【python基础&进阶知识】——蛇缠发动机&thinkcspy
基础知识部分
- 概念、关键字
- 前言
- 0 Python内置函数
-
- **Python built-in module**
- help(Python built-in function)查看帮助
- 运算符/位运算
- 一、变量和数据类型
-
- 字符
- 数字
- 二、 元组
- 三、列表
-
- 列表解析
- 列表算法
- 四、字典
- 六、布尔
- 七、用户输入和while循环
- 八、函数
-
- 递归
- 九、模块与类
-
- 类
- 类的公有私有属性
- 类继承
- 链表
- stack & queue
- Trees
- 导入类
- Python标准库[http://pymotw.com/](http://pymotw.com/)
- 代码约定与规范
- 十、文件和异常
-
- 异常
- unittest
-
- 测试函数
- 类测试
- 项目一、pygame游戏
- python 知识点
概念、关键字
| complier | interpreter | high-level language | low-level language | Python Shell的immediate mode/script |
| nested number list |
| mutable | ||
| imumutable | ||
| iterable | ||
| hashable | 字典key | |
| generator |
https://blog.csdn.net/qq_36627886/article/details/80402959
operators and operands
A statement is an instruction that the Python interpreter can execute.
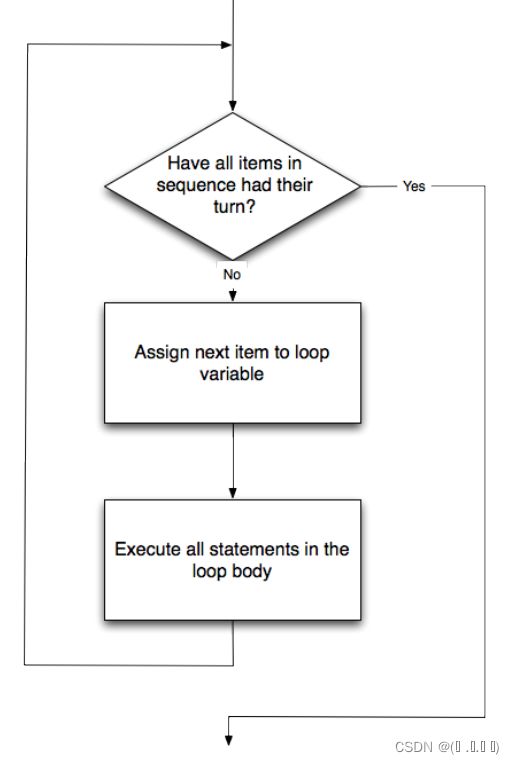
control flow(“Python’s moving finger.”)
for ele in ['a', 'b']:
print(ele)
docstring & comment
Just to differentiate from comments, a string at the start of a function (a docstring) is retrievable by Python tools at runtime. By contrast, comments are completely eliminated when the program is parsed.
When we read a program, don’t read from top to bottom. Instead, follow the flow of execution.
操作符顺序
取模和取余运算

| 比较运算 | == != < <= > >= |
| logical operator | and or not 注:a and b 当a为False时不对b进行运算(这点同C) |
 |
keywords
import keyword
keyword.kwlist
| def | del | gloabal | return | pass | is |
| if | elif | else | lambda | nonlocal | exec |
| try | except | raise | finally | assert | |
| with | as | class | from | import | |
| and | or | not | True | False | None |
| while | for | in | break | countinue | yield |
is : a is b,a和b是否指向同一片内存空间(a和b的地址是否一样),a 和 b是否指向同一个对象

前言
<先注释,再写代码>
Python之禅:import this
四个空格键
给列表指定一个表示复数的名称(如letters 、digits 或names )
Python tips:空格和制表符不要混用
Python Enhanced Proposal, PEP8
0 Python内置函数
Local scope --> Global scope --> Built-in scope
与以上对应的是namespace问题:Local namespace, global namespace
解释器在遇到 非关键字 的name后首先在Local scope找查,如果没找到则在Global scope中找查,再没找到则在Buit-in scope中找查,否则报错。
以下应该是 “内建范围” 的函数,不需要导入,直接调用即可
| 函数 | 功能 | eg: |
|---|---|---|
| type() | check classes or data type | |
| min() | ||
| max() | ||
| sum | ||
| bool() | ||
| int() | ||
| float() | float(‘inf’),float(‘-inf’) float(‘nan’):not a number None 即为 null |
|
| str() | ||
| range(a, b, interval) | 当需要时自动生成下一个数据,优点:省内存 | [a, b) |
| ord(‘a’) | 返回单个字符的ASC码值 | |
| len() | ||
| isinstance(instance, class) | isinstance(3.4, float) -> bool | |
| abs() | ||
| round() | ngigits为小数点后最多保留几位,[,ndigits]为可选项 | round(number[, ndigits]) round(4.5)->5(四舍五入) round(float_num, int(小数点后保留几位) ) |
| enumerate() | ||
| iter() | return iterator | iter(iterable) |
| next() | next(iterator [, default]) | |
| zip() | c=zip(a,b) a,b=zip(*c) a,b,*c=1,2,3,4 #c=[3,4] |
|
| map() | ||
| id() |
Python built-in module
| modulename | |
|---|---|
| time | https://blog.csdn.net/surfaceyan/article/details/122512741 |
| random | |
| math | |
| string | https://blog.csdn.net/surfaceyan/article/details/122736164 |
| copy | x = copy.copy(y) # make a shallow copy of y x = copy.deepcopy(y) # make a deep copy of y |
| itertools | permutaions, combinations |
| sortedcontainners | SortedList, SortedDict, SortedSet https://blog.csdn.net/surfaceyan/article/details/124218113 |
| collections | https://blog.csdn.net/surfaceyan/article/details/124225344 |
| queue | https://blog.csdn.net/surfaceyan/article/details/124219643 |
| re |
help(Python built-in function)查看帮助
meta notation
range([ start, ] stop [ ,step ])
for variable in list :
print( [ object , … ] )
粗体代表 typed into your Python code exactly as they are
斜体:可以替换 “something of this type”
(…) mean that you can have as many objects as you like (even zero)
运算符/位运算
2 << 1 # 二进制左移一位,2**n 与 2<
2 >> 1
~0xFF # 取反
& # 与 a且b
^ # 位异或 相异为1,相同为0
# 异或的性质,a异或b=c,则a异或c=b,b异或c=a
| # 或运算 a或b
一、变量和数据类型
基本数据类型/标准数据类型
不可变:数字,字符,元组
可变: 列表,字典,集合
import sortedcontainers中包含了带有顺序的列表,字典,集合
SortedList不支持反向??只能reversed(sl)??
变量
本质是一个地址,指向内存空间中的一块空间(知道了地址,地址中的值自然而然就知道了)
state snapshot

local variables
字符
字符不支持赋值操作
slice 切片 format ‘{0}, {1:}…’.format(0,1,2…) 判断回文数 移除所有字符 Python 进制转换 数字再计算中用补码表示,n位有符号数的取值范围 [-2^(n-1) , +2^(n-1)-1] 元组的元素不可修改 支持 + * 操作 https://blog.csdn.net/chenlinan_2017/article/details/81813061 列表解析是Python迭代机制的一种应用,常用于实现创建新的列表。 列表解析式简化了代码,使代码的可读性增强;编译器在内部作了优化,不会因为简写而影响效率,反而提高了效率。 test-driven development 线性搜索算法 算法复杂度评估方法: 需要k个probe才能把长度为N的列表搜索完 Binary Search 去除相邻的重复元素 有序列表的合并 • Return only those items that are present in both lists. 字典中的key不能重复 字典方法:keys() values() items() copy()浅复制 get() Eight Queens puzzle 异或运算:相同为0,不同为1 在下面的例子中,def puts name greet_user into the global namespace here. So it can be called on xxx Programming languages generally support recursion, which means that, in order to solve a problem, functions can call themselves to solve smaller subproblems. 嵌套列表 __main __- Automatically created module for IPython interactive environment 用以下方法会更为灵活 obj in [obj, obj …] 其中in自动调用__eq__方法 类的属性/函数,类的私有(不能在类定义之外使用)属性/函数 使用继承可简化相关类的创建工作;将一个类的实例用作另一个类的属性可让类更 简洁。 满二叉树:如图所示 二叉树的序遍历 中序遍历 (inorder) 后序遍历(postorder) 下面来看一个表达式: 1 + 2 * 3 preorder: + 1 * 2 3 ,prefix 导入单个类 在一个模块中存储多个类 从一个模块中导入多个类 导入整个模块 导入模块中的所有类 在一个模块中导入另一个模块 自定义工作流程: http://pymotw.com/ 你必须熟悉有些与类相关的编码风格问题,在你编写的程序较复杂时尤其如此。 try except else finally raise assert https://blog.csdn.net/surfaceyan/article/details/123243300 https://blog.csdn.net/surfaceyan/article/details/123490483
不会出现 IndexError: index out of range 的报错
字符比较大小: 按照词典顺序比较 A# {[index]:left< center^ right> 占用几个字符 .小数点后几位f 浮点数f 十六进制x}
# {} is called place holder
letter = "{1}abc{0}"
letter.format(123,4567)
"{}{}".format(1,2,3)
method:#python中似乎对单引号' 和双引号" 不敏感
#以下方法都有返回值,且不更改原字符串
str.title() #连续的英文字符,首字母大写,非首字母小写
'loveGB;;b a技术的H abc abc;abc,abc:abc撒地方ac4AB:4rG'.title()
#输出 'Lovegb;;B A技术的H Abc Abc;Abc,Abc:Abc撒地方Ac4Ab:4Rg'
str.upper() #所有英文字符大写
str.lower() #所有英文字符小写
"a" + "b" #return "ab"
"\t" #制表符
"\n" #换行符
#print函数会自动在字符串后面添加 换行符'\n'。end=''
str.rstrip() #删除字符串最右边的所有空格(包括\n \t)
str.lstrip() #删除字符串最左边的所有空格(包括\n \t)
str.strip() #删除字符串两头的所有空格(包括\n \t)
str.replace("a", "b") #将将字符串中所有的"a"替换为"b"
str.split() #字符串分成list,默认以空(包括'\n','\t',' ')分割
str.split("str") #str.split("")
str([1,3,'a']) #输出"[1,3,'a']"
str/list/tuple.count(ele) #统计字符串ele出现的次数,区分大小写,set/dict无此方法
join dash='-'
dash.join(seq) # seq = '123' or ['1','2','3']
new.join(str.split(old)
table = str.maketrans(x, y, z)
string.translate(table) # char mapping method
# 判断回文数
def reverse(char):
return ''.join(reversed(char))
def mirror(char):
reversed_char = reverse(char)
return char+reversed_char
def is_palindrome(char):
l = len(char)
if l%2 == 0: # even
p = l // 2
palindrome = mirror(char[:p])
else: # odd
p = (l-1) // 2
mid_letter = char[p]
palindrome = char[:p] + mid_letter + reverse(char[:p])
return palindrome == char
1 test(is_palindrome("abba"))
2 test(not is_palindrome("abab"))
3 test(is_palindrome("tenet"))
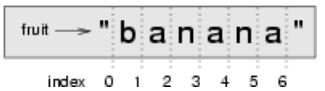
4 test(not is_palindrome("banana"))
5 test(is_palindrome("straw warts"))
6 test(is_palindrome("a"))
7 test(is_palindrome("")) # Is an empty string a palindrome?
def remove(subchar, char):
length = len(subchar)
for i in range(len(char)+1):
if subchar == char[i:i+length]:
new = char[:i] + char[i+length:]
return new
return char
def remove_all(subchar, char):
new = remove(subchar, char)
while char != new:
char = new
new = remove(subchar, char)
return new
1 test(remove_all("an", "banana") == "ba")
2 test(remove_all("cyc", "bicycle") == "bile")
3 test(remove_all("iss", "Mississippi") == "Mippi")
4 test(remove_all("eggs", "bicycle") == "bicycle")
数字
a = 90
90的补码=~a + 1 (按位取反+1)>>>0.1*3
0.30000000000000004
>>>.1+.2
0.30000000000000004
#str(),float(),int()
#int/int return float
#complex
二、 元组
支持 + * 操作tuple = ()
tuple = (1,)
tuple = 1, 2, [], (), element
三、列表
一定不要用 [0] * 3 这种操作,一不小心就会出问题!!!"""创建更复杂的列表时,可使用上述两种方法中的任何一种。有时候,使用临时变量会让代码更易读;
而在其他情况下,这样做只会让代码无谓地变长。你首先应该考虑的是,编写清晰易懂且能完成所需功能的代码
等到审核代码时,再考虑采用更高效的方法"""
bicycles = ['trek', 'cannondale', 'redline', 'specialized']
bicycles[-1] #倒数第一个 -2,倒数第二个;-3,倒数第三个...
#列表支持增、删、改、查 lists
bicycles.append("haha") #在列表最后添加元素
[1] + [3] #return [1, 3]
# list.insert(0, element)在方法insert() 在索引0 处添加空间,并将值element 存储到这个地方。
#这种操作将列表中既有的每个元素都右移一个位置
bicycles.insert(index, element)
#使用del 可删除任何位置处的列表元素,条件是知道其索引
del bicycles[0] #删除后,后面的元素应该会前移
#方法pop() 可删除列表末尾的元素,并让你能够接着使用它
#术语弹出 弹出 (pop)源自这样的类比:列表就像一个栈,而删除列表末尾的元素相当于弹出栈顶元素
list.pop() #renturn 列表中的最后一个元素,并将其从列表中删除
list.pop(index) #返回list[index],并将其从列表中删除
"""如果你不确定该使用del 语句还是pop() 方法,下面是一个简单的判断标准:
如果你要从列表中删除一个元素,且不再以任何方式使用它,就使用del 语句;
如果你要在删除元 素后还能继续使用它,就使用方法pop() """
list.remove("element") #删除列表中的第一个"element"
list.sort([key=function name, reverse=False]) #列表排序
sorted(list) #调用sorted() 函数,不改变list,返回排序后的值,可以用reverse
list.reverse() #将列表颠倒,无返回值
reversed() #这是一个函数,有返回值,不改变元列表的值
"""
只要是iterable,都可以用for循环遍历
"""
#列表解析
#squares = [value**2 for value in range(1,11)]
#列表切片
#list[a:b], list[:b], list[b:], list[-a:], list[::]?
#列表复制
listA = listB[:] #listA is not listB, 如果使用listA = listB,listA is listB 浅复制
for index value in enumerate(list):
列表解析
[ (i,j,k) for... if... for... if... ... ] #for 从左至右
列表算法
def search_linear(lst, target):
"""对列表没有任何要求"""
for i,v in enumerate(lst):
if v == target:
return i
return -1
N = 2**k - 1
k = ⌈ log2(N+1) ⌉ 向上取整 。 ⌊ ⌋ [ ] 向下取整def binary_search(sorted_lst, target):
"""列表必须有序,可以有重复元素"""
lb = 0
ub = len(sorted_lst) # slice
while True:
if lb == ub:
return -1
mid_idx = (lb + ub) // 2
mid_value = sorted_lst[mid_idx]
if target == mid_value:
return mid_idx
elif target < mid_value:
ub = mid_idx
else:
lb = mid_idx + 1 # +1必不可少
def remove_adjacent_dups(sorted_lst):
new = sorted_lst[:1]
for e in sorted_lst[1:]:
if e != new[-1]:
new.append(e)
return new
1 def remove_adjacent_dups(xs):
2 """ Return a new list in which all adjacent
3 duplicates from xs have been removed.
4 """
5 result = []
6 most_recent_elem = None
7 for e in xs:
8 if e != most_recent_elem:
9 result.append(e)
10 most_recent_elem = e
11 return result
• What should we do when either list has no more items?
• What should we do if the smallest items from each list are equal to each other?
• What should we do if the smallest item in the first list is smaller than the smallest one the second list?
• What should we do in the remaining case?def sored_list_merge(a, b):
"""列表必须有序,每个列表有都可以有重复元素"""
ai = 0
bi = 0
new = []
while True:
if ai == len(a):
new += b[bi:]
return new
if bi == len(b):
new += a[ai:]
return new
if a[ai]<b[bi]:
new.append(a[ai])
ai += 1
elif b[bi]<a[ai]:
new.append(b[bi])
bi += 1
else:
new += [a[ai], b[bi]]
ai += 1
bi += 1
• Return only those items that are present in the first list, but not in the second.
• Return only those items that are present in the second list, but not in the first.
• Return items that are present in either the first or the second list.
• Return items from the first list that are not eliminated by a matching element
in the second list. In this case, an item in the second list “knocks out” just
one matching item in the first list. This operation is sometimes called bagdiff.
For example bagdiff([5,7,11,11,11,12,13], [7,8,11]) would return [5,11,11,12,13]def only_in_first(x, y):
"""
x,y must sorted and set
"""
xi = 0
yi = 0
x_len = len(x)
y_len = len(y)
res = []
while True:
if xi == x_len:
return res
if yi == y_len:
res += x[xi:]
return res
if x[xi] < y[yi]:
res.append( x[xi] )
xi += 1
elif y[yi] < x[xi]:
yi += 1
else:
xi += 1
yi += 1
#----------------------
def bagdiff(a,b):
"""
a,b must be sorted , set is not needed
a-b"""
new = []
ai = 0
bi = 0
len_a = len(a)
len_b = len(b)
while True:
if ai == len_a:
return new
if bi == len_b:
new += a[ai:]
return new
if a[ai] == b[bi]:
ai += 1
bi += 1
elif a[ai] < b[bi]:
new.append(a[ai])
ai += 1
else :
bi += 1
#-------------------------------------
def in_both_list(xl, yl):
"""
sorted and set list xl
sorted and set list yl
Return only those items that are present in both lists
"""
prev = None
cur = None
xi = 0
yi = 0
res = []
xlen = len(xl)
ylen = len(yl)
while True:
if xi==xlen or yi==ylen:
return res
if xl[xi] < yl[yi]:
cur = xl[xi]
xi += 1
elif yl[yi] < xl[xi]:
cur = yl[yi]
yi += 1
else:
cur = xl[xi]
xi += 1
yi += 1
prev = cur
if cur == prev:
res.append(cur)
prev = cur
四、字典
在字典中通过key找查value非常快,或者说比list tuple str要快
key必须为可哈希的对象:int float str tuple
不可哈希的对象:list set dict#字典,目前唯一的一种标准映射类型
dictionary = dict()
dictionary = {}
del dictionary[key]
for key, vlaue in dictionary.items():
pass
for key in dictionary: #同for key in dictionary.keys():
pass
for value in dictionary.values():
pass
if key not in dictionary.keys():pass
for name in sorted(favorite_languages.keys()):pass
#集合 类似于列表,但每个元素都必须是独一无二的
set() #set(list)还会将element排序
for language in set(favorite_languages.values()):pass
问题表示六、布尔
a
b
a⊕b
0
0
0
0
1
1
1
0
1
1
1
0
尽量避免使用not
#布尔型
and
or
not
element in list
element not in list
not
#if语句
if True or False:
pass
elif True or False:
pass
else:
pass
#省略else
if True or False:
pass
elif True or False:
pass
七、用户输入和while循环
#input()
message = input("Tell me something, and I will repeat it back to you: ")
print(message)
#even or odd %求模运算
prompt = "\nTell me something, and I will repeat it back to you:"
prompt += "\nEnter 'quit' to end the program. "
message = ""
while message != 'quit':
message = input(prompt)
if message != 'quit':
print(message)
#要立即退出while 循环,不再运行循环中余下的代码,也不管条件测试的结果如何,可使用break 语句
#要返回到循环开头,并根据条件测试结果决定是否继续执行循环,可使用continue 语句
#for 循环是一种遍历列表的有效方式,但在for 循环中不应修改列表,否则将导致Python难以跟踪其中的元素。
#要在遍历列表的同时对其进行修改,可使用while 循环。
#通过 将while 循环同列表和字典结合起来使用,可收集、存储并组织大量输入,供以后查看和显示。
#在列表之间移动元素
while lst1:
lst2.append(lst1.pop())
#删除包含特定值的所有列表元素
while element in list:
list.remove(element)
while <expr>:
pass
break
else:
pass
print('while-else end')
for x in iterable:
pass
break
else:
pass
print('for-else end')
八、函数
#函数是带名字的代码块,用于完成具体的工作
def greet_user(username):
"""
显示简单的问候语
变量username 是一个形参 ——函数完成其工作所需的一项信息
在代码greet_user('jesse') 中,值'jesse' 是一个实参
向函数传递实参的方式:位置实参、关键字实参、列表和字典
这里的内容称为docstring,他会自动赋值给fun.__doc__属性,print(fun.__doc__)
"""
print("Hello, " + username.title() + "!")
greet_user('jesse')
fun = greet_user
fun('jesse')
#合法
def fun(a,b=6,c=4):
#不合法
def fun(a=1,b,c):
#函数的调用:位置方式、形参方式、混合方式必须合法
def get_formatted_name(first_name, last_name):
"""返回整洁的姓名"""
full_name = first_name + ' ' + last_name
return full_name.title() while True: print("\nPlease tell me your name:")
while True:
print("(enter 'q' at any time to quit)")
f_name = input("First name: ")
if f_name == 'q':break
l_name = input("Last name: ")
if l_name == 'q':break
formatted_name = get_formatted_name(f_name, l_name)
print("\nHello, " + formatted_name + "!")
#在函数中修改列表
fun(list1, list2)
#禁止函数修改列表
fun(list1[:], list2[:])
#虽然向函数传递列表的副本可保留原始列表的内容,但除非有充分的理由需要传递副本,
#否则还是应该将原始列表传递给函数,因为让函数使用现成列表可避免花时间和内存创 建副本,
#从而提高效率,在处理大型列表时尤其如此
#向函数传递任意数量的实参
#形参名*toppings 中的星号让Python创建一个名为toppings 的空元组,并将收到的所有值都封装到这个元组中
def function(*toppings):
#Python先匹配位置实参和关键字实参,再将余下的实参都收集到最后一个形参中
#使用任意数量的关键字实参
def build_profile(first, last, **user_info):
"""创建一个字典,其中包含我们知道的有关用户的一切"""
profile = {}
profile['first_name'] = first
profile['last_name'] = last
for key, value in user_info.items():
profile[key] = value
return profile
#可以以各种方式混合使用位置实参、关键字实参和任意数量的实参
递归
The organization of data for the purpose of making it easier to use is called a data structure.def r_sum(nested_list):
tot = 0
for ele in nested_list:
if isinstance(ele, list):
tot += r_sum(ele)
else:
tot += ele
return tot
def r_max(nxs):
"""
Find the maximum in a recursive structure of lists within other lists.
Precondition: No lists or sublists are empty.
"""
largest = None
first_time = True
for ele in nxs:
if isinstance(ele, list):
val = r_max(e)
else:
val = e
if first_time or val>largest: # caution int>None 会报错
largest = val
first_time = False
return largest
def fibo(n):
"""Fibonacci numbers, 此法效率极低"""
if n <= 1:
return n
x = fibo(n-1) + fibo(n-2)
return x
def mysum(n, x=0):
"""前n项和"""
x = n
if n <= 1:
return n
x = x + mysum(n-1, x)
return x
九、模块与类
#导入模块
import module
import module as anothername
from module import function1,function2,...
from module import * #然而,使用并非自己编写的大型模块时,最好不要采用这种导入方法
from module import function as anothername
#函数编写指南
#1、函数名用小写字母和下划线
#2、每个函数都应包含简要地阐述其功能的注释,该注释应紧跟在函数定义后面,并采用文档字符串格式
#3、给形参指定默认值时,等号两边不要有空格,关键字实参也应如此
#4、函数之间空两行以较为明显的区分一个函数的结束和另一个函数的开始
默认在 main __ 模块下进行编辑,所有的变量都可以通过import __ main __ 后通过__min.varname查看。环境自带__name__变量,为模块的名称
Variables defined inside a module are called attributes of the module. We’ve seen that objects have attributes too: for example, most objects have a _ _ doc _ _ attribute, some functions have a _ _annotations __ attribute. Attributes are accessed using the dot operator (.)#根据类来创建对象被称为实例化
#共有属性与私有属性
class Clas():
"""类的命名用大驼峰
class Clas: #Python 3.x
class Clas(): #Python 3.x
class Clas(object): #Python 2.7"""
attri = 1 #共有属性
def __init__(self, arg):
"""
__init__方法,每次实例化都会自动运行该方法
self指向实例本身
"""
#类的属性,通过实例可以访问该变量
self.arg = arg #可供类中的所有方法使用;实例的私有属性
#无法通过实例访问
var = arg
def method(self, v):
"""可以通过实例运行该方法"""
#实例不调用该方法就没有self.v
self.v = v
"""Python使用实参'args' 调用Clas类中的方法__init__() 。
方法__init__() 创建一个表示特定 对象 的实例,并使用我们提供的值来设置属性args 。
方法__init__() 并未显式地包含return 语句, 但Python自动返回一个表示 该对象 的实例。
我们将这个实例存储在变量obj中"""
obj = Clas(arg) #此过程称为实例化,创建了一个对象/实例
#Python先找到实例obj,再查找与这个实例相关联的属性arg
obj.arg
类
某些特定操作会自动调用__xx__方法,使用该方法可被其他函数调用
__ add__
+
__ sub__
-
__ mul__
*
__ rmul__
int * object
__ str__
__ eq__
==
__ le__
<=
__ ge__
>=
__ gt__
>
__ lt__
<
__ ne__
!=
Operator overloadingclass Point:
"""..."""
def __init__(self, x, y):
self.x = x
self.y = y
def __add__(self, P):
return Point(self.x+P.x, self.y+P.y)
def __str__(self):
return "({0}, {1})".format(self.x, self.y)
p1 = Point(1,3)
p2 = Point(4,5)
print(p1+p2)
类的公有私有属性
实例的属性/方法,实例的私有(不能在类定义之外使用)属性/方法
/实例的属性方法/私有的属性方法class A:
self.a = 1 # 报错
# 类属性, 优点:所有的 A 对象都可用, A.a赋值后所有的实例都会变
a = 2 # 公有属性 (搞不懂)
__d = 3 # 私有属性,类的外部不能调用,不能继承
def __init__(self, b, c):
print(a) # 报错
print(self.a)
# 实例属性
self.b = b # 类的私有属性,可在类中调用,不同的实例之间不干扰
c = c # 函数内的局部变量
self.__c = c # 私有属性,再类的外部不能调用,不能继承
def method(self):
print(a)、print(c,self.c) #报错
def __method(self):
''' 类外不能调用该方法,不能继承 '''
pass
def __method__(self):
"""并非"""
pass
类继承
class Battery():
"""将大量的属性和方法封装进类,在调用时现得整洁有序、有逻辑"""
def __init__(self, a, b):
self.a = a
self.b = b
def life(self):
print("调用了Battery类的life方法")
#Python 3.x中的继承
class SubClas(Clas):
def __init__(self, arg): #方法__init__()接受创建Clas实例所需的信息
"""super() 是一个特殊函数,帮助Python将父类和子类关联起来。
这行代码让Python调用SubClas的父类的方法__init__() ,
让SubClas实例包含父类的所 有属性。父类也称为超类 (superclass),
名称super因此而得名。 """
super().__init__(arg) #调用父类Clas的方法__init__(),从而继承父类该方法下的属性。
# 无该句,亦可调用父类的其他方法
self.attri = attri #定义子类特有的属性
self.battery = Battery() #将实例用作属性
#体会下与self.battery = Battery的差异
def subclas_method(self):
"""定义子类特有的方法"""
print("subclass method")
def method(self, v): #重写父类的方法
"""该子类方法与父类方法重名,
Python将不会考虑这 个父类方法,而只关注你在子类中定义的相应方法。 """
#实例不调用该方法就没有self.v
self.v = v
#Python 2.7中的类与继承,也适用于Python3
class Car(object): #Python 2.7中务必有object
def __init__(self, make, model, year):
--snip--
class ElectricCar(Car):
def __init__(self, make, model, year):
super(ElectricCar, self).__init__(make, model, year) #Python 2.7
--snip-
#模拟实物
"""模拟较复杂的物件(如电动汽车)时,需要解决一些有趣的问题。续航里程是电瓶的属性还是汽车的属性呢?
如果我们只需描述一辆汽车,那么将方法get_range() 放 在Battery 类中也许是合适的;
但如果要描述一家汽车制造商的整个产品线,也许应该将方法get_range() 移到ElectricCar 类中。
在这种情况下,get_range() 依然 根据电瓶容量来确定续航里程,但报告的是一款汽车的续航里程。
我们也可以这样做:将方法get_range() 还留在Battery 类中,但向它传递一个参数,如car_model ;
在 这种情况下,方法get_range() 将根据电瓶容量和汽车型号报告续航里程。
这让你进入了程序员的另一个境界:解决上述问题时,你从较高的逻辑层面(而不是语法层面)考虑;
你考虑的不是Python,而是如何使用代码来表示实物。到达这种境界后,你 经常会发现,
现实世界的建模方法并没有对错之分。有些方法的效率更高,但要找出效率最高的表示法,
需要经过一定的实践。只要代码像你希望的那样运行,就说明你做得很 好!
即便你发现自己不得不多次尝试使用不同的方法来重写类,也不必气馁;
要编写出高效、准确的代码,都得经过这样的过程。
"""
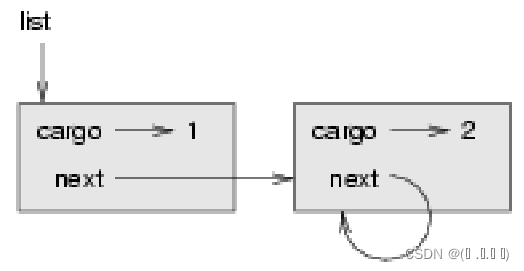
链表

class Node:
def __init__(self, cargo=None, next=None):
self.cargo = cargo
self.next = next
def __str__(self):
return str(self.cargo)
def print_node(node):
print(node, end=' ')
x.append(node.cargo)
if node.next is not None:
print_node(node.next)
print(node, end=', ')
x.append(node.cargo)
node1 = Node(1)
node2 = Node(2)
node3 = Node(3)
node1.next = node2
node2.next = node3
x = []
print_node(node1)
class Node:
s = ''
def __init__(self, cargo=None, next=None):
self.cargo = cargo
self.next = next
def __str__(self):
return str(self.cargo)
def init_s(self):
Node.s = ''
def print_tail2head(self):
if self.next is not None:
tail = self.next
tail.print_tail2head()
Node.s = Node.s + str(self.cargo) + ', '
class LinkedList:
'''这个类像个wrapper'''
def __init__(self):
self.length = 0
self.head = None
def print_tail2head(self):
Node.s = ''
self.head.print_tail2head()
print_linkedlist = Node.s
print('[{}]'.format(print_linkedlist[:-2]))
Node.s = ''
def add_first(self, cargo):
node = Node(cargo)
node.next = self.head
self.head = node
self.length += 1
def __str__(self):
self.print_tail2head()
return ''
stack & queue
class Stack:
def __init__(self):
self.length = 0
self.stack = []
def push(self, value):
self.stack.append(value)
self.length += 1
def pop(self):
self.length -= 1
return self.stack.pop()
def __str__(self):
return str(self.stack)
class Queue:
"""poor performance"""
def __init__(self):
self.queue = [1,2]
def __len__(self):
return len(self.queue)
def is_empty(self):
return len(self.queue) == 0
def insert(self, item):
self.queue.append(item)
def remove(self):
return self.queue.pop(0)
class Node:
def __init__(self, cargo=None, next=None):
self.cargo = cargo
self.next = next
def __str__(self):
return str(self.cargo)
def print_node(self):
cargo = self.cargo
print(cargo, end=' ')
if self.next is not None:
node = self.next
node.print_node()
class ImprovedQueue:
"""consum constant time"""
def __init__(self):
self.head = None
self.tail = None
self.length = 0
def __len__(self):
return self.length
def is_empty(self):
return self.length == 0
def insert(self, cargo):
node = Node(cargo)
if self.length == 0:
self.head = self.tail = node
else:
self.tail.next = node
self.tail = node
self.length += 1
def remove(self):
cargo = self.head.cargo
if self.length == 1:
self.head = self.tail = None
else:
head = self.head.next
self.head = head
self.length -= 1
return cargo
class PriorityQueue:
def __init__(self):
self.items = []
def is_empty(self):
return not self.items
def insert(self, item):
self.items.append(item)
def remove(self):
maxi = 0
for i in range(1, len(self.items)):
if self.items[i] > self.items[maxi]:
maxi = i
item = self.items[maxi]
del self.items[maxi]
return item
Trees
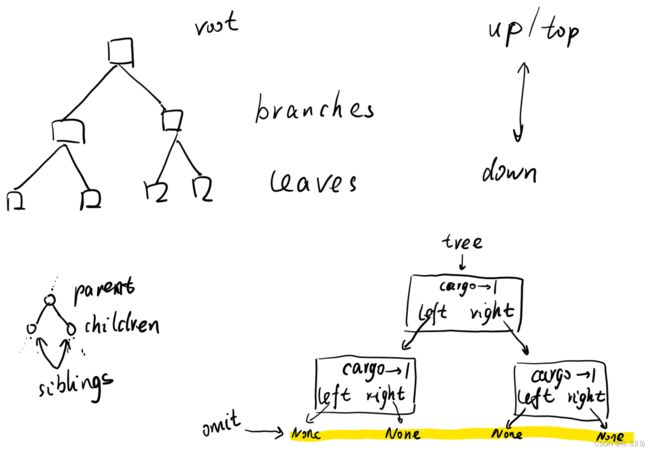
完全二叉树:底层不一定能够满,但一定从左到右连续
所以,满二叉树class Tree:
def __init__(self, cargo, left=None, right=None):
self.cargo = cargo
self.left = left
self.right = right
def __str__(self):
return str(self.cargo)
前序遍历(preorder)# The contents of the root appear before the contents of the children.
def print_tree(tree):
if tree is None: return
print(tree, end=' ')
print_tree(tree.left)
print_tree(tree.right)
# The contents of the root appear between the contents of the children.
def print_tree(tree):
if tree is None: return
print_tree(tree.left)
print(tree, end=' ')
print_tree(tree.right)
# The contents of the root appear after the contents of the children.
def print_tree(tree):
if tree is None: return
print_tree(tree.left)
print_tree(tree.right)
print(tree, end=' ')
操作符在中间,操作符在分支节点,操作数在叶子节点(叶子节点的left=right=None)
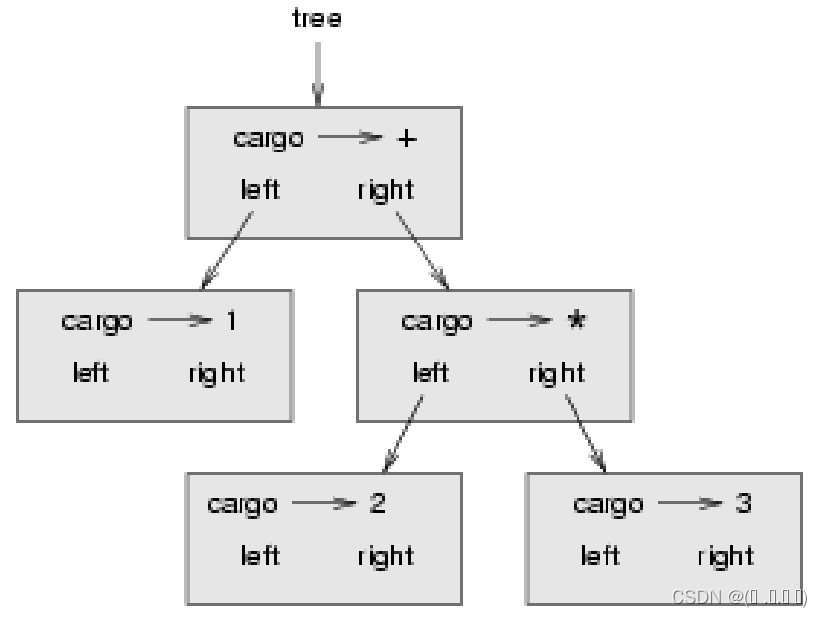
tree = Tree('+', Tree(1), Tree('*', Tree(2), Tree(3)))
inorder : 1 + 2 * 3 , infix
postorder : 1 2 3 * + , postfix导入类
正如你看到的,在组织大型项目的代码方面,Python提供了很多选项。熟悉所有这些选项很重要,这样你才能确定哪种项目组织方式是最佳的,并能理解别人开发的项目。
一开始应让代码结构尽可能简单。先尽可能在一个文件中完成所有的工作,确定一切都能正确运行后,再将类移到独立的模块中。如果你喜欢模块和文件的交互方式,可在项目 开始时就尝试将类存储到模块中。先找出让你能够编写出可行代码的方式,再尝试让代码更为组织有序。Python标准库http://pymotw.com/
代码约定与规范
类名应采用驼峰命名法 驼峰命名法 ,即将类名中的每个单词的首字母都大写,而不使用下划线。实例名和模块名都采用小写格式,并在单词之间加上下划线。
对于每个类,都应紧跟在类定义后面包含一个文档字符串。这种文档字符串简要地描述类的功能,并遵循编写函数的文档字符串时采用的格式约定。每个模块也都应包含一个文 档字符串,对其中的类可用于做什么进行描述。
可使用空行来组织代码,但不要滥用。在类中,可使用一个空行来分隔方法;而在模块中,可使用两个空行来分隔类。 需要同时导入标准库中的模块和你编写的模块时,先编写导入标准库模块的import 语句,再添加一个空行,然后编写导入你自己编写的模块的import 语句。在包含多 条import 语句的程序中,这种做法让人更容易明白程序使用的各个模块都来自何方。十、文件和异常
filePath = "文件路径"
#关键字with 在不再需要访问文件后将其关闭
with open(filePath, "r/w/a/r+") as fileObject:
""" r: 只读模式(默认) rb以二进制文件读取
with open(f,rb) as f: f.read(xxx bytes),type=bytes
w: write,如果你要写入的文件不存在,函数open() 将自动创建它。
然而,以写入('w' )模式打开文件时千万要小心,因为如果指定的文件已经存在,
Python将在返回文件对象前清空 该文件。
a: 附加模式,如果你要给文件添加内容,而不是覆盖原有的内容,可以附加模式 附加模式 打开文件。
以附加模式打开文件时,Python不会在返回文件对象前清空文件,写入到文件的行都将添加到文件末尾
如果指定的文件不存在,Python将为你创建一个空文件。
r+:读取和写入文件的模式"""
contents = fileObject.read() #一次将文件的所有内容读取为一个字符串
for line in fileObject: #逐行遍历文件
line #为一个字符串
contents = fileObject.readlines() #个包含文件各行内容的列表,element为字符串
#写入一行
file_object.write("I love programming.")
异常
try: # 捕获异常,出现异常后必须except解决异常否则该异常一直存在,异常会在finally执行后报错
<语句> # 此语句中可能会出现异常
raise ValueError("这个值不对")
except:
处理
except [异常类型]:
异常处理
except IOError as e:
print(e)
except (ConnectionError, ReadTimeout, Exception):
异常处理
else:
<语句> # try语句中没有异常则执行此段代码
finally: # 必须放在最后
print('无论异常与否,都会执行我')
# 用户自定义异常
class MyError(Exception):
def __init__(self, msg):
self.msg = msg
def __str__(self):
return self.msg
try:
raise MyError('类型错误')
except MyError as e:
print('My exception occurred', e.msg)
#捕获异常并处理 try-except代码块
try:
print(5/0)
except ZeroDivisionError:
print("You can't divide by zero!")
继续执行try-except代码块后的代码
try:
with open(filename) as f_obj:
contents = f_obj.read()
except FileNotFoundError:
msg = "Sorry, the file " + filename + " does not exist."
print(msg)
"""
try-except-else 代码块的工作原理大致如下:Python尝试执行try 代码块中的代码;
只有可能引发异常的代码才需要放在try 语句中。
有时候,有一些仅在try 代码块成功 执行时才需要运行的代码;
这些代码应放在else 代码块中。except 代码块告诉Python,
如果它尝试运行try 代码块中的代码时引发了指定的异常,该怎么办。
通过预测可能发生错误的代码,可编写健壮的程序,它们即便面临无效数据或缺少资源,
也能继续运行,从而能够抵御无意的用户错误和恶意的攻击。
"""
try:
answer = int(first_number) / int(second_number)
except ZeroDivisionError:
print("You can't divide by 0!")
else:
print(answer)
#存储数据 json(JavaScript Object Notation)
numbers = [2, 3, 5, 7, 11, 13]
filename = 'numbers.json'
with open(filename, 'w') as f_obj:
json.dump(numbers, f_obj)
#读取json
filename = 'numbers.json'
with open(filename) as f_obj:
numbers = json.load(f_obj)
unittest
测试函数
class NamesTestCase(unittest.TestCase):
"""测试name_function.py """
def test_first_last_name(self):
"""能够正确地处理像Janis Joplin这样的姓名吗?"""
formatted_name = get_formatted_name('janis', 'joplin')
self.assertEqual(formatted_name, 'Janis Joplin')
def test_first_last_middle_name(self):
"""能够正确地处理像Wolfgang Amadeus Mozart这样的姓名吗?"""
formatted_name = get_formatted_name('wolfgang', 'mozart', 'amadeus')
self.assertEqual(formatted_name, 'Wolfgang Amadeus Mozart')
unittest.main()
类测试
在这里插入代码片
项目一、pygame游戏
python 知识点