用经验来改善自身性能。
人工智能:让机器变得像人一样拥有智能的学科
深度学习:神经网络类的机器学习算法

-
在未接触之前,许多人都会觉得机器学习是一门高深的内容,实际上它与人在不断试错尝试中对自己进行反省改进,进而找到事物之中的规律是一个道理。只不过它能在短时间内进行比人多的多的多的尝试,进而能在许多计算领域得到广泛的应用。
简单来说,机器学习就是让计算机能像人一样能从数据中学习出规律的一类算法
1.绪论
先简单的画一下绪论的思维导图
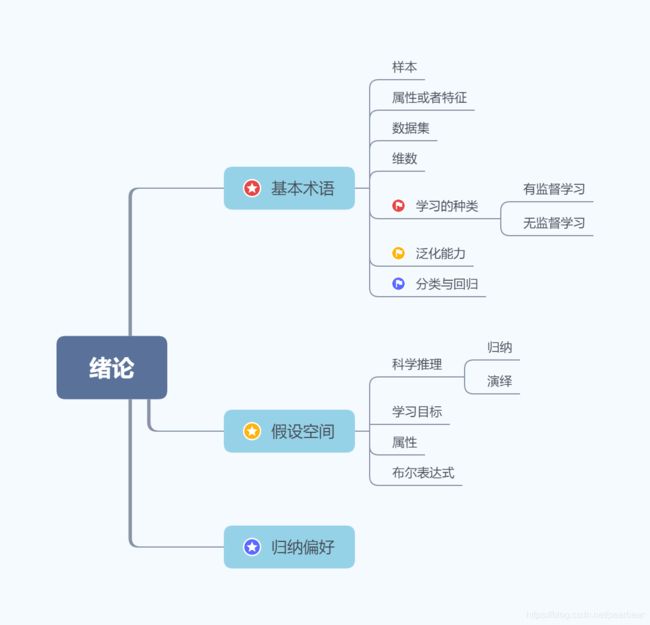
1.1 基本术语
-
数据集:用于机器学习训练模型的,收集到的数据的集合。 我们收集到一批西瓜的数据,这些数据的集合就是数据集。
D = { ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) , . . . , ( x m , y m ) } D = \{(x_1,y_1), (x_2,y_2),(x_3,y_3),...,(x_m,y_m)\} D={(x1,y1),(x2,y2),(x3,y3),...,(xm,ym)} -
样本:数据集里每一条记录即为一个“示例”或“样本”在这个西瓜的数据集 D D D里,每一个西瓜的信息就是一个样本,即 ( x i , y i ) (x_i,y_i) (xi,yi)。
(有时候“样本”指代的是整个采集的数据集,有时候指代的是数据集里的个体,具体情况通过上下文判断) -
特征:反应事件或对象在某方面的表示或性质的事例。
-
维数:数据使用特征的数目就是维数 d d d
-
属性值: 属性上的取值(如西瓜的颜色:“青绿”,“赤红”)。
-
样本空间:由若干特征组成的一个n维空间(n为特征个数)。
-
特征向量:因为在样本空间中一个点即可代表一个向量,因此一个示例即为一个特征向量。
-
分类与回归:如果预测的是离散值即为分类,如果是连续值即为回归。
-
泛化能力:训练的模型适用于新样本的能力
1.2 假设空间
-
科学推理:归纳演绎
- 归纳:从特殊到一般的“泛化”过程,即从具体的事实归结出一般性规律。例如定理推导。
- 演绎:从一般到特殊的“特化”过程,即从基础原理推演出具体状况。广义上指从样例中学习,狭义上就指从训练数据中学得概念。
-
学习目标:类似目标函数,比如学习什么样的瓜是好瓜
-
属性:西瓜的颜色,大小,敲声。人的身高,体重等等
-
布尔表达式:(颜色=?)^(大小=?) ^(敲声=?)
1.3 归纳偏好
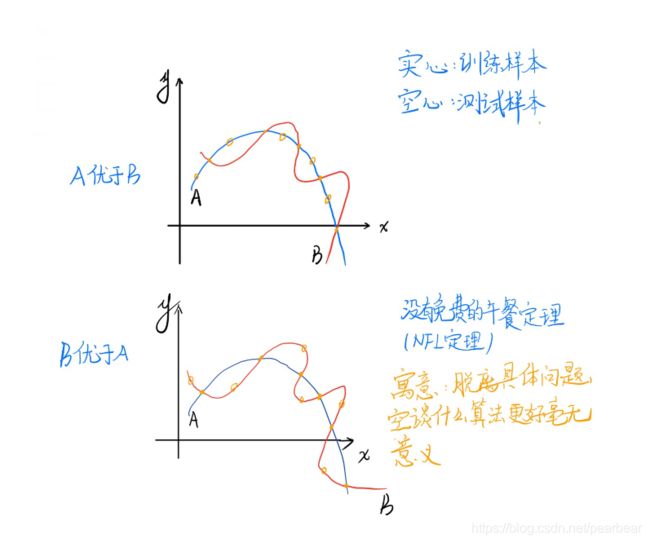
机器学习算法在学习过程中对某种类型假设的偏好,称为归纳偏好
奥卡姆剃刀: 一种常用的,自然科学研究中最基本的原则,若同时有多种假设与观察一致,选择最简单的那个。
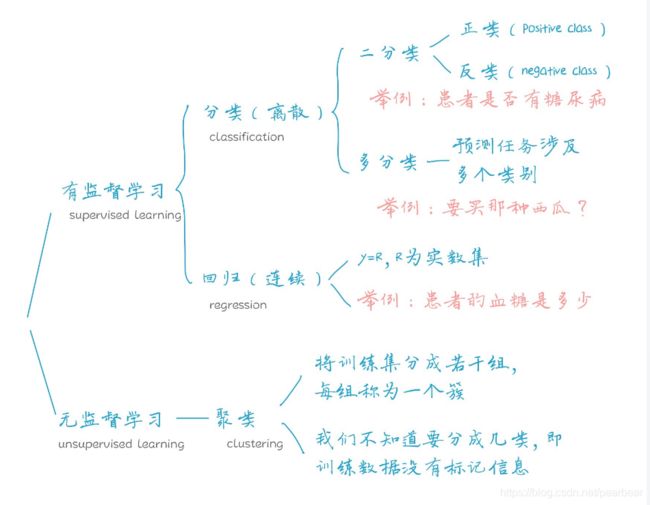
1.4 更具体的机器学习分类
根据用于训练数据的不同,可以将机器学习划分为几类:
- 有监督学习 Supervised Learning
- 无监督学习 Unsupervised Learning
- 半监督学习 Semi-supervised Learning
- 强化学习 Reinforcement Learning
1.4.1 有监督学习 (Supervised Learning)
在训练机器学习模型的时候,如果所有的数据都是标记过的(既有输入,又有输出),那么这样的机器学习就叫做有监督学习。
有监督学习用于解决回归、分类等问题
判断西瓜是否为好瓜就是一个有监督学习,因为我们的数据集中,输入有西瓜的色泽、根蒂、敲声的数据,输出有是否为好瓜的数据。更具体地来说,这是一个分类问题。
回归 Regression
-
根据一个人的身高、国籍、性别预测他/她的体重为多少千克
-
根据一个房子的面积、卧室数量、离公共交通站点距离、离学校距离预测它的价格
-
根据两只英雄联盟战队的历史选取英雄、一血率、一塔率、胜利游戏时长预测它们交手的胜率
-
······
以上的例子中,我们基于存在的历史数据(输入和输出都已知),去预测一个连续变化的(continuous)变量的值,这样的问题就叫做回归。
根据训练集 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } \{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\} {(x1,y1),(x2,y2),...,(xn,yn)}进行学习,建立一个从输入空间 X X X到输出空间 Y Y Y的映射 f : X → Y f:X\rightarrow Y f:X→Y,其中 Y Y Y中的值是连续变化的。
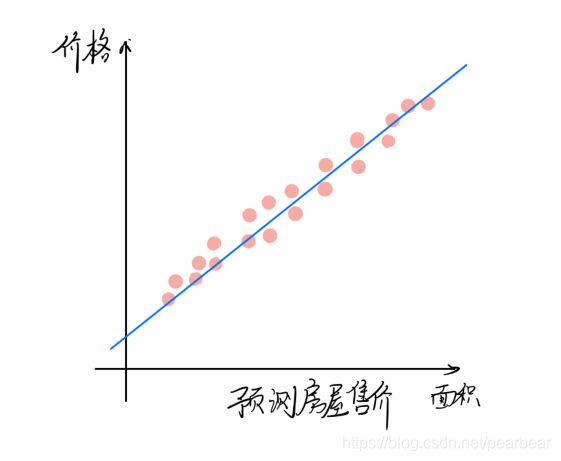
- 回归问题的输出必须是连续变化的量,比如重量、价格、面积等
- 回归问题的输入可以是连续变化的,也可以是离散的,比如国籍、性别、狗的种类等
- 一元回归问题(One-variable Regression):回归问题中输入特征只有一个,比如仅通过房屋的面积去预测价格
- 多元回归问题(Multi-variable Regression):回归问题中输入特征有多个,比如通过一个人的身高、国籍、性别去预测他/她的体重为多少千克
分类 (Classification)
-
根据一个人是否咳嗽、是否发烧、是否失去味觉、是否感到疲软无力预测他/她患有新冠肺炎的概率
-
根据一张图片判断里面出现的动物是不是猫
-
根据一个人Steam里各种类型游戏的总游玩时长判断他/她是否会购买某厂商出品的新游戏
-
······
以上的例子中,我们基于存在的历史数据(输入和输出都已知),去预测一个离散的(discrete)的变量,这样的问题就叫做分类。

根据训练集 { ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x n , y n ) } \{(x_1,y_1),(x_2,y_2),...,(x_n,y_n)\} {(x1,y1),(x2,y2),...,(xn,yn)}进行学习,建立一个从输入空间 X X X到输出空间 Y Y Y的映射 f : X → Y f:X\rightarrow Y f:X→Y,其中 Y Y Y的值是离散的。
- 分类问题的输出必须是离散的量,输出的变量又叫做标签(label) 或者种类(category)
- 分类问题的输入可以是连续变化的,也可以是离散的
- 二分类(Binary Classification):假设两个分类相互独立,在两个分类中将样本判断为其中一个,是二选一的问题,比如判断一个人是否患有新冠肺炎,输出为“患有”和“不患有“
- 多分类(Multi-class Classification):假设多个分类相互独立,在多个分类中将样本判断其中一个,是多选一的问题,比如判断一张图片上的动物是什么(可能是老虎、狮子、猎豹、豺狼中的一种)
- 多标签分类(Multi-label Classification):假设某些分类不相互独立,每个样本可以预测为一个或多个类别,是多选多的问题,比如给Steam上的一款游戏进行分类,可能同时会贴上“多人游戏”、“RPG”、“支持手柄”、“Windows平台“的标签
有监督学习很好地利用了数据中的输出变量作为训练过程中的“监督”(supervisor),但现实情况是,获取输出变量并没有那么容易,比如以10000张图片作为训练集,要判断图片上的动物是猫还是狗,有监督学习就要求先对10000张图片人工标注为“猫”或“狗”,这是很大的工作量;或者有些情况也不知道应该对数据进行怎样的人为分类,比如对于客户在某网站上购买记录的数据,想要将这些客户划分为不同的人群以进行商业分析或者营销推广,我们也无法对不同的人群进行准确的定义,这时候就可以靠机器学习来寻找数据之间的相似特征,从而进行归类。
无监督学习 (Unsupervised Learning)
在训练机器学习模型的时候,如果所有的训据都是未标记过的(有输入,没有任何对应的输出),那么这样的机器学习就叫做无监督学习。
无监督学习用于聚类等问题。
聚类 (Clustering)
根据一个没有打上标签的动物图片集,要让机器对其中不同的动物图片进行分类
根据用户在Steam上的历史购买记录,将他们划分为不同的群体以进行新游戏的推荐
······
以上的例子中,我们基于存在的未标记的历史数据(输入已知输出未知),去将样本进行分组,每一个分组叫一个簇,这样的问题叫就做聚类。
根据训练集 { x 1 , x 2 , . . . , x n } \{x_1,x_2,...,x_n\} {x1,x2,...,xn}进行学习,建立一个从输入空间 X X X到输出空间 Y Y Y的映射 f : X → Y f:X\rightarrow Y f:X→Y
- 硬聚类:每一个样本被严格被分到某一个簇中
- 软聚类:每一个样本被赋予了不同的概率值,代表它们属于不同的簇的概率。
半监督学习 (Semi-supervised Learning)
标注数据是费时费力的,特别是当标注数据这项工作需要一定的专业知识的时候,比如通过CT图片判断一个人是否患有癌症,要进行数据标注就需要专业的医师,他们往往只能完成一小部分图片的标注,这种情况下我们能够获得少量的标注过的数据。
在训练机器学习模型的时候,如果有少量的数据是被标记过的,其余的数据是未被标记过的,那么这样的机器学习就叫做半监督学习。
强化学习
对于人类所完成的一些任务来说,是没有明确的输入和输出的,比如训练机器下围棋、训练机器玩英雄联盟、自动驾驶汽车,人类之所以在这些任务中取得进步,是因为在学习的过程中不断接收到反馈,并根据这些反馈吸收经验。比如在英雄联盟中,你现在有两个选择:入侵敌方的野区,或是和团队一起打纳什男爵。你选择了前者,结果受到了惩罚,你被敌方抓死了,导致输掉了这局游戏,于是你吸取经验,这种情况下选择打男爵会是一个更好的选择。
强化学习就是遵循这样一种学习过程,在任务过程中,机器需要做出一步步的选择,每一个选择都会收获反馈(feedback),正向的反馈叫奖励(reward),负面的反馈则是惩罚(penalty),强化学习的目标是预测出每个一步的最佳抉择,以此达到最高的累计收益。
对于以上不同种类的问题,可以通过不同的机器学习算法解决,我们的目的就是基于收集到的数据,找到一个最合适的算法,训练出效果最好的模型,那么怎样评判训练出的模型效果好不好呢?看我的下一篇博客
https://blog.csdn.net/pearbear/article/details/118717522