这一篇博客整理用TensorFlow实现神经网络正则化的内容。
深层神经网络往往具有数十万乃至数百万的参数,可以进行非常复杂的特征变换,具有强大的学习能力,因此容易在训练集上过拟合。缓解神经网络的过拟合问题,一般有两种思路,一种是用正则化方法,也就是限制模型的复杂度,比如Dropout、L1和L2正则化、早停和权重衰减(Weight Decay),一种是增大训练样本量,比如数据增强(Data Augmentation)。这些方法的原理阐述可以看我之前整理的文章《深度学习之正则化方法》。
下面用TensorFlow来实现这些正则化方法。
一、Dropout正则化
首先来实现Dropout正则化。这种方法实在是太优秀太流行了,是一个比微信红包更天才的想法,对于提高模型的准确性有立竿见影的效果。

1、Dropout怎么做的呢?
其实很简单,在每个训练步骤中,输入层、隐藏层(不包括输出层)的神经元以p的概率被随机丢弃(谐音记忆法:神经元被抓爆了),然后在这次训练中,被丢弃的神经元不再起作用,但是在接下来的训练中,之前被“抓爆”的神经元可能继续被丢弃,也可能重新加入训练。
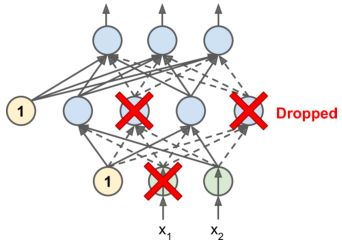
这个p叫做dropout rate(丢弃率),一般设置为0.5,也可以相机抉择。如果发现模型可能发生严重的过拟合问题,可以增大dropout rate,比如大型神经网络模型,而如果模型发生过拟合的风险较小,那么可以减小dropout rate,比如小型神经网络模型。
此外,与Batch Normalization有点类似,Dropout在训练阶段和测试阶段的做法不一样。训练阶段就是按照上面所说的去做,而测试阶段不需要做神经元的丢弃,这就是导致一个问题:假设p=0.5,那么测试阶段每个神经元的输入信号大约是训练阶段的两倍。为此,我们需要把神经元的输入连接权重乘以保持概率0.5(keep prop,也就是1-dropout rate),让输入信号减小一倍,与训练阶段大概保持一致。
2、为什么同是正则化方法,Dropout却如此优秀呢?
第一个原因是如果某个神经元相邻的伙伴被丢弃了,那么这个神经元就需要学会和更远的神经元进行配合,同时它自己也要一个顶俩,让自己更有用。 模型不会依赖于某些神经元,每个神经元都会受到特殊关注,从而使网络变得更强大。最终模型对输入的微小变化不再敏感,这等价于测试阶段输入前所未见的样本时,模型也能很好地进行预测。
第二个原因是Dropout可以看成是一种集成学习方法。每次对神经元进行随机丢弃,都会产生一个不同的神经网络结构,那么训练完毕后所得到的最终的神经网络,就可以看作是所有这些小型神经网络的集成。
于是Dropout正则化就像国发邓紫棋一样优秀了。

3、用TensorFlow实现Dropout
使用TensorFlow实现Dropout,可以将tf.layers.dropout()这个函数应用于输入层和每个隐藏层。在训练期间,此函数随机丢弃一些神经元(将它们的输出设置为0)。训练结束后,这个函数就不再发挥作用了。
好,下面还是用MINIST数据集来构建一个神经网络模型,用Dropout来正则化,除了把优化器设为Momentum外没有使用上一篇博客中整理的其他加速方法。
第一步还是先准备小批量样本用于训练,以及准备验证集和测试集。
import tensorflow as tf import numpy as np from functools import partial import time from datetime import timedelta # 记录训练花费的时间 def get_time_dif(start_time): end_time = time.time() time_dif = end_time - start_time #timedelta是用于对间隔进行规范化输出,间隔10秒的输出为:00:00:10 return timedelta(seconds=int(round(time_dif))) # 定义输入层、输出层和中间隐藏层的神经元数量 n_inputs = 28 * 28 # MNIST n_hidden1 = 300 n_hidden2 = 100 n_outputs = 10 # 准备训练数据集、验证集和测试集,并生成小批量样本 (X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data() X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0 X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0 y_train = y_train.astype(np.int32) y_test = y_test.astype(np.int32) X_valid, X_train = X_train[:5000], X_train[5000:] y_valid, y_train = y_train[:5000], y_train[5000:] def shuffle_batch(X, y, batch_size): rnd_idx = np.random.permutation(len(X)) n_batches = len(X) // batch_size for batch_idx in np.array_split(rnd_idx, n_batches): X_batch, y_batch = X[batch_idx], y[batch_idx] yield X_batch, y_batch
第二步是在构建网络层时,运用Dropout正则化。
下面的代码已经进行了注释,这里再说明一点,在隐藏层的神经元中,对输入值是先激活再去做Dropout,也就是对f(WX+b)进行丢弃,而不是对WX+b。
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X") y = tf.placeholder(tf.int32, shape=(None), name="y") # 和Batch Norm的操作有点类似,先定义一个trianing training = tf.placeholder_with_default(False, shape=(), name='training') # 设置丢弃率率 dropout_rate = 0.5 # == 1 - keep_prob with tf.name_scope("dnn"): # 在输入层对输入数据先进行Dropout,便于应用到隐藏层 X_drop = tf.layers.dropout(X, dropout_rate, training=training) # 在隐藏层先进行激活,得到激活之后的值 hidden1 = tf.layers.dense(X_drop, n_hidden1, activation=tf.nn.relu, name="hidden1") # 把Dropout应用到隐藏层,对激活值进行随机丢弃,所以这里没有激活函数了 hidden1_drop = tf.layers.dropout(hidden1, dropout_rate, training=training) hidden2 = tf.layers.dense(hidden1_drop, n_hidden2, activation=tf.nn.relu, name="hidden2") hidden2_drop = tf.layers.dropout(hidden2, dropout_rate, training=training) logits = tf.layers.dense(hidden2_drop, n_outputs, name="outputs")
第三步定义模型其他部分,然后进行训练和测试。
这里再提醒一点,那就是在sess.run()中,别忘了传入feed_dict={training: True}。
取batch size = 50,训练耗时1分08秒,测试精度为97.41%。
with tf.name_scope("loss"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss = tf.reduce_mean(xentropy, name="loss") learning_rate = 0.01 with tf.name_scope("train"): optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9) training_op = optimizer.minimize(loss) with tf.name_scope("eval"): correct = tf.nn.in_top_k(logits, y, 1) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) init = tf.global_variables_initializer() saver = tf.train.Saver() n_epochs = 40 batch_size = 50 with tf.Session() as sess: init.run() start_time = time.time() for epoch in range(n_epochs): for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size): sess.run(training_op, feed_dict={training: True, X: X_batch, y: y_batch}) if epoch % 5 ==0 or epoch == 39: accuracy_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch}) accuracy_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid}) print(epoch, "Batch accuracy:", accuracy_batch,"Validation accuracy:", accuracy_val) time_dif = get_time_dif(start_time) print("\nTime usage:", time_dif) save_path = saver.save(sess, "./my_model_final_dropout.ckpt") with tf.Session() as sess: saver.restore(sess, "./my_model_final_dropout.ckpt") # or better, use save_path X_test_20 = X_test[:20] # 得到softmax之前的输出 Z = logits.eval(feed_dict={X: X_test_20}) # 得到每一行最大值的索引 y_pred = np.argmax(Z, axis=1) print("Predicted classes:", y_pred) print("Actual calsses: ", y_test[:20]) # 评估在测试集上的正确率 acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test}) print("\nTest_accuracy:", acc_test)
0 Batch accuracy: 0.96 Validation accuracy: 0.9316 5 Batch accuracy: 0.94 Validation accuracy: 0.965 10 Batch accuracy: 1.0 Validation accuracy: 0.9728 15 Batch accuracy: 0.96 Validation accuracy: 0.9728 20 Batch accuracy: 1.0 Validation accuracy: 0.9764 25 Batch accuracy: 0.96 Validation accuracy: 0.9768 30 Batch accuracy: 0.96 Validation accuracy: 0.9768 35 Batch accuracy: 0.98 Validation accuracy: 0.979 39 Batch accuracy: 0.96 Validation accuracy: 0.977 Time usage: 0:01:08 INFO:tensorflow:Restoring parameters from ./my_model_final_dropout.ckpt Predicted classes: [7 2 1 0 4 1 4 9 6 9 0 6 9 0 1 5 9 7 3 4] Actual calsses: [7 2 1 0 4 1 4 9 5 9 0 6 9 0 1 5 9 7 3 4] Test_accuracy: 0.9741
二、L1和L2正则化
实现了优秀的Dropout正则化,我们再把传统机器学习领域中比较通用的L1和L2正则化方法运用到神经网络的训练中。

1、如何做L1和L2正则化?
L1和L2正则化方法就是把权重的L1范数或L2范数加入到经验风险最小化的损失函数中(或者把二者同时加进去),用来约束神经网络的权重,让部分权重为0(L1范数的效果)或让权重的值非常小(L2范数的效果),从而让模型变得简单,减少过拟合。得到的损失函数为结构风险最小化的损失函数。
公式如下,p∈{1,2},λ是正则化系数,如果模型可能发生严重的过拟合问题,那就选择比较大的λ,比如训练一个非常庞大的网络,否则可以设置得小一些。

2、L1正则化和L2正则化的区别?
L1正则化会使得最终的权重参数是稀疏的,也就是说权重矩阵中很多值为0;而L2正则化会使得最终的权重值非常小,但不会等于0。这么说来L1正则化有点像Dropout的另一种不常见的方式——丢弃连接边。在实际操作中一般来说选择L2正则化,因为L1范数在取得最小值处是不可导的,这会给后续求梯度带来麻烦。
用TensorFlow来做L1正则化或L2正则化,就要在构建网络时传入相应的函数:tf.contrib.layers.l1_regularizer(),tf.contrib.layers.l2_regularizer() 或者 tf.contrib.layers.l1_l2_regularizer()。并且在定义损失时,把L1正则化或L2正则化的损失添加到经验风险损失中去。这一部分的代码如下:
X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X") y = tf.placeholder(tf.int32, shape=(None), name="y") # 这是正则化系数,由于这是小型网络模型,过拟合的可能比较小,所以这个系数设置得小一些。 scale = 0.001 # 构造这个全连接模块,传入各层都相同的参数,便于复用。 my_dense_layer = partial( tf.layers.dense, activation=tf.nn.relu, # 在这里传入了L2正则化函数,并在函数中传入正则化系数。 kernel_regularizer=tf.contrib.layers.l2_regularizer(scale)) with tf.name_scope("dnn"): hidden1 = my_dense_layer(X, n_hidden1, name="hidden1") hidden2 = my_dense_layer(hidden1, n_hidden2, name="hidden2") logits = my_dense_layer(hidden2, n_outputs, activation=None, name="outputs") with tf.name_scope("loss"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits( labels=y, logits=logits) # 经验风险损失 base_loss = tf.reduce_mean(xentropy, name="avg_xentropy") # L2正则化损失 reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES) # 必须将正规化损失添加到基本损失中,构成结构风险损失。不过没有明白为啥把base_loss放在列表里。 loss = tf.add_n([base_loss] + reg_losses, name="loss")
完整的代码如下,下面的代码和Dropout正则化的代码还是有不少差异,需要注意。
前面说了选择L2正则化可能效果更好,为了验证这个说法,我选择batch size = 50,对神经网络分别做L1正则化和L2正则化,得到的测试精度分别为94.95%和98.17%,可见L2正则化的确效果更好。
import tensorflow as tf import numpy as np from functools import partial import time from datetime import timedelta # 记录训练花费的时间 def get_time_dif(start_time): end_time = time.time() time_dif = end_time - start_time #timedelta是用于对间隔进行规范化输出,间隔10秒的输出为:00:00:10 return timedelta(seconds=int(round(time_dif))) # 定义输入层、输出层和中间隐藏层的神经元数量 n_inputs = 28 * 28 # MNIST n_hidden1 = 300 n_hidden2 = 100 n_outputs = 10 # 准备训练数据集、验证集和测试集,并生成小批量样本 (X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data() X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0 X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0 y_train = y_train.astype(np.int32) y_test = y_test.astype(np.int32) X_valid, X_train = X_train[:5000], X_train[5000:] y_valid, y_train = y_train[:5000], y_train[5000:] def shuffle_batch(X, y, batch_size): rnd_idx = np.random.permutation(len(X)) n_batches = len(X) // batch_size for batch_idx in np.array_split(rnd_idx, n_batches): X_batch, y_batch = X[batch_idx], y[batch_idx] yield X_batch, y_batch X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X") y = tf.placeholder(tf.int32, shape=(None), name="y") # 这是正则化系数,由于这是小型网络模型,过拟合的可能比较小,所以这个系数设置得小一些。 scale = 0.001 # 构造这个全连接模块,传入各层都相同的参数,便于复用。 my_dense_layer = partial( tf.layers.dense, activation=tf.nn.relu, # 在这里传入了L2正则化函数,并在函数中传入正则化系数。 kernel_regularizer=tf.contrib.layers.l2_regularizer(scale)) with tf.name_scope("dnn"): hidden1 = my_dense_layer(X, n_hidden1, name="hidden1") hidden2 = my_dense_layer(hidden1, n_hidden2, name="hidden2") logits = my_dense_layer(hidden2, n_outputs, activation=None, name="outputs") with tf.name_scope("loss"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits( labels=y, logits=logits) # 经验风险损失 base_loss = tf.reduce_mean(xentropy, name="avg_xentropy") # L2正则化损失 reg_losses = tf.get_collection(tf.GraphKeys.REGULARIZATION_LOSSES) # 必须将正规化损失添加到基本损失中,构成结构风险损失。不过没有明白为啥把base_loss放在列表里。 loss = tf.add_n([base_loss] + reg_losses, name="loss") learning_rate = 0.01 with tf.name_scope("train"): optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.9) training_op = optimizer.minimize(loss) with tf.name_scope("eval"): correct = tf.nn.in_top_k(logits, y, 1) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) init = tf.global_variables_initializer() saver = tf.train.Saver() n_epochs = 40 batch_size = 50 with tf.Session() as sess: init.run() start_time = time.time() for epoch in range(n_epochs): for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size):
sess.run(training_op,feed_dict={X: X_batch, y: y_batch}) if epoch % 5 ==0 or epoch == 39: accuracy_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch}) accuracy_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid}) print(epoch, "Batch accuracy:", accuracy_batch,"Validation accuracy:", accuracy_val) time_dif = get_time_dif(start_time) print("\nTime usage:", time_dif) save_path = saver.save(sess, "./my_model_final_L2.ckpt") with tf.Session() as sess: saver.restore(sess, "./my_model_final_L2.ckpt") # or better, use save_path X_test_20 = X_test[:20] # 得到softmax之前的输出 Z = logits.eval(feed_dict={X: X_test_20}) # 得到每一行最大值的索引 y_pred = np.argmax(Z, axis=1) print("Predicted classes:", y_pred) print("Actual calsses: ", y_test[:20]) # 评估在测试集上的正确率 acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test}) print("\nTest_accuracy:", acc_test)
三、早停
早停(Early Stopping) 一种比较好的防止过拟合的方法,意思是在模型训练的过程中,如果观察到模型经过很多次迭代后,在验证集上的性能仍然不再提高甚至下降时,就强行中止训练,并把之前保存的验证结果最好的模型作为最终训练好的模型。
原因是随着迭代次数的增加,模型在训练集上的预测误差一般都是不断下降的,但是在验证集上会有不同。验证误差一开始也会下降,一定迭代次数后会停止下降,反而开始上升,形成一个偏U型的曲线,这表明该模型从谷底处开始过拟合了。
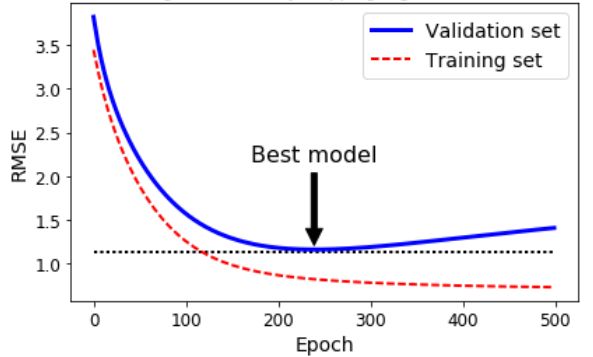
![]() 使用TensorFlow实现此功能的一种方法是记录迭代的总步数,然后定期(例如,每10步)在验证集上评估模型,并与之前的最好结果进行对比。
使用TensorFlow实现此功能的一种方法是记录迭代的总步数,然后定期(例如,每10步)在验证集上评估模型,并与之前的最好结果进行对比。
-
如果它优于之前的最好结果,就把这次的模型验证精度记为模型的最好验证结果。
-
如果模型经过了N步以后(比如2000步),验证精度一直没有超过之前的最好记录,那就中止训练。
-
把之前已经保存好的最优模型作为最终的模型,在测试集上进行预测。
![]() 好,接下来我们不用任何的加速优化方法和其他的正则化方法,构建一个简单的全连接神经网络,来看看怎么用早停来缓解过拟合问题。关键步骤是在模型的训练和保存阶段,设定为每10步就在验证集上评估一次模型,如果2000步以后验证结果还没有提升,就中止训练。下面的代码已经非常清楚了。
好,接下来我们不用任何的加速优化方法和其他的正则化方法,构建一个简单的全连接神经网络,来看看怎么用早停来缓解过拟合问题。关键步骤是在模型的训练和保存阶段,设定为每10步就在验证集上评估一次模型,如果2000步以后验证结果还没有提升,就中止训练。下面的代码已经非常清楚了。
# 定义好训练轮次和batch-size n_epochs = 40 batch_size = 50 with tf.Session() as sess: init.run() start_time = time.time() # 记录总迭代步数,一个batch算一步 # 记录最好的验证精度 # 记录上一次验证结果提升时是第几步。 # 如果迭代2000步后结果还没有提升就中止训练。 total_batch = 0 best_acc_val = 0.0 last_improved = 0 require_improvement = 2000 flag = False for epoch in range(n_epochs): for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size): sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) # 每次迭代10步就验证一次 if total_batch % 10 == 0: acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch}) acc_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid}) # 如果验证精度提升了,就替换为最好的结果,并保存模型 if acc_val > best_acc_val: best_acc_val = acc_val last_improved = total_batch save_path = saver.save(sess, "./my_model_stop.ckpt") improved_str = 'improved!' else: improved_str = '' # 记录训练时间,并格式化输出验证结果,如果提升了,会在后面提示:improved! time_dif = get_time_dif(start_time) msg = 'Epoch:{0:>4}, Iter: {1:>6}, Acc_Train: {2:>7.2%}, Acc_Val: {3:>7.2%}, Time: {4} {5}' print(msg.format(epoch, total_batch, acc_batch, acc_val, time_dif, improved_str)) # 记录总迭代步数 total_batch += 1 # 如果2000步以后还没提升,就中止训练。 if total_batch - last_improved > require_improvement: print("No optimization for ", require_improvement," steps, auto-stop in the ",total_batch," step!") # 跳出这个轮次的循环 flag = True break # 跳出所有训练轮次的循环 if flag: break
完整的代码如下。
import tensorflow as tf import numpy as np import time from datetime import timedelta # 记录训练花费的时间 def get_time_dif(start_time): end_time = time.time() time_dif = end_time - start_time #timedelta是用于对间隔进行规范化输出,间隔10秒的输出为:00:00:10 return timedelta(seconds=int(round(time_dif))) n_inputs = 28*28 n_hidden1 = 300 n_hidden2 = 100 n_outputs = 10 (X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_data() X_train = X_train.astype(np.float32).reshape(-1, 28*28) / 255.0 X_test = X_test.astype(np.float32).reshape(-1, 28*28) / 255.0 y_train = y_train.astype(np.int32) y_test = y_test.astype(np.int32) X_valid, X_train = X_train[:5000],X_train[5000:] y_valid, y_train = y_train[:5000],y_train[5000:] # 打乱数据,并生成batch def shuffle_batch(X, y, batch_size): # permutation不直接在原来的数组上进行操作,而是返回一个新的打乱顺序的数组,并不改变原来的数组。 rnd_idx = np.random.permutation(len(X)) n_batches = len(X) // batch_size # 把rnd_idx这个一位数组进行切分 for batch_idx in np.array_split(rnd_idx, n_batches): X_batch, y_batch = X[batch_idx], y[batch_idx] yield X_batch, y_batch X = tf.placeholder(tf.float32, shape=(None, n_inputs), name="X") y = tf.placeholder(tf.int32, shape=(None), name="y") with tf.name_scope("dnn"): hidden1 = tf.layers.dense(X, n_hidden1, name="hidden1", activation=tf.nn.relu) hidden2 = tf.layers.dense(hidden1, n_hidden2, name="hidden2", activation=tf.nn.relu) logits = tf.layers.dense(hidden2, n_outputs, name="outputs") y_proba = tf.nn.softmax(logits) # 定义损失函数和计算损失 with tf.name_scope("loss"): xentropy = tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=logits) loss = tf.reduce_mean(xentropy, name="loss") # 定义优化器 learning_rate = 0.01 with tf.name_scope("train"): optimizer = tf.train.GradientDescentOptimizer(learning_rate) training_op = optimizer.minimize(loss) # 评估模型,使用准确性作为我们的绩效指标 with tf.name_scope("eval"): # logists最大值的索引在0-9之间,恰好就是被预测所属于的类,因此和y进行对比,相等就是True,否则为False correct = tf.nn.in_top_k(logits, y, 1) accuracy = tf.reduce_mean(tf.cast(correct, tf.float32)) init = tf.global_variables_initializer() saver = tf.train.Saver() # 定义好训练轮次和batch-size n_epochs = 40 batch_size = 50 with tf.Session() as sess: init.run() start_time = time.time() # 记录总迭代步数,一个batch算一步 # 记录最好的验证精度 # 记录上一次验证结果提升时是第几步。 # 如果迭代2000步后结果还没有提升就中止训练。 total_batch = 0 best_acc_val = 0.0 last_improved = 0 require_improvement = 2000 flag = False for epoch in range(n_epochs): for X_batch, y_batch in shuffle_batch(X_train, y_train, batch_size): sess.run(training_op, feed_dict={X: X_batch, y: y_batch}) # 每次迭代10步就验证一次 if total_batch % 10 == 0: acc_batch = accuracy.eval(feed_dict={X: X_batch, y: y_batch}) acc_val = accuracy.eval(feed_dict={X: X_valid, y: y_valid}) # 如果验证精度提升了,就替换为最好的结果,并保存模型 if acc_val > best_acc_val: best_acc_val = acc_val last_improved = total_batch save_path = saver.save(sess, "./my_model_stop.ckpt") improved_str = 'improved!' else: improved_str = ''
# 记录训练时间,并格式化输出验证结果。
time_dif = get_time_dif(start_time)
msg = 'Epoch:{0:>4}, Iter: {1:>6}, Acc_Train: {2:>7.2%}, Acc_Val: {3:>7.2%}, Time: {4} {5}'
print(msg.format(epoch, total_batch, acc_batch, acc_val, time_dif, improved_str)) # 记录总迭代步数 total_batch += 1 # 如果2000步以后还没提升,就中止训练。 if total_batch - last_improved > require_improvement: print("No optimization for ", require_improvement," steps, auto-stop in the ",total_batch," step!") # 跳出这个轮次的循环 flag = True break # 跳出所有训练轮次的循环 if flag: break with tf.Session() as sess: saver.restore(sess, "./my_model_stop.ckpt") # or better, use save_path X_test_20 = X_test[:20] # 得到softmax之前的输出 Z = logits.eval(feed_dict={X: X_test_20}) # 得到每一行最大值的索引 y_pred = np.argmax(Z, axis=1) print("Predicted classes:", y_pred) print("Actual calsses: ", y_test[:20]) # 评估在测试集上的正确率 acc_test = accuracy.eval(feed_dict={X: X_test, y: y_test}) print("\nTest_accuracy:", acc_test)
模型最后一次在验证集上提升的输出结果如下。验证结果的最后一次提升发生在第23000步,验证精度为97.62%,然后在第25000步时中止了训练。在测试集上的测试精度为97.13%
Epoch: 20, Iter: 22970, Acc_Train: 94.00%, Acc_Val: 97.28%, Time: 0:00:54 Epoch: 20, Iter: 22980, Acc_Train: 100.00%, Acc_Val: 97.32%, Time: 0:00:54 Epoch: 20, Iter: 22990, Acc_Train: 100.00%, Acc_Val: 97.30%, Time: 0:00:54 Epoch: 20, Iter: 23000, Acc_Train: 100.00%, Acc_Val: 97.62%, Time: 0:00:55 improved! Epoch: 20, Iter: 23010, Acc_Train: 100.00%, Acc_Val: 97.52%, Time: 0:00:55 Epoch: 20, Iter: 23020, Acc_Train: 100.00%, Acc_Val: 97.52%, Time: 0:00:55 Epoch: 20, Iter: 23030, Acc_Train: 98.00%, Acc_Val: 97.48%, Time: 0:00:55
四、其他
神经网络模型中还有一些其他的正则化方法,下面只提一下大概的思路,就不再去实现了。
1、数据增强
缓解过拟合问题的另一种思路是扩增样本量,但是这需要付出较大的成本搜集数据和标注数据。而数据增强是从现有的样本数据集中人为地生成一些数据,比如对图片进行旋转、缩放、裁剪等变换,一般用在图像处理领域。不过有意思的是,自然语言处理领域也有一些数据增强的方法,今年年初有篇论文《EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks》介绍了四种NLP数据增强方法,用在文本分类任务中。这四种方法分别是
(1)同义词替换:不考虑停用词,从句子中随机抽取n个词,然后从同义词词典中随机抽取同义词,并进行替换。
(2)随机插入:随机抽取一个词,然后在该词的同义词集合中随机选择一个,插入原句子中的随机位置。
(3)随机交换:在一个句子中随机选择两个词,交换位置。
(4)随机删除:以概率p随机删除句子中的每个词。
实验结果发现,运用四种NLP数据增强方法后,仅仅使用50%的训练数据,就能够达到原始模型使用100%训练数据的效果,还是比较强大的。
2、权重衰减
神经网络中还有一种正则化方法叫权重衰减,用随机梯度下降算法进行优化时,L2正则化可以看作就是在做权重衰减。
3、最大范数正则化
这个方法很简单,就是让权重的L2范数小于一个数r,直截了当地约束权重的大小,类似于梯度截断,还可以帮助缓解梯度消失/爆炸问题。
参考资料:
1、《Hands On Machine Learning with Scikit-Learn and TensorFlow》
2、Jason W. Wei, Kai Zou :《EDA: Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks》