【参考黑马のOpencv图像处理学习笔记】opencv图像处理几何变换
学习目标
- 掌握图像的缩放,平移,旋转等
- 了解数字图像的仿射变换和透射变换
1 图像缩放
缩放是对图像的大小进行调整,即使图像放大或缩小。
-
API
cv2.resize(src,dsize,fx=0,fy=0,interpolation=cv2.INTER_LINEAR)
参数:
-
src : 输入图像
-
dsize: 绝对尺寸,直接指定调整后图像的大小
-
fx,fy: 相对尺寸,将dsize设置为None,然后将fx和fy设置为比例因子即可
-
interpolation:插值方法
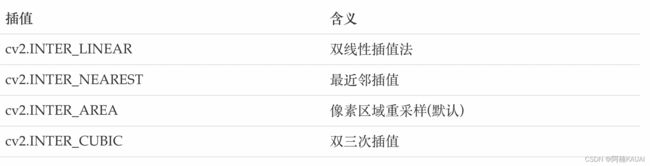
2.参考代码
import cv2 as cv
import matplotlib.pyplot as plt
# 1. 读取图片
img1 = cv.imread("1.jpg")
# 2.图像缩放
# 2.1 绝对尺寸
rows,cols = img1.shape[:2]
res = cv.resize(img1,(2*cols,2*rows),interpolation=cv.INTER_CUBIC)
# 2.2 相对尺寸
res1 = cv.resize(img1,None,fx=0.5,fy=0.5)
# 3 图像显示
# 3.1 使用opencv显示图像(不推荐)
cv.imshow("orignal",img1)
cv.imshow("enlarge",res)
cv.imshow("shrink)",res1)
cv.waitKey(0)
# 3.2 使用matplotlib显示图像
fig,axes=plt.subplots(nrows=1,ncols=3,figsize=(10,8),dpi=100)
axes[0].imshow(res[:,:,::-1])
axes[0].set_title("enlarge")
axes[1].imshow(img1[:,:,::-1])
axes[1].set_title("orignal")
axes[2].imshow(res1[:,:,::-1])
axes[2].set_title("shrink")
plt.show()3.效果图

2 图像平移
图像平移将图像按照指定方向和距离,移动到相应的位置。
- API
cv.warpAffine(img,M,dsize)
参数:
-
img: 输入图像
-
M: 2*∗3移动矩阵
对于(x,y)处的像素点,要把它移动到(x+t_x , y+t_yx+tx,y+ty)处时,M矩阵应如下设置:

注意:将MM设置为np.float32类型的Numpy数组。
-
dsize: 输出图像的大小
注意:输出图像的大小,它应该是(宽度,高度)的形式。请记住,width=列数,height=行数。
-
示例
需求是将图像的像素点移动(50,100)的距离:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 1. 读取图像
img1 = cv.imread("1.jpg")
# 2. 图像平移
rows,cols = img1.shape[:2]
M = M = np.float32([[1,0,100],[0,1,50]])# 平移矩阵
dst = cv.warpAffine(img1,M,(cols,rows))
# 3. 图像显示
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(10,8),dpi=100)
axes[0].imshow(img1[:,:,::-1])
axes[0].set_title("1")
axes[1].imshow(dst[:,:,::-1])
axes[1].set_title("2")
plt.show()效果图展示:

3 图像旋转
图像旋转是指图像按照某个位置转动一定角度的过程,旋转中图像仍保持这原始尺寸。图像旋转后图像的水平对称轴、垂直对称轴及中心坐标原点都可能会发生变换,因此需要对图像旋转中的坐标进行相应转换。
那图像是怎么进行旋转的呢?如下图所示:
 假设图像逆时针旋转\thetaθ,则根据坐标转换可得旋转转换为:
假设图像逆时针旋转\thetaθ,则根据坐标转换可得旋转转换为:
其中:
带入上面公式,有:

也可以写成:

同时我们要修正原点的位置,因为原图像中的坐标原点在图像的左上角,经过旋转后图像的大小会有所变化,原点也需要修正。
假设在旋转的时候是以旋转中心为坐标原点的,旋转结束后还需要将坐标原点移到图像左上角,也就是还要进行一次变换。
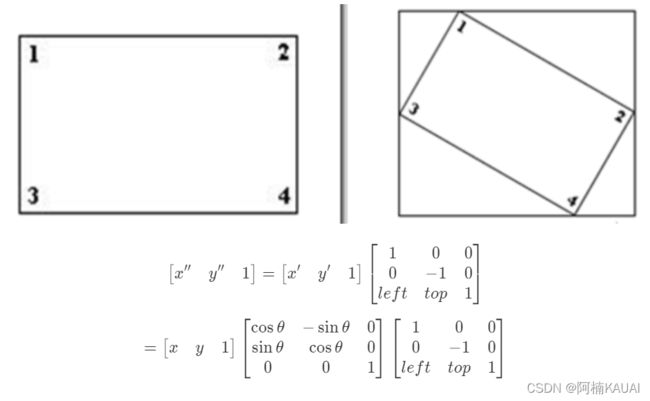
在OpenCV中图像旋转首先根据旋转角度和旋转中心获取旋转矩阵,然后根据旋转矩阵进行变换,即可实现任意角度和任意中心的旋转效果。
1.API
cv2.getRotationMatrix2D(center, angle, scale)
参数:
- center:旋转中心
- angle:旋转角度
- scale:缩放比例
返回:
-
M:旋转矩阵
调用cv.warpAffine完成图像的旋转
2.参考代码
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 1 读取图像
img = cv.imread("1.jpg")
# 2 图像旋转
rows,cols = img.shape[:2]
# 2.1 生成旋转矩阵
M = cv.getRotationMatrix2D((cols/2,rows/2),90,1)
# 2.2 进行旋转变换
dst = cv.warpAffine(img,M,(cols,rows))
# 3 图像展示
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(10,8),dpi=100)
axes[0].imshow(img[:,:,::-1])
axes[0].set_title("yuantu")
axes[1].imshow(dst[:,:,::-1])
axes[1].set_title("xuanzhuanhou")
plt.show()效果图:

4 仿射变换
图像的仿射变换涉及到图像的形状位置角度的变化,是深度学习预处理中常到的功能,仿射变换主要是对图像的缩放,旋转,翻转和平移等操作的组合。
那什么是图像的仿射变换,如下图所示,图1中的点1, 2 和 3 与图二中三个点一一映射, 仍然形成三角形, 但形状已经大大改变,通过这样两组三点(感兴趣点)求出仿射变换, 接下来我们就能把仿射变换应用到图像中所有的点中,就完成了图像的仿射变换。
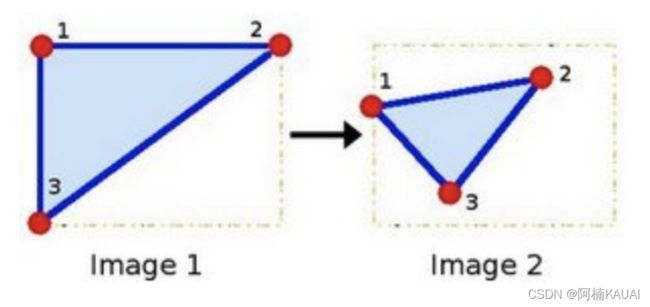
在OpenCV中,仿射变换的矩阵是一个2×3的矩阵,

其中左边的2×2子矩阵A是线性变换矩阵,右边的2×1子矩阵B是平移项:

对于图像上的任一位置(x,y),仿射变换执行的是如下的操作:

需要注意的是,对于图像而言,宽度方向是x,高度方向是y,坐标的顺序和图像像素对应下标一致。所以原点的位置不是左下角而是右上角,y的方向也不是向上,而是向下。
在仿射变换中,原图中所有的平行线在结果图像中同样平行。为了创建这个矩阵我们需要从原图像中找到三个点以及他们在输出图像中的位置。然后cv2.getAffineTransform 会创建一个 2x3 的矩阵,最后这个矩阵会被传给函数 cv2.warpAffine。
参考代码:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 1 图像读取
img = cv.imread("1.jpg")
# 2 仿射变换
rows,cols = img.shape[:2]
# 2.1 创建变换矩阵
pts1 = np.float32([[50,50],[200,50],[50,200]])
pts2 = np.float32([[100,100],[200,50],[100,250]])
M = cv.getAffineTransform(pts1,pts2)
# 2.2 完成仿射变换
dst = cv.warpAffine(img,M,(cols,rows))
# 3 图像显示
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(10,8),dpi=100)
axes[0].imshow(img[:,:,::-1])
axes[0].set_title("yuantu")
axes[1].imshow(dst[:,:,::-1])
axes[1].set_title("jieguo")
plt.show()效果图展示:

5 透射变换
透射变换是视角变化的结果,是指利用透视中心、像点、目标点三点共线的条件,按透视旋转定律使承影面(透视面)绕迹线(透视轴)旋转某一角度,破坏原有的投影光线束,仍能保持承影面上投影几何图形不变的变换。

它的本质将图像投影到一个新的视平面,其通用变换公式为:

其中,(u,v)是原始的图像像素坐标,w取值为1,(x=x'/z',y=y'/z')是透射变换后的结果。后面的矩阵称为透视变换矩阵,一般情况下,我们将其分为三部分:
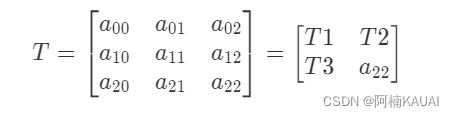
其中:T1表示对图像进行线性变换,T2对图像进行平移,T3表示对图像进行投射变换,a_{22}a22一般设为1.
在opencv中,我们要找到四个点,其中任意三个不共线,然后获取变换矩阵T,再进行透射变换。通过函数cv.getPerspectiveTransform找到变换矩阵,将cv.warpPerspective应用于此3x3变换矩阵。
参考代码:
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 1 读取图像
img = cv.imread("1.jpg")
# 2 透射变换
rows,cols = img.shape[:2]
# 2.1 创建变换矩阵
pts1 = np.float32([[56,65],[368,52],[28,387],[389,390]])
pts2 = np.float32([[100,145],[300,100],[80,290],[310,300]])
T = cv.getPerspectiveTransform(pts1,pts2)
# 2.2 进行变换
dst = cv.warpPerspective(img,T,(cols,rows))
# 3 图像显示
fig,axes=plt.subplots(nrows=1,ncols=2,figsize=(10,8),dpi=100)
axes[0].imshow(img[:,:,::-1])
axes[0].set_title("yuantu")
axes[1].imshow(dst[:,:,::-1])
axes[1].set_title("jieguo")
plt.show()效果展示图:

6 图像金字塔
图像金字塔是图像多尺度表达的一种,最主要用于图像的分割,是一种以多分辨率来解释图像的有效但概念简单的结构。
图像金字塔用于机器视觉和图像压缩,一幅图像的金字塔是一系列以金字塔形状排列的分辨率逐步降低,且来源于同一张原始图的图像集合。其通过梯次向下采样获得,直到达到某个终止条件才停止采样。
金字塔的底部是待处理图像的高分辨率表示,而顶部是低分辨率的近似,层级越高,图像越小,分辨率越低。
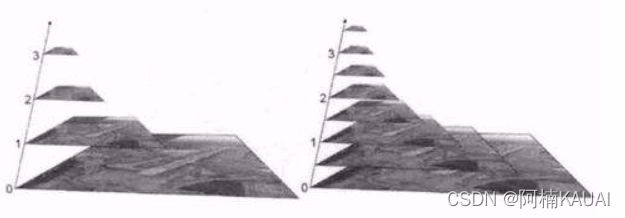
1.API
cv.pyrUp(img) #对图像进行上采样
cv.pyrDown(img) #对图像进行下采样
2.参考代码
import numpy as np
import cv2 as cv
import matplotlib.pyplot as plt
# 1 图像读取
img = cv.imread("1.jpg")
# 2 进行图像采样
up_img = cv.pyrUp(img) # 上采样操作
img_1 = cv.pyrDown(img) # 下采样操作
# 3 图像显示
cv.imshow('enlarge', up_img)
cv.imshow('original', img)
cv.imshow('shrink', img_1)
cv.waitKey(0)
cv.destroyAllWindows()3.效果展示图
总结
-
图像缩放:对图像进行放大或缩小
cv.resize()
-
图像平移:
指定平移矩阵后,调用cv.warpAffine()平移图像
-
图像旋转:
调用cv.getRotationMatrix2D获取旋转矩阵,然后调用cv.warpAffine()进行旋转
-
仿射变换:
调用cv.getAffineTransform将创建变换矩阵,最后该矩阵将传递给cv.warpAffine()进行变换
-
透射变换:
通过函数cv.getPerspectiveTransform()找到变换矩阵,将cv.warpPerspective()进行投射变换
-
金字塔
图像金字塔是图像多尺度表达的一种,使用的API:
cv.pyrUp(): 向上采样
cv.pyrDown(): 向下采样