肯德尔秩相关系数matlab,常用的特征选择方法之 Kendall 秩相关系数
前面我们已经讨论了 Pearson 相关系数和 Spearman 秩相关系数,它们可以检测连续变量间的相关性,并且 Spearman 秩相关系数还能够检测有序的离散变量间的相关系数。今天我们再讨论一个能够检测有序变量相关性的系数:Kendall 秩相关系数。这里有序变量既包括实数变量,也包括可以排序的类别变量,比如名次、年龄段等。
Kendall 秩相关系数的定义
Kendall 秩相关系数是一个非参数性质(与分布无关)的秩统计参数,是用来度量两个有序变量之间单调关系强弱的相关系数,它的取值范围是 $[-1,1]$,绝对值越大,表示单调相关性越强,取值为 $0$ 时表示完全不相关。
原始的 Kendall 秩相关系数定义在一致对 (concordant pairs) 和分歧对 (discordant pairs) 的概念上。所谓一致对,就是两个变量取值的相对关系一致;分歧对则是指它们的相对关系不一致。这么说有点难以理解,我们举个例子。
假设我们为很多不同年龄的用户推送了一条社保相关的视频,然后回收了这些用户的播放完成度,如下表所示:
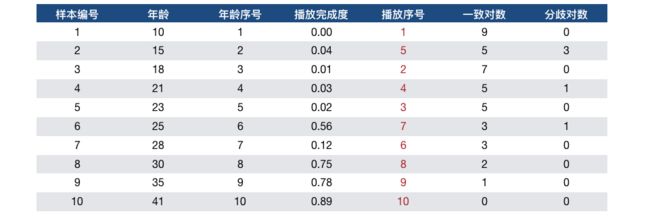
我们想用 Kendall 秩相关系数来分析用户年龄与该社保视频的播放情况是否相关。为此,我们将年龄和播放完成度分别排序后,对样本中取值进行排序和编号,分别得到 年龄序号 和 播放序号。这时,对于样本 $3$ 和样本 $4$,它们的年龄序号是 $[3,4]$,播放序号是 $[2,4]$,虽然序号不同,但是变化趋势是相同的,因此它们是一致的;对于样本 $2$ 和样本 $3$,它们的年龄序号是 $[2,3]$,播放序号是 $[5,2]$,它们的变化趋势是相反的,因此它们是分歧的。
进一步的,我们观察可以发现,当样本已经按年龄升序排列后,对于每个样本,我们可以简单的数一下该样本后续样本中播放序号大于该样本的样本数量,作为该样本引入的一致对数 (该样本之前的样本与该样本也可能一致,但是已经算过一次了),将所有样本引入的一致对数加起来就能得到所有样本的一致对数,记为 $c$。
同样的,对于每个样本,我们可以简单的数一下该样本后续样本中播放序号小于该样本的样本数量,作为该样本引入的分歧对数,累加后得到所有样本的分歧对数,记为 $d$。
则原始的 Kendall 秩相关系数定义为:
其中,$m=\frac{n\cdot (n-1)}{2}$ 表示所有样本两两组合的数量,在变量没有重复取值的情况下,$m=c+d$。定义 $(1)$ 也被称为 Tau-a,从定义也容易看出,它不能处理变量有相同取值的情况。
为了处理变量有相同取值的情况,我们还要将每个变量中相同取值的数量考虑进来,从而得到扩展的定义:
其中,$c$ 在计算的时候只能算 且 的对数,$d$ 也只能算 且 的对数 ();$t_x$,$t_y$ 分别表示变量 $x$,$y$ 取值中序号相同的样本对数排除共同平局的部分 (在下一小节举例说明)。式 通常又被称为 Tau-b,是实际中应用最广泛的定义 (另外还有 Tau-c 的变种这里就不介绍了)。在 scipy 1.3.0 版本的实现中,同时支持式 $(1)$ 和式 $(2)$。
举例说明
首先,我们根据式 $(1)$ 算一下图 $1$ 中年龄与播放的相关度。
将样本按年龄升序排列,将播放完成度按从小到大的顺序编号,如图 $1$ 所示;
分别计算每个样本新引入的一致对数和分歧对数,如图 $1$ 所示,进而算出 $c=40$,$d=5$;
根据式 $(1)$ 得到 $\tau_a=\frac{40-5}{40+5}=0.778$;
因此,年龄与播放社保视频的时长呈现强相关性,基于这个分析我们就可以尝试对更多年龄大一些的用户推送此视频。
在工程实现的时候,用户的年龄通常会被划分成不同的区间,而播放完成度只有超过一定阈值 (如 $0.3$) 我们才算作有效播放。因此,图 $1$ 的数据我们又可以转换成下面的离散情况:

可以发现,年龄段序号和有效播放序号存在大量的重复数据,因此我们基于式 $(2)$ 来计算:
将样本按年龄段升序排列,相同的年龄段按是否有效播放排序,对年龄段和是否有效播放进行编号,如图 $2$ 所示;
计算每个样本引入的一致对数和分歧对数,如图 $2$ 所示 (例如样本 $4$ 与 样本 $8\sim 10$ 一致),进而算出 $c=21$,$d=0$;
计算公共平局的数量 $t_c$,公共平局是指 $a_i=a_j$ 且 $b_i=b_j$ 的情况 (例如样本 $1\sim 3$ 互为平局,样本 $4,5,7$ 互为平局,样本 $8,9$ 互为平局),根据图 $2$ 易知:$t_c=\frac{3\cdot (3-1)}{2}+\frac{3\cdot (3-1)}{2}+\frac{2\cdot (2-1)}{2}=7$;
计算只在年龄段平局的数量 $t_x=\frac{3\cdot (3-1)}{2}+\frac{4\cdot (4-1)}{2}+\frac{2\cdot (2-1)}{2}-t_c=10-7=3$;
计算只在有效播放平均局的数量 $t_y=\frac{6\cdot (6-1)}{2}+\frac{4\cdot (4-1)}{2}-t_c=21-7=14$;
根据式 $(2)$ 得到 $\tau_b=\frac{21}{\sqrt{(21+3)(21+14)}}=0.725$;
对比发现,离散化后,我们发现这两个因素之间仍然是强相关的。
附示例的 python 代码
1
2
3
4
5
6
7
8
9
10>>>from scipy.stats import kendalltau
>>>import numpy as np
>>>x=[1,2,3,4,5,6,7,8,9,10]
>>>y=[1,5,2,4,3,7,6,8,9,10]
>>>kendalltau(x,y)
(0.7777777777777779, 0.0017451191944018172)
>>>x=[1,1,1,2,2,2,2,3,3,4]
>>>y=[1,1,1,1,1,1,2,2,2,2]
>>>kendalltau(x,y)
(0.72456883730947197, 0.0035417200011750309)
其中,kendalltau 返回的第二个结果是 p-value,其具体含义可参考官方文档。
Take-awaysKendall 秩相关系数可以用于度量有序变量间相关性,只要求变量取值之间可比,对变量的分布和数据的距离不作假设;
能用 Pearson 相关系数和 Spearman 秩相关系数的地方都能用 Kendall 秩相关系数,但是 Spearman 和 Kendall 秩相关系数要对数据排序,复杂度远高于 Pearson 相关系数,因此能用 Pearson 相关系数的时候优先考虑 Pearson 相关系数;
Kendall 秩相关系数依赖一致对和分歧对的计数,这里需要注意数据中是否有重复取值的情况,来选择使用 Tau-a 还是 Tau-b 进行计算。