【总结】一文了解所有的机器学习评价指标

最近在做深度学习的目标检测方向,评价指标涉及mAP,Precision,Recall等指标。
真可谓 剪不断,理还乱
索性总结了下机器学习和深度学习常见的评价指标,包括有
真阳性率 True Positive(TP)、
假阳性率 False Positive(FP)、
真阴性率 True Negative(TN)、
假阴性率 Fause Negative(FN)、
总体精度 Overall Accuracy(OA)、
Kappa系数、
生产者精度 Producer’s Accuracy(PA)、
用户精度 User’s Accuracy(UA)、
精确率 / 查准率 Precision、
召回率 / 查全率 Recall、
F1分数 F1 Score(F1)、
交并比 Intersection over Union(IoU)、
平均交并比 mean Intersection over Union(mIoU)、
置信度 Confidence
平均精确率 Average Precision(AP)、
平均精确率平均值 mean Average Precision(mAP)、
平均绝对误差 Mean Absolute Error(MAE)、
均方误差 Mean Squared Error(MSE)、
均方根误差 Root Mean Squared Error(RMSE)、
R2分数 R2 Score(R2)。

好家伙,这些指标总结下来,都可以出一套试卷了。
接下来小葵花妈妈课堂开课啦,孩子机器学习老不好,多半是没看到这篇文章。
首先我们以最简单的分类问题举个例子,比如说我们有10个小动物,它们依次是:
现在我们训练好的模型对其进行预测,结果是:

可以看到,有3只小动物分错了(第1、第9和第10个),那怎么评价这次预测结果呢?聪明的人类发明了若干种评价标准。
这里我们令为正样本(阳性)记作“1”,令为负样本(阴性)记作“0”,生成混淆矩阵,如下图
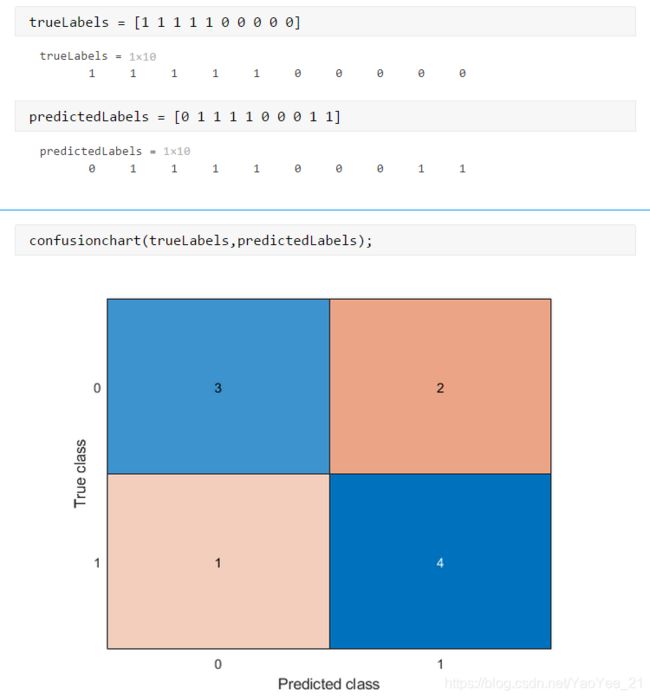
TP、FP、TN、FN
这4个都是由两部分组成,P和N指的是这个样本的预测结果是Positive还是Negative,T和F指的我预测的结果和真实标签对比是Ture还是Fause。那么对应到我们例子上,就是:
TP:预测是,实际为
FP:预测是,实际为
TN:预测是,实际为
FN:预测是,实际为
想的时候,先想想预测结果是P还是N,再想想这个P或N与真实标签对比是T还是F。对应到混淆矩阵就是:

OA
所谓总体精度,就是所有的样本我预测对了几个。最好理解用的也比较多,公式如下:
OA = (TN+TP) / (TN+TP+FN+FP) = (3+4) / (3+4+2+1) = 0.7
注:OA = 对角线加起来除全部的加起来
Kappa
OA效果不是挺好的吗?为什么还需要其他指标呢?
下面我们再举个例子:
真实情况:
预测情况:
之后都讨论这个例子!
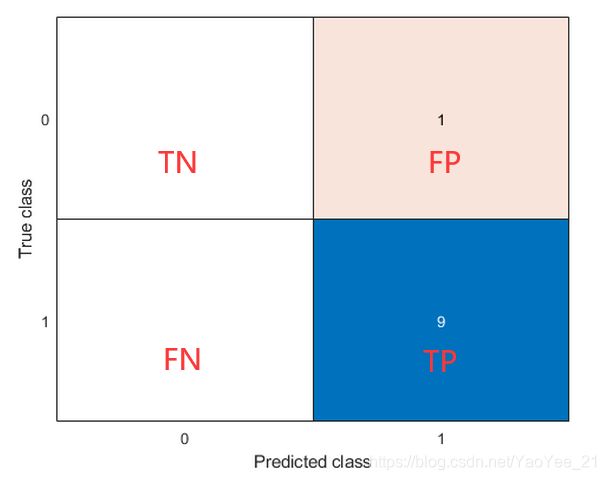
OA = (TN+TP) / (TN+TP+FN+FP) = (0+9) / (0+9+1+0) = 0.9
精度为90%,好像没什么问题,但是如果是恐怖分子呢?一旦漏掉了他,后果不堪设想,而这90%的精度也就没了意义。所以针对这种样本不平衡的情况,我们推出了Kappa系数,公式如下:
Kappa = (Po-Pe) / (1-Pe),其中,
Po = OA = 0.9
Pe = ( (TN+FN)×(TN+FP)+(FP+TP)×(FN+TP) ) / (TN+TP+FN+FP)^2 = 0.9
注:Pe = 每一行乘对应的每一列,再把乘积的结果加起来,用来除总数的平方
计算得 Kappa = 0,哇,好惨一Kappa~
kappa计算结果为-1~ 1,但通常kappa是落在 0 ~ 1 间,可分为五组来表示不同级别的一致性:0.0~ 0.20极低的一致性(slight)、0.21~ 0.40一般的一致性(fair)、0.41~ 0.60 中等的一致性(moderate)、0.61~ 0.80 高度的一致性(substantial)和0.81~ 1几乎完全一致(almost perfect)。
UA
用户精度,就是说在某一类的预测结果中,有百分之多少是对的?
对上面的例子而言,
: UA = TP / (TP+FP) = 9 / 10 = 0.9
: UA = TN / (TN+FN) = 0 / 0 = NUNE
注:UA = 对角线元素除其对应的预测标签数
可以看到对于用户精度,直接人没了。
PA
生产者精度,就是说在某一类的真实样本中,我预测对了百分之多少?
: PA = TP / (TP+FN) = 9 / 9 = 1
: PA = TN / (TN+FP) = 0 / 1 = 0
注:PA = 对角线元素除其对应的真实标签数
从生产者精度来说,预测的很好,则不行。
可以发现UA和PA的差别就在分母上,也就是用预测对的样本数除谁的问题。
上述指标一般在传统的机器学习中用的比较多,然而在深度学习的发展中还诞生了一些新的指标。
下面将来到演出下半场,同学们可以稍微休息十分钟。
好滴,欢迎回来,我们继续上课。
在用深度学习做分类时,其实评价指标和上述机器学习的指标大同小异,然而在目标检测和实例分割等领域,就出现了一些不同。
Precision
有的直译为精确率,单是这三个汉字,容易和OA搞混。其代表在我预测的正样本中,由百分之多少是对的,所以也有人译为查准率,更符合其在当下环境中的实际意义,计算公式如下:
Precision = TP / (TP+FP)
诶?你往上翻翻,这不就是的UA吗?
没错,UA是针对每一类样本的用户精度(每一行都有一个),而Precision就是只针对TP,也可以理解成正样本的用户精度。
Recall
了解了精确率 / 查准率,召回率 / 查全率是不是就容易多了,其代表在我真实的正样本中,我预测对了百分之多少。公式如下:
Recall = TP / (TP+FN)
Recall对应的就是只针对正样本的生产者精度。
F1
F1分数,是F1方程式的一项指标 。
人们往往可以使用上述Precision和Recall,从查准和查全的角度评价一个模型的好坏,但是这两者往往是矛盾。比如我可以在一张图上生成无数个框,这样查全率有100%,但是查准率就近似为0了。
所以人们发明了一种新指标,用来调和Precision和Recall,史称 F1 Score,计算公式如下:
F1 = 2×Precision×Recall / (Precision+Recall)
这个好像看不出怎么调和的,下面看看其推导过程就很简单了~

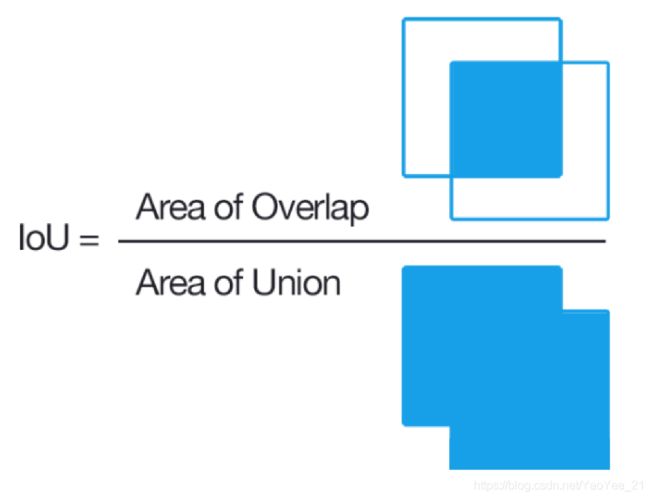
IoU
交并比是目标检测中的一个概念,所谓目标检测就是一张图上画个框,将目标框出来,而这个框就是我的预测结果。
那么问题来了,对于一个框我怎么去判断他是Ture还是False呢?
聪明的人们想到一个好方法,就是如果预测的框和真实的框重叠越多,那么他就越有可能是Ture,而这个重叠的指标也就是交并比,即两个框交集的面积除并集的面积,如下图所示:
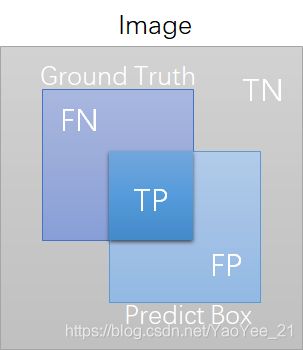
有了交并比的概念,人们就很容易划分TP、FP、TN和FN了~
mIoU
交并比知道了,那给他前面加个 m 是啥意思呢?
这个设问句好像有点弱智,mean当然是求均值啦!
一张图上有多个目标时,就会画多个框,就会有多个IoU,对其求均值,就得到了mIoU,这个指标在语义分割中好像用的更多一点。

Confidence
置信度,又是目标检测里的新词汇。
细心的同学可能发现上图中小猫和小狗的框上不仅有标签 “cat” 和 “dog” 还有两个数字,而这两个数字就是置信度,其代表模型预测出来的框,有多大的可信度。图中的 0.9 已经是蛮好的情况了。
AP
这个平均精确率和精确率有啥关系呢?和上面类似是每个框精确率的平均值吗?
NoNoNo
AP不是 mean Precision 而是 Precision-Recall 曲线所围成图形的面积大小。其中这个曲线图是在各个置信度阈值下的Precision和Recall值所构成的。
感觉有点绕哈~ 下面我们来举个例子,对路飞三兄弟进行人脸识别。

首先,设置IoU的阈值为0.5,即大于0.5的是正样本,否则是负样本。很明显路飞(左边第一个)和艾斯(右边第一个)是TP,萨博(中间那个人)是FP。
然后,设置Confidence的阈值为0.9,无视所有小于0.9的预测框。那么模型预测的所有框即TP+FP=1,即路飞是TP,那么Precision=1/1。因为所有的label=3,所以Recall=1/3。这样就得到一组P、R值。
接着,设置阈值为0.8,无视所有小于0.8的预测框。那么模型预测的所有框即TP+FP=2,因为路飞是TP,萨博是FP,那么Precision=1/2=0.5。因为所有的label=3,所以Recall=1/3=0.33。这样就又得到一组P、R值。
最后,设置阈值为0.7,无视所有小于0.7的预测框。那么模型预测的所有框即TP+FP=3,因为路飞是TP,萨博是FP,艾斯是TP,那么Precision=2/3=0.67。因为所有的label=3,所以Recall=2/3=0.67。这样就得到最后一组P、R值。
最最后,根据上面3组PR值绘制PR曲线如下。然后每个“峰值点”往左画一条线段直到与上一个峰值点的垂直线相交。这样画出来的红色线段与坐标轴围起来的面积就是AP值。

其中 AP = 1×0.33+0.67×0.33 = 0.55
mAP
相信知道了mIoU的小聪明们,已经可以领会mAP是啥意思了,上述的AP是针对检测路飞三兄弟的指标,而他们三个都有一个统一的标签就是海贼,如果我们的模型目的是同时检测出海贼和海军,那么我们就还会有一组海军的AP,而对这两个AP取平均,就是mAP啦~

可以发现海军三大将的脸部预测框都不准,同时置信度也很低。这是由于他们的脸部面积占比很小,属于目标检测中的小目标识别,存在一定的难度,后面有缘再讲~
MAE
刚看懂mAP,怎么又来一个MAE?想必已经有同学呼之欲出mmp。

先别着急mmp,想想那个迪士尼,这个押韵很神奇,下面继续来做题。skr~
上面这些指标不论是机器学习还是深度学习,他们有个共同的特点,就是你都学不懂 ,就是都在做分类,区分是还是,海贼还是海军,大佬还是你~
那么和分类相对的就是回归,比如用最小二乘法来拟合一条直线。
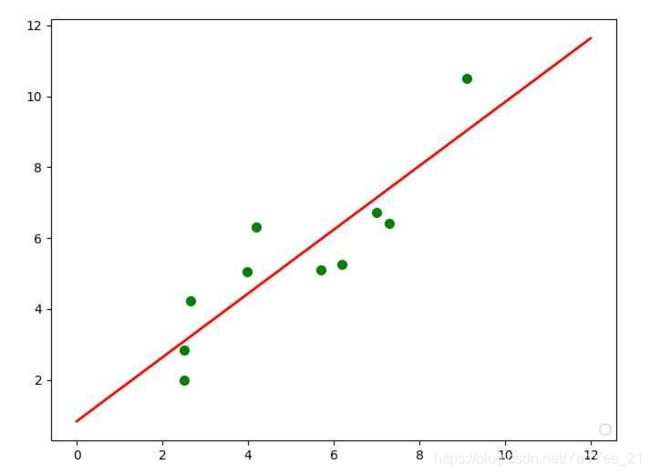
曲线拟合出来后,要怎么评价其精度呢?
最简单的就是,预测值减真实值再求平均就好啦,也就是这里所说的平均绝对误差,公式如下:
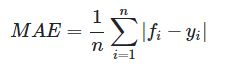
其中 fi 是预测值,yi 是真实值,下面的公式都一样。
MSE
均方误差计算的是预测值和实际值的平方误差,公式如下:
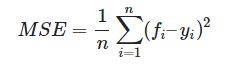
RMSE
由于MSE与我们的目标变量的量纲不一致,为了保证量纲一致性,我们需要对MSE进行开方,即均方根误差,公式如下:
R2
这个2其实是平方,也就是R^2,又称为 The Coefficient of Determination。判断的是预测模型和真实数据的拟合程度,最佳值为1,公式如下:
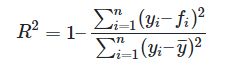
其中
![]()
终于走到了自传最终章,已浏览所有指标的风光。
不知不觉竟然写了整整一天,学术浅陋难免有错误,欢迎大家再评论区批评指正,同时也可以扫描下方二维码,加入群聊,你想看的,这里也不知道有没有,哈哈哈~
猜你喜欢:
⭐【算法】深度学习神经网络都调哪些参数?
⭐【总结】机器学习划分数据集的几种方法
⭐【随笔】深度学习的数据增强还分在线和离线?

参考文献:
[1] 说一说机器学习中TP、TN 、FP 、FN
[2] 图像分类精度评价
[3] kappa系数简介
[4] 目标检测的评价指标(TP、TN、FP、FN、Precision、Recall、IoU、mIoU、AP、mAP)
[5] 理解目标检测当中的mAP
[6] 回归模型评估指标