深度学习在CTR预估的应用
本文是视频学习2017年底Archsummit全球架构师峰会演讲内容所做笔记
CTR(Cleick-Throug'xh Rate Prediction)点击率预估
目录
1. 当深度学习遇到CTR预估
2. 传统主流CTR预估方法
3. 深度学习基础模型
4. 深度学习CTR预估模型
5.互联网公司深度学习CTR案例
1. 当深度学习遇到CTR预估
深度学习:各个领域的成功
人脸识别、物体识别、语音识别、机器翻译、风格转换、图片生成,等等。

目前人工智能非常热,我们可以思考一下,人工智能为什么这么热?它背后有什么支撑?泡沫大不大?在这是一个值得深思的点。其实背后的支撑就是深度学习。为什么深度学习是支撑这次人工智能热潮的基石和背景?算法。与深度学习相对应的是传统的算法。为什么深度学习之前人工智能没有现在这么热?做机器学习算法,从写学术论文到真实能够落地应用,有一条基准线,例如准确率达到85%。传统方法的问题是准确率会在85%附近振动,这种情况很难应用于实际,因为写学术论文用的测试集很干净,而实际中的数据却比较复杂,效果会比较差,所以传统方法很难落地。深度学习崛起之后,主要在图像、音频这两个领域贡献突出,与传统方法比较有质的提升,例如准确度可以达到90%+,可以落地。
上图中上面三个为一组,代表的是图片、视频、音频领域。机器翻译代表的是NLP,深度学习在NLP领域也是有所贡献使之准确率有所提升,但是没有前三个的提升大。
对于最后一幅图,代表的是生成模型。人工智能相对人来说,有个缺陷,人工智不能做创造性的东西,创造力不如人类。但是我们可以想象一下。随着GAN的快速发展,完全会出现这样一个场景,比如动画片,只要我们给出故事梗概,计算机就能生成整个动画片,而不需要像现在需要一幅一幅去画。当然现在还做不到,但是几年之后还是有可能的。所以说生成模型还是一个比较有发展前景的方向。
CTR任务的应用

CTR是什么?举例:比如给定一个用户user,给定一个商品product,给定场景,什么情景下,此人看到了这个商品,CTR的任务就是来告诉我,用户会不会来买我的这个商品,或者买商品的概率有多高,或者你给用户推荐这个商品,比如电影,用会不会看,看的概率多大。
上图中,第一个,计算广告,目前的大型互联网公司广告部门做的就是CTR。第二个,推荐系统,推荐系统也可以被转化为一个CTR任务,一般做推荐系统用的方法有矩阵分解、item-based KNN、user-based KNN等。第三个,信息流排序,比如百度、头条、微博,都做信息流。例如微博,你关注了很多人,他们发了很多信息,那么我优先给你展示哪些,你可能会点它。
CTR任务的特点
- 大量离散特征
- 大量高维度稀疏特征
- 特征工程:特征组合对于效果非常关键(例如:特征1:双11,特征2:女性)
2. 传统主流CTR预估方法
做CTR预估常用的方法主要有:逻辑回归(LR)、GBDT树模型、LR+GBDT、FM模型、因子分解机、深度学习模型。
线性模型:思路及问题

线性模型,不仅是CTR预估,应该是所有机器学习模型中最简单的方法。公式如图。对应图中蓝黑色直线。
此处LR模型在线性模型的基础上套用了Sigmoid,将结果值压缩到[0,1],最终结果值越高,越有可能购买我们的商品,得分越低,越不可能买。
目前很多公司线上还是LR模型,因为它有很多优点是其他模型不具有的:简单、可解释(加个特征只要塞个新值就行)、易扩展、效率高、易并行。
缺点:难以捕获特征组合。(没有组合,没有发生两个特征之间的关系)
线性模型改进:加入特征组合(改进难以捕获特征组合)

优势:引入两两特征组合
缺点:泛化能力弱
FM模型(改进泛化能力弱)
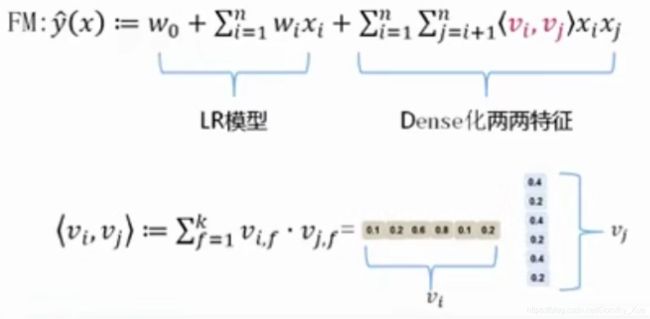
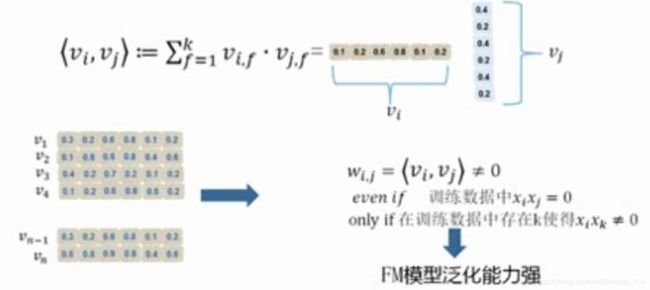
GBDT模型
Gradient Boosting Decision Tree:迭代的决策树算法,多棵决策树构成,所有子树的决策值累加得出预测值。GBDT有很多名称,还被称为:MART(Multiple Additive Regression Tree)、GBRT(Gradient Boosting Regression Tree)、TreeLink等。
举例:
预测是否喜欢打游戏

LR+GBDT
Facebook在2014年提出;集成LR和GBDT各自的优势(GBDT发现有效地组合特征Feature Set;将Feature Set引入LR模型中);目前广泛使用在各大互联网公司线上系统中。
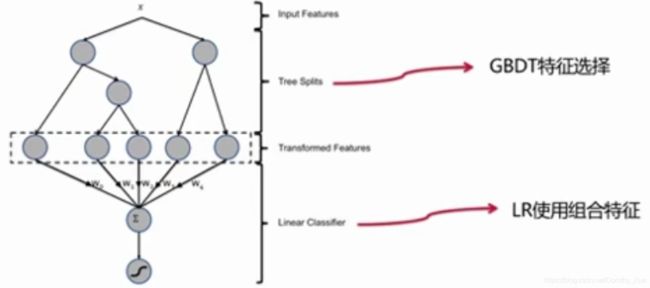
是目前效果最好的模型之一。
GBDT+FM
香港中文+百度在2014年提出;集成GBDT和FM各自的优势(GBDT发现最有效的组合特征Feature Set;将Feature Set引入FM模型中);GBFM用贪心策略选择组合特征。
我们就有一个问题:FM任意两个特征已经组合,为什么要多此一举,让它再去找?答:假设FM有n个特征,组合特征就是 ,量级太大,效率太低,而且中大多数特征都是无用的。而这里是用GBDT选择出有用的特征,再送到FM中,这样就能提高效率。
,量级太大,效率太低,而且中大多数特征都是无用的。而这里是用GBDT选择出有用的特征,再送到FM中,这样就能提高效率。
3. 深度学习基础模型
前向神经网络(MLP)

隐层神经元与上一层神经元的连接关系:全连接。
前向神经网络(MLP):隐层节点

隐层神经元做了什么?如上图,有两步:第一步,对输入进行加权求和;第二步,进行非线性变换。
前向神经网络(MLP):激活函数

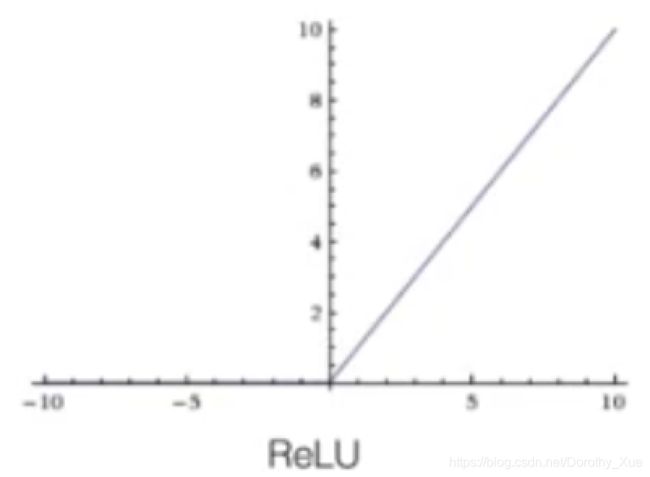
ReLU是目前最常用的激活函数。
CNN:LeNet-5整体结构
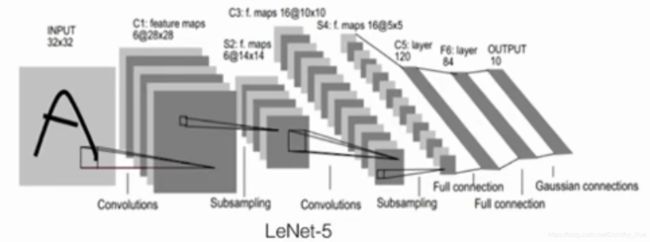
核心:卷积(Convolution),池化(Pooling)。
CNN:卷积层
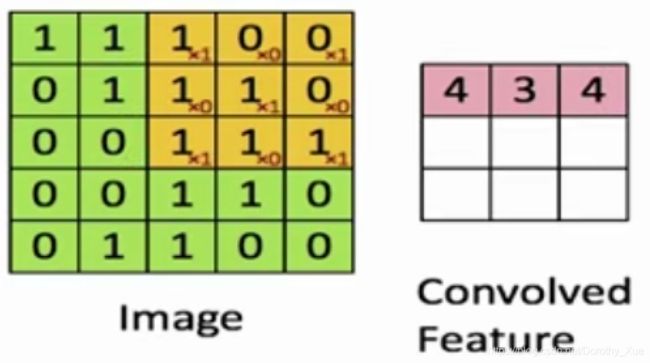
用卷积核进行加权求和+用激活函数进行非线性变换。
一个卷积核捕获一类特征,有256个卷积核就是用来捕获256类特征的。
CNN:MaxPooling层

取最大值。
减少参数量,防止过拟合。
CNN:学到了什么特征?

最底层:线段
高一层:纹理
再高层:模式
再高层:部件
再高层:物体轮廓
特点:逐层抽象
RNN
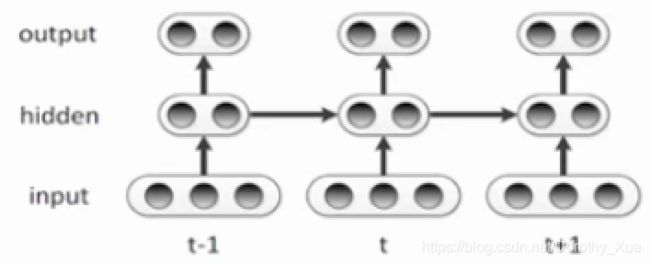
RNN主要解决序列问题,主要用于NLP。竖着看跟前向神经网络一样,不一样的就是隐层会传播,我本步的输入除了原来的输入还包括上一层隐层的输出。
双向RNN
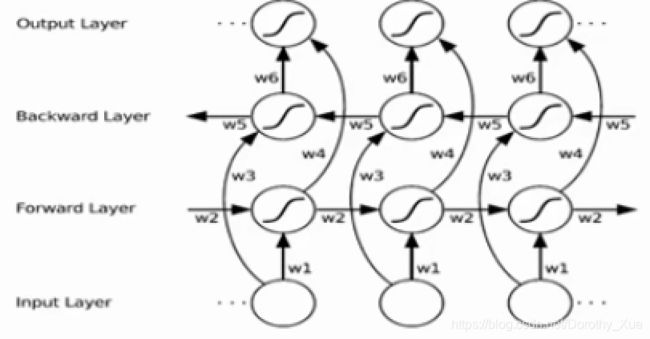
自然语言里,比如想知道这个词的词性,当前单词的前后单词都很重要,双向RNN可以提供前后双向信息,有利于判断。而单向只能提供前面的信息。
LSTM

RNN的改进。
多了3个门:输入门(控制输入信息多大尺度传入)、遗忘门(上一个隐层传入的信息量)、输出门(控制输出的信息量)。
双向深度LSTM

4. 深度学习CTR预估模型
深度学习CTR模型要解决的几个关键问题
- CTR任务特点:大量离散特征的表示问题【而神经网络天然接受连续性数值,比如图片像素值0~255】
- CTR任务特点:如何快速处理大量高维度稀疏特征?(OneHot 2 Dense)
- 特征工程:如何从手工到自动?(深度学习的优势:end to end)
- 特征工程:如何捕获和表达两两组合特征?(FM机制神经网络化)
- 特征工程:如何捕获和表达多组组合特征?(利用Deep网络)
CTR任务中的特征类型
连续特征:
- 收入,身高,体重......
- 适合DNN处理
离散特征:
- 职业,性别,毕业学校......
- 不适合DNN处理【如何将这种离散特征塞到神经网络中呢?】
离散特征如何让DNN可以处理?
直观思路:离散特征使用Onehot表达

然而,这样不行!!!

因为:用来解决日常生活中的小规模问题是可以的,而解决现实中的大规模问题是不可取的。
Onehot作为DNN输入的问题:CTR预估任务里不可行

参数规模太大了。两层就是50亿参数,难搞。
解决思路:OneHot到Dense Vector

基本思想:避免全连接,分而治之。
形成DNN结构
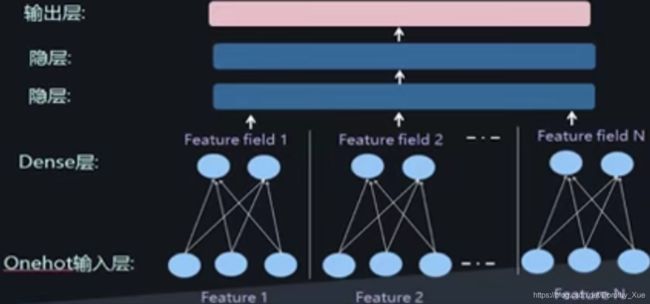
上图是深度学习做CTR任务的典型结构。
再加入连续特征
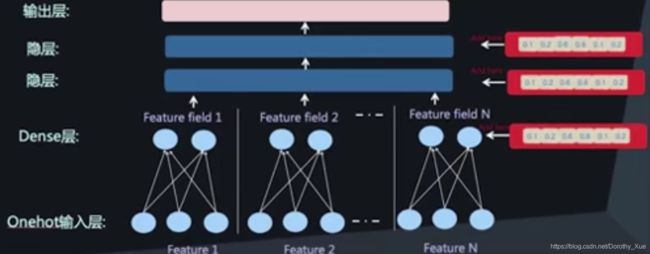
通用的深层模型结构
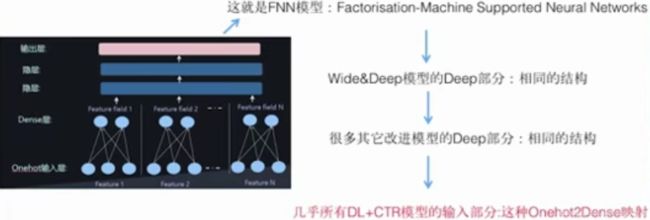
DNN输入问题解决了,但是......
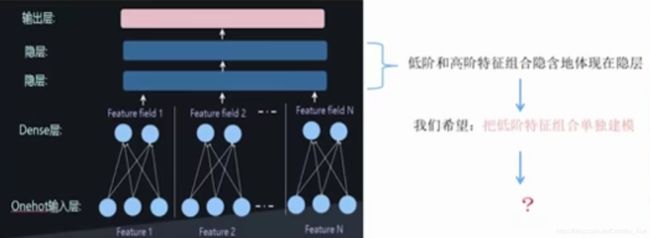
在隐层包含了特征组合,那为什么还要解决这个问题?因为做CTR我们要把低阶特(两两)征组合单独建模。
把低阶特征组合单独建模
首先需要:定义一个神经网络版的低阶特征组合模型

FM Function要体现的思想:
- Function:
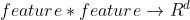
- Function具有神经网络的表现形式:和现有网络融合
- Function能够体现FM的思想:
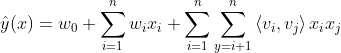
把低阶特征组合模型插入网络结构中

典型网络融合结构之一:并行结构

并行结构实例:Deep FM模型(源自华为)

并行结构实例:Deep&Cross模型
FM Function = Cross Network = ResNet
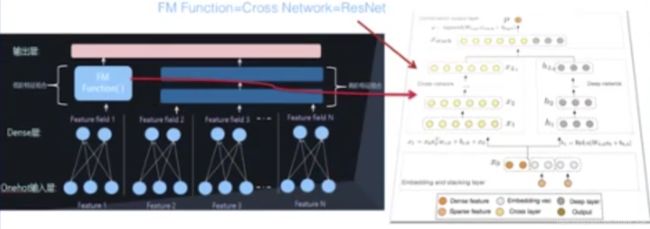
并行结构实例:Wide&Deep模型

Wide&Deep相对低级,体现在:
- Wide网络LR模型,没有FM组合
- 两个不同的输入结构
- Wide部分是手工特征+Cross特征
典型网络融合结构之二:串行结构

串行结构实例:PNN模型

串行结构实例:NFM模型

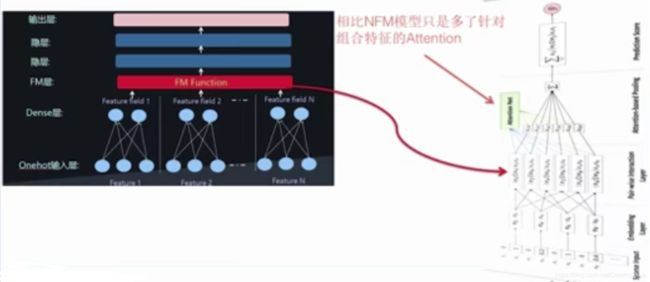
串行结构实例:AFM模型
相比NFM模型,只是多了针对组合特征的Attention。
模型训练与优化:Dense层的预训练

模型训练与优化:Deep网络隐层网络结构
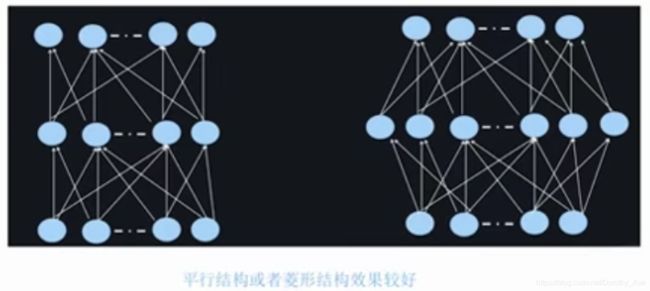
最常见的是梯形结构(从下往上神经元越来越少)。
平行结构或者菱形结构效果比较好。
模型训练与优化:Deep网络隐层的层深
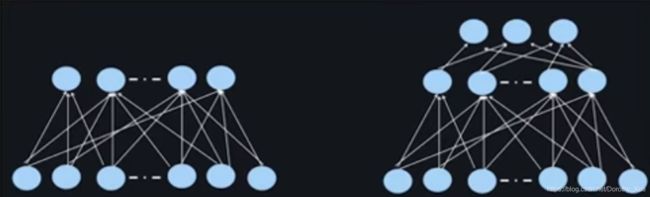
两层或三层比较常见,效果已经OK了。
5.互联网公司深度学习CTR案例
Google:Youtube视频推荐
Google 2016年工作:
- 论文:Deep Neural Networks for YouTube Recommendations
- 已上线,效果优于传统模型
主要关注:
- 视频推荐
- 深度神经网络的应用
系统结构:

非常通用的实际问题的结构,两步走:第一步:初筛(下图1),从大量数据中,比如几百万个中找出几千个有可能的被选择的。第二步:ranking,排序,精选(下图2)。


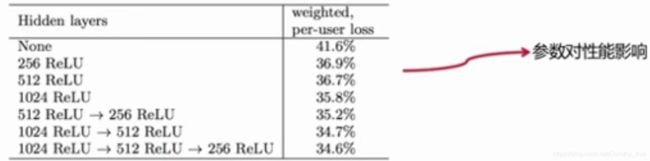
参数对性能的影响:
阿里巴巴:Deep Interest Network
阿里妈妈2017年工作:
- 论文:Deep Interest Network for Click-Through Rate Prediction
- 已上线,效果明显优于传统模型
主要关注:
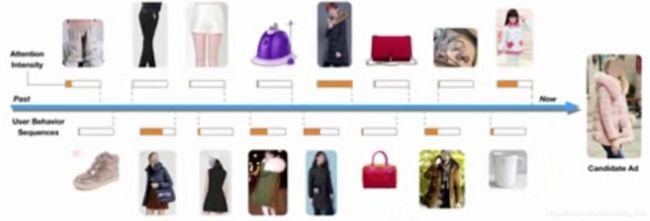
- 兴趣的多样性
- 局部激活(Local Activation)
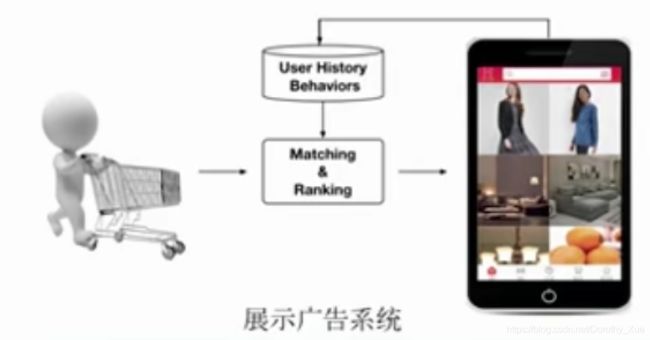
展示广告系统:
使用特征:
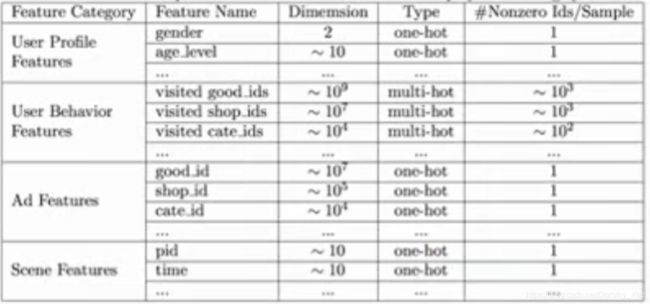
基准模型:
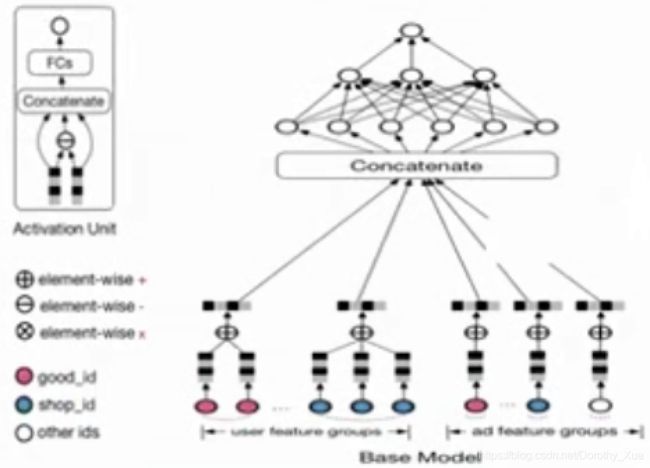
DIN模型:

局部激活(Local Activation):
京东商城:Telepath
京东2017年工作:
- 论文:Telepath: Understanding Users from a Human Vision Perspective in Large-scale Recommender Systems
- 已上线,效果明显优于传统模型
主要关注:
- 用于推荐和广告
- 融合图片和行为等各种信息
推荐系统整体架构图:

Telepath网络结构:

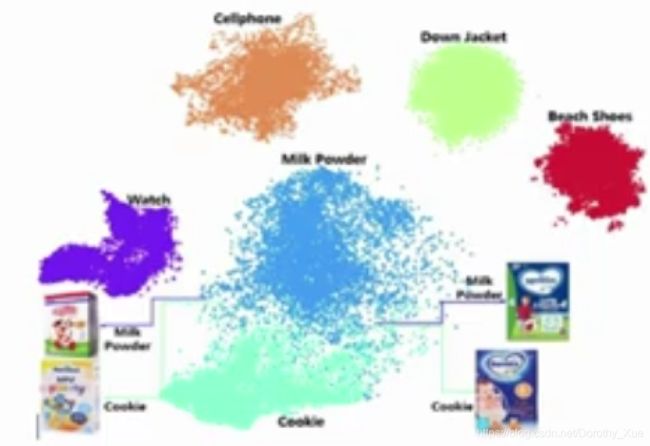
视觉激活item可视化:
上线对比效果:
