深度网络CTR建模
1. 概述
CTR预估是现如今的搜索、推荐以及广告中必不可少的一部分,CTR预估的目标是预估用户点击给定item的概率。经过这么多年的发展,CTR预估算法得到了较大的改进,从开始的线性模型LR,发展到带有特征交叉的FM算法,随着深度网络的发展,CTR预估也逐渐发展到如今的基于深度模型的CTR预估,期间出现了较大一批成功在业界得到广泛应用的算法模型,如Wide & Deep,DeepFM,DIN,DIEN等等。
近年来深度学习技术在NLP以及CV领域得到了充分的发展,提出了很多优秀的模型结构,如在NLP领域,从MLP到CNN,RNN,LSTM,GRU,再到现如今被广泛研究的基于Transformer的算法。在CTR预估方面,相比较于NLP和CV领域,其特征相对是大规模的,且是稀疏的,为了能够使用深度网络对CTR数据建模,需要在结构上做相应的调整,使得数据能够适应深度网络模型。
2. 深度CTR建模
2.1. Base模型
参考[1]中给出了深度CTR预估的Base模型结构,如下图所示:

在Base模型结构中,主要包括了输入层,Embedding层,全连接层以及输出层。
2.2. 输入层
上述的Base模型中,输入层包括四个输入模块,分别为:用户画像特征(User Profile Features),用户行为特征(User Behaviors),候选Ad特征(Candidate Ad)和上下文特征(Context Features)。
对于User Profile Features,通常包含了诸如请求用的性别,年龄,购买力,手机品牌等一些静态的特征,还包括请求用户的一些统计信息,如月度点击数,月度访问数,月度使用时间等;对于User Behaviors特征和Candidate Ad特征,通常可以包含商品的一些静态特征,如id,标题分词,标题tagging,类目,品牌,价格等,还可以包含一些统计的特征,如历史统计的CTR,7日PV,7日UV等;对于Context Features,通常是客户端带的信息,在用户授权的前提下可以直接获取,比如请求时间、用户手机品牌、手机型号、操作系统、当前网络状态(3g/4g/wifi)、用户渠道等实时属性特征以及之间的 cross 特征。
不同类型的特征需要采用不同的处理方式。根据特征的形式的不同,可以将特征分为三类,分别为类别特征(Categorical),数值特征(Numeric)和多值特征(Multi-valued)[2]。
Categorical类特征,一般是离散的值,特征中只包含一个值,典型的如性别特征。对于Categorical类特征,处理方法通常是使用one-hot编码,将其转换成离散的表示,如“gender=Female”,通过one-hot编码后,其特征编码为 [ 0 , 1 ] \left [ 0,1 \right ] [0,1]。
Numeric类特征,主要有两种处理的方法,一种方式是对其离散化,将其转化成Categorical类特征的处理;另一种是对其进行归一化,将其归一化到 [ 0 , 1 ] \left [ 0,1 \right ] [0,1]区间上。如“age=33”,经过离散化和one-hot编码后,其特征编码为 [ 0 , 0 , 0 , 1 , 0 , 0 , 0 , 0 , 0 , 0 ] \left [ 0,0,0,1,0,0,0,0,0,0 \right ] [0,0,0,1,0,0,0,0,0,0]。
Multi-valued类特征,与Categorical类特征的处理类似,只是在Categorical类特征经过one-hot编码后只有一维的值为 1 1 1,而在Multi-valued类特征经过编码后,有多维的值为 1 1 1。
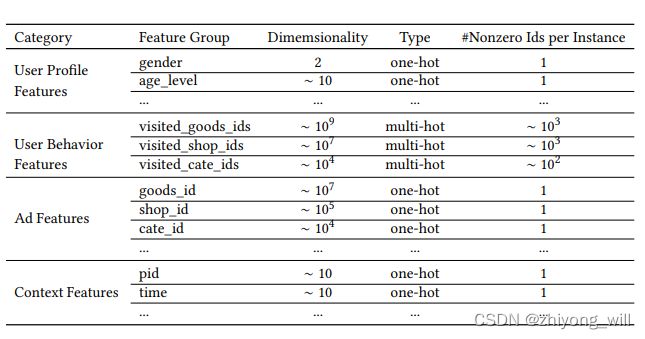
以下图[1]为例,经过转换后的对照关系如下图所示:
对于Numeric类特征,也有不经过Embedding的处理方法,如参考[3]中的ranking模型,直接对其对数值上的转换后与Embedding结果concat在一起,如下图所示:
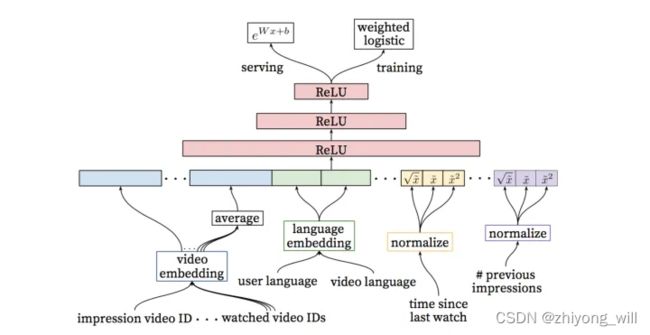
上图中的特征time since last watch与特征previous impressions可以看成是Numeric类特征。
2.3. Embedding层
Embedding层的作用是把高维稀疏的特征转化成低维的embedding的稠密表达,以满足深度网络的要求。一般处理这种转换关系是初始化一个lookup table,这个lookup table是一个矩阵(可学习的),矩阵的行数为上述经过编码后的总维数,矩阵的列数是低维稠密向量的维数。
假设输入经过编码后总维数为 10000 10000 10000维,那么lookup table就有 10000 10000 10000行,其中第 i i i行是第 i i i维对应的embedding。然而对于Multi-valued类特征,一组特征通常编码后会出现多维值为 1 1 1的情况,如得到的embedding结果为 { e i 1 , e i 2 , ⋯ , e i k } \left \{ e_{i_1},e_{i_2},\cdots ,e_{i_k} \right \} {ei1,ei2,⋯,eik},通常采用sum或者avg的方法将其转换成一维:
e i = s u m ( e i 1 , e i 2 , ⋯ , e i k ) e_i=sum\; \left ( e_{i_1},e_{i_2},\cdots ,e_{i_k} \right ) ei=sum(ei1,ei2,⋯,eik)
2.4. 全连接层和输出层
全连接层和输出层是多层感知器(multiple layer perceptron, MLP)中的基本结构,定义了第 l l l层到第 l + 1 l+1 l+1层的非线性映射关系,它的主要作用是使模型具备非线性拟合能力。假设 x l x_l xl为第 l l l层的输入向量, x l + 1 x_{l+1} xl+1为第 l + 1 l+1 l+1层的输出向量, W l + 1 W_{l+1} Wl+1为连接第 l l l层到第 l + 1 l+1 l+1层的权重矩阵, b l + 1 b_{l+1} bl+1为 l + 1 l+1 l+1层的偏置向量, f f f为非线性激活函数(sigmoid,tanh,relu等),那么 x l + 1 x_{l+1} xl+1和 x l x_l xl的关系为:
x l + 1 = f ( W l + 1 x l + b l + 1 ) x_{l+1}=f\left ( W_{l+1}x_l+b_{l+1} \right ) xl+1=f(Wl+1xl+bl+1)
2.5. 损失函数
在CTR建模过程中,通常使用交叉熵(cross-entropy)作为模型的损失函数,其具体形式如下所示:
L = − 1 N ∑ ( y ^ , y ) ∈ D ( y l o g y ^ + ( 1 − y ) l o g ( 1 − y ^ ) ) L=-\frac{1}{N}\sum_{\left ( \hat{y},y \right )\in \mathbb{D} }\left ( ylog\hat{y}+\left ( 1-y \right )log\left ( 1-\hat{y} \right ) \right ) L=−N1(y^,y)∈D∑(ylogy^+(1−y)log(1−y^))
其中, D \mathbb{D} D是所有训练数据的集合, y y y和 y ^ \hat{y} y^表示的是样本真实的标签和CTR预估的结果,且
y ^ = σ ( ϕ ( x ) ) \hat{y}=\sigma \left ( \phi \left ( x \right ) \right ) y^=σ(ϕ(x))
其中, σ ( ⋅ ) \sigma \left ( \cdot \right ) σ(⋅)是Sigmoid函数。
3. 深度CTR模型在问题求解上的发展
参考[4]中给出了近年来深度CTR模型本身的发展,详细介绍了每一个模型在先前工作上的一些改进,下面是我在阅读一些文章后,结合参考[4]给出的深度CTR模型在问题求解思路上的发展,具体如下图所示:

上图仅代表目前我了解到的文章,后期看到新的文章或思路会继续更新该图。
如上图所示,在基于Base DNN的基础上,目前我了解到的在求解思路上的模型优化主要有四个方面:
- 模型融合
- 特征交叉
- 序列建模
- 加入Attention
- 多目标
模型融合主要是指在DNN的基础上,加入之前已经成功应用在CTR问题求解的线性模型LR,典型的模型结构是Wide&Deep[5],当然在Wide&Deep的基础上提出了很多模型层面的优化,分为在Wide侧,如增加交叉特征的DCN[6],DeepFM[7]等,在Deep侧的NFM[8]。
特征交叉是指在DNN的Embedding层的基础上,再增加一个特征的交叉层,能够进一步挖掘出对CTR预估有效的交叉特征,在众多的实验中,也能看出交叉特征对于CTR结果的重要性,这其中比较典型的如PNN[9]。
序列建模是指对于用户的行为序列建模,上述的方法都没有利用用户行为上的时序关系,基于序列建模,能够更好地挖掘出用户的兴趣,这其中比较典型的如基于GRU的时序建模方法GRU4Rec[10],以及基于Transformer的BST[11]。
加入Attention是指在用户行为与目标之间必定会存在一定的关系,加入Attention旨在挖掘出用户与目标之间的相关兴趣,有助于建模对目标的点击概率,其中比较典型的算法如DIN[1],结合序列建模,建模用户兴趣的演化过程,又衍生出DIEN[12]以及DSIN[13]。
多目标指的是在同一个模型中训练多个目标,CTR建模中通常会与CVR模型一起,模型结构完全一致,只是训练目标不一致。最简单的方法是分别用一个模型训练CTR和CVR,也可以一起训练,采用多目标的框架结构,在多目标模型中,比较典型的是MMoE[14]。
4. 总结
深度学习模型在CTR问题上的探索还在继续,在CTR建模上也有更多更复杂的模型出现,在模型迭代的过程中,挖掘出更多有用的特征也是一条不断探索的道路。
参考文献
[1] Zhou G, Zhu X, Song C, et al. Deep interest network for click-through rate prediction[C]//Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2018: 1059-1068.
[2] Zhu J, Liu J, Yang S, et al. Open Benchmarking for Click-Through Rate Prediction[C]//Proceedings of the 30th ACM International Conference on Information & Knowledge Management. 2021: 2759-2769.
[3] Covington P, Adams J, Sargin E. Deep neural networks for youtube recommendations[C]//Proceedings of the 10th ACM conference on recommender systems. 2016: 191-198.
[4] 谷歌、阿里、微软等10大深度学习CTR模型最全演化图谱【推荐、广告、搜索领域】
[5] Cheng H T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st workshop on deep learning for recommender systems. 2016: 7-10.
[6] Wang R, Fu B, Fu G, et al. Deep & cross network for ad click predictions[M]//Proceedings of the ADKDD’17. 2017: 1-7.
[7] Guo H, Tang R, Ye Y, et al. DeepFM: a factorization-machine based neural network for CTR prediction[J]. arXiv preprint arXiv:1703.04247, 2017.
[8] He X, Chua T S. Neural factorization machines for sparse predictive analytics[C]//Proceedings of the 40th International ACM SIGIR conference on Research and Development in Information Retrieval. 2017: 355-364.
[9] Qu Y, Cai H, Ren K, et al. Product-based neural networks for user response prediction[C]//2016 IEEE 16th International Conference on Data Mining (ICDM). IEEE, 2016: 1149-1154.
[10] Hidasi B, Karatzoglou A, Baltrunas L, et al. Session-based recommendations with recurrent neural networks[J]. arXiv preprint arXiv:1511.06939, 2015.
[11] Chen Q, Zhao H, Li W, et al. Behavior sequence transformer for e-commerce recommendation in alibaba[C]//Proceedings of the 1st International Workshop on Deep Learning Practice for High-Dimensional Sparse Data. 2019: 1-4.
[12] Zhou G, Mou N, Fan Y, et al. Deep interest evolution network for click-through rate prediction[C]//Proceedings of the AAAI conference on artificial intelligence. 2019, 33(01): 5941-5948.
[13] Feng Y, Lv F, Shen W, et al. Deep session interest network for click-through rate prediction[J]. arXiv preprint arXiv:1905.06482, 2019.
[14] Ma J, Zhao Z, Yi X, et al. Modeling task relationships in multi-task learning with multi-gate mixture-of-experts[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 1930-1939.