MySQL表的增删查改
目录
1、表的插入
<1> 全列插入
<2> 指定列插入
<3> 插入否则更新
<4> 替换
2、表的查找
<1>全列查询
<2>指定列查询
<3> where条件
<4> 筛选分页结果
3、表的修改
4、表的数据删除
5、查看表结构
6、插入查询结果
1、表的插入
INSERT [ INTO ] table_name [( column [, column ] ...)] VALUES (value_list ) [, ( value _list)] ...value_list: value , [, value ] ...
创建一个学生表:
create table if not exists student(
id int primary key comment '学号',
name varchar(10) not null,
number varchar(11) not null comment '手机号'
);
<1> 全列插入
insert into student values(10, '张三', '1111223');
insert into student values(11, '李四', '1122223');

说明:
-
全列插入可以不指定列名称,不过数量必须和定义表的列的数量及顺序一致
<2> 指定列插入
insert into student(id, name, number) values(12, '王五', '2222222'),(13, '赵六', '2222223');

说明:
- 指定列插入可以一次插入多组数据,也可以单组数据插入
<3> 插入否则更新
INSERT ... ON DUPLICATE KEY UPDATE column = value [, column = value ] ...
insert into student(id, name, number) values(13, '赵六', '2222224') on duplicate key update name='赵六', number=2222224;
Query OK, 2 rows affected (0.04 sec)-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等-- 1 row affected: 表中没有冲突数据,数据被插入-- 2 row affected: 表中有冲突数据,并且数据已经被更新

<4> 替换
-- 主键 或者 唯一键 没有冲突,则直接插入;-- 主键 或者 唯一键 如果冲突,则删除后再插入replace into student(id, name, number) values(13, '赵六', 2222224);
2、表的查找
SELECT [DISTINCT] {* | {column [, column] ...} [FROM table_name] [WHERE ...] [ORDER BY column [ASC | DESC], ...]LIMIT ...
<1> 全列查询
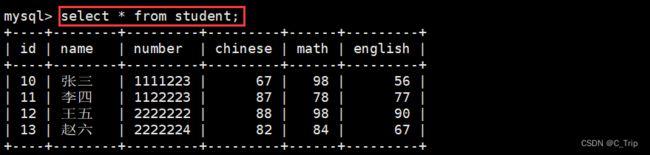
- 查询的列越多,意味着需要传输的数据量越大;
- 可能会影响到索引的使用。
<2> 指定列查询
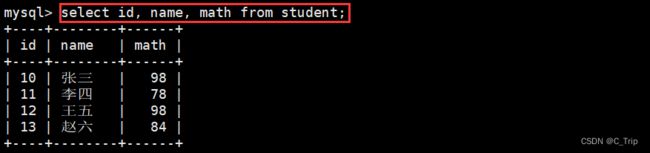
查询字段为表达式

为查询结果指定别名
查询结果去重
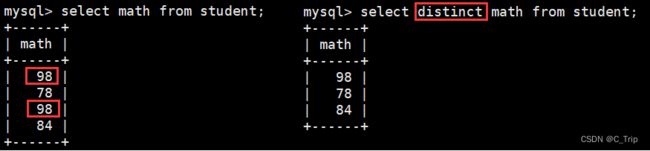
<3> where条件
比较运算符:
| 运算符 | 说明 |
|
>, >=, <, <=
|
大于,大于等于,小于,小于等于 |
|
=
|
等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
|
<=>
|
等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
|
!=, <>
|
不等于 |
|
BETWEEN a0 AND a1
|
范围匹配,[a0, a1],如果 a0 <= value <= a1,返回 TRUE(1) |
|
IN (option, ...)
|
如果是 option 中的任意一个,返回 TRUE(1) |
|
IS NULL
|
是 NULL |
|
IS NOT NULL
|
不是 NULL |
|
LIKE
|
模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符:
| 运算符 | 说明 |
|
AND
|
多个条件必须都为 TRUE(1) ,结果才是 TRUE(1)
|
|
OR
|
任意一个条件为 TRUE(1), 结果为 TRUE(1)
|
|
NOT
|
条件为 TRUE(1) ,结果为 FALSE(0)
|
实例:
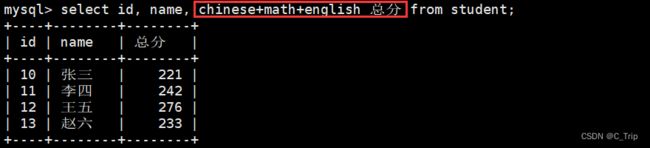
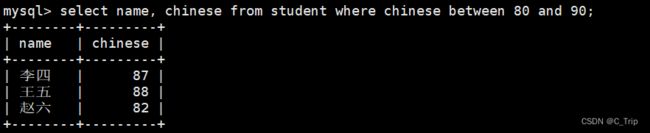
select name, chinese from student where chinese between 80 and 90;select name, chinese from student where chinese >= 80 and chinese <=90;
姓李的同学及李某同学
select name from student where name like '李%';
select name from student where name like '李_'; _ 匹配严格的一个任意字符

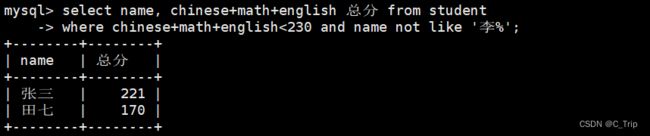
select name, chinese+math+english 总分 from student where chinese+math+english<230 and name not like '李%';
说明:
- 这里where条件筛选的时候不能用别名来进行筛选,因为where条件会先执行在此之前还没有进行起别名。
结果排序
select name, chinese, math, english from student order by math desc, english asc, chinese asc;
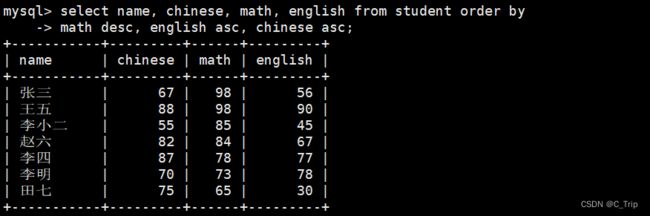
我们看到好像只有数学成绩是按照我们设定的顺序来排的,是因为多字段排序,排序优先级随书写顺序 。
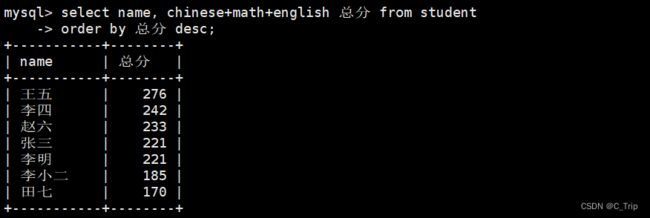
select name, chinese+math+english 总分 from student order by 总分 desc;
-
ORDER BY 中可以使用表达式也可以可以使用列别名
<4> 筛选分页结果
-- 起始下标为 0-- 从 0 开始,筛选 n 条结果SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;-- 从 s 开始,筛选 n 条结果SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n;-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;
3、表的修改
UPDATE table_name SET column = expr [, column = expr ...] [WHERE ...] [ORDER BY ...] [LIMIT ...]
实例:
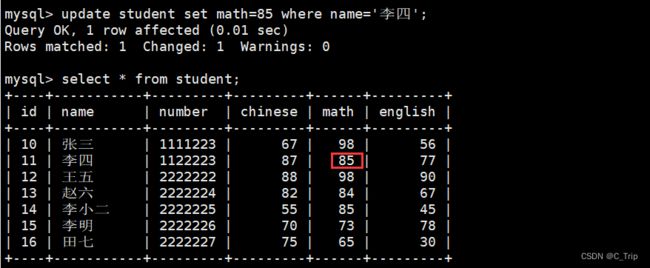
将李四的数学成绩改为85分
update student set math=85 where name='李四';
4、表的数据删除
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]
实例:
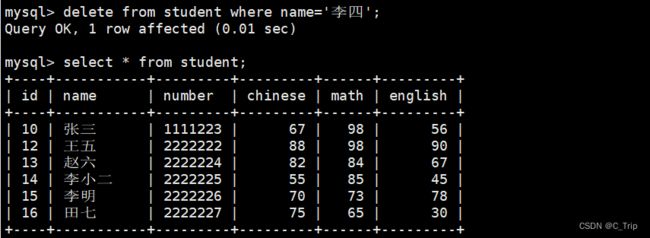
删除李四的数据
delete from student where name='李四';
删除整张表的数据
DELETE FROM test(表名);
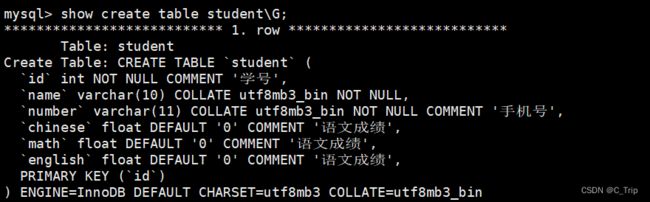
5、查看表结构
SHOW CREATE TABLE 表名\G;
6、插入查询结果
INSERT INTO table_name [(column [, column ...])] SELECT ...
实例:
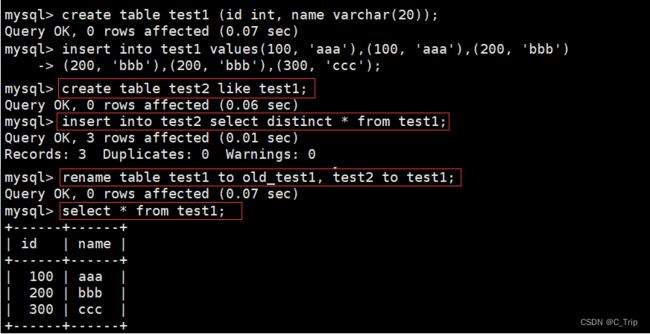
将test1表中的数据进行去重
思路:先将test1表中的数据去重插入到test2表中,在将test2的表名改为test1
create table test1 (id int, name varchar(20));
insert into test1 values(100, 'aaa'),(100, 'aaa'),(200, 'bbb'),(200, 'bbb'),(200, 'bbb'),(300, 'ccc');
create table test2 like test1;insert into test2 select distinct * from test1;
rename table test1 to old_test1, test2 to test1;
select * from test1;