深度学习初探/02-Pytorch知识/04-Tensor维度变换
深度学习初探/02-Pytorch知识/04-Tensor维度变换
一、重塑
两者完全一致,reshape是pytorch为了保持与numpy的一致性而出现的
缺陷:可能会破坏原有数据
# 随机生成4幅MNIST数据集标准的手写数字图像
a = torch.rand(4, 1, 28, 28)
# 调用numpy的prod函数,打印a的实际大小(各个维度的乘积)
print(np.prod(a.size()))
# 分别使用view和reshape进行维度变换操作
print(a.view(4, 1*28*28).shape)
print(a.reshape(4*1*28, 28).shape)
print(a.view(4, 1*28*28))
print(np.prod(a.view(4, 1*28*28).size()))
Out:
3136
torch.Size([4, 784])
torch.Size([112, 28])
tensor([[0.9845, 0.5994, 0.2349, ..., 0.4471, 0.5996, 0.8415],
[0.6199, 0.9004, 0.3659, ..., 0.0536, 0.0146, 0.3089],
[0.4495, 0.2574, 0.0072, ..., 0.2845, 0.8489, 0.1164],
[0.9994, 0.6759, 0.3826, ..., 0.4474, 0.5850, 0.6024]])
3136
reshape/view的时候一定要保持整个数据的总量(各个dimension的乘积)不变,否则会报错:
a = torch.rand(4, 1, 28, 28)
print(a.reshape(4, 783))

二、增维和降维
1、squeeze
不对tensor进行修改,仅在使用时减少维度
position可正可负,具体含义如下:
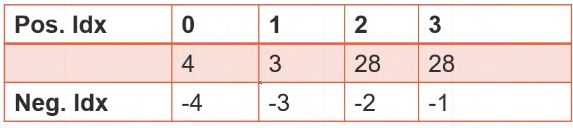
b = torch.rand([1, 32, 1, 1])
print(b.shape)
# 把所有length==1的dimension全部降维消除
print(b.squeeze().shape)
# 只降第0个dimension
print(b.squeeze(0).shape)
# 只降最后一个dimension
print(b.squeeze(-1).shape)
2、unsqueeze
不对tensor进行修改,仅在使用时增加维度
# 随机生成4幅MNIST数据集标准的手写数字图像
a = torch.rand(4, 1, 28, 28)
In: print(a.unsqueeze(0).shape) # 在position == 0 处插入一个维度
Out: torch.Size([1, 4, 1, 28, 28])
# 负数也可以,但尽量不要用,容易引起混淆
In: print(a.unsqueeze(-1).shape) # 在原tensor的最后一个维度之后,插入一个维度
Out: torch.Size([4, 1, 28, 28, 1])
应用场景:cv中给图像添加一维的偏置值,需要对偏置值进行unsqueeze
b =torch.rand(32) # 给channel的偏置值bias
f = torch.rand(4, 32, 14, 14) # batch=4, channel=32, pic_Size=14x14
# 改变b的维度,使b+f能够实现
b = b.unsqueeze(0).unsqueeze(2).unsqueeze(3)
print(b.shape)
三、维度内延展
区别:
expand【推荐使用】 ⇒ \Rightarrow ⇒ 只改变理解方式,不改变tensor,不会主动copy数据;
repeat ⇒ \Rightarrow ⇒ 实实在在地改变了数据,会对扩展部分进行copy
只有dimension相同的情况下才能进行延展
1、expand
使用时直接给出各维度的目标长度即可
In: b = torch.rand([1, 32, 1, 1])
print(b.shape)
Out: torch.Size([1, 32, 1, 1])
In: print(b.expand([4, 32, 14, 14]).shape)
Out: torch.Size([4, 32, 14, 14])
如果想让某维度保持不变,则填【-1】
In: print(b.expand([-1, 32, 14, -1]).shape)
Out: torch.Size([1, 32, 14, 1])
2、repeat
使用时,给出【扩展的倍数】,而不能直接给出各维度的目标长度
In: print(b.shape)
Out: torch.Size([1, 32, 1, 1])
In: print(b.repeat([4, 1, 14, 14]).shape)
Out: torch.Size([4, 32, 14, 14])
In: print(b.repeat([4, 32, 14, 14]).shape)
Out: torch.Size([4, 1024, 14, 14])
四、矩阵的转置
1、 .t
b = torch.rand([3, 4])
In: print(b)
Out: tensor([[0.8251, 0.8791, 0.5659, 0.1707],
[0.3601, 0.4733, 0.8213, 0.9446],
[0.7641, 0.7162, 0.4469, 0.2046]])
In: print(b.t())
Out: tensor([[0.8251, 0.3601, 0.7641],
[0.8791, 0.4733, 0.7162],
[0.5659, 0.8213, 0.4469],
[0.1707, 0.9446, 0.2046]])
PS: .t( )只适用于dimension = 2的Tensor(即矩阵)
(1)对于dimension > 2的tensor会报错:
In: b = torch.rand([3, 3, 4])
print(b.t())
报错:

(2)对于dimens == 1的tensor没有效果
In: c = torch.rand([3])
print(c)
print(c.t())
Out: tensor([0.0311, 0.7015, 0.5543])
tensor([0.0311, 0.7015, 0.5543])
五、维度交换
1、transpose
In: a = torch.rand([4, 1, 28, 28])
print(a.transpose(1, 3).shape)# 交换a的第1维度和第3维度
Out: torch.Size([4, 28, 28, 1])
注意:transpose与view的配合使用
transpose可能会导致tensor的存储方式发生变化,因此在使用view之前需要先调用contiguous函数对tensor进行连续化处理,否则会报错:
![]()
正确的做法:
a = torch.rand([4, 3, 32, 32])
a1 = a.transpose(1, 3).contiguous().view(4, 3*32*32)
print(a1.shape)
Out: torch.Size([4, 3072])