使用K-Fold训练和预测XGBoost模型的方法
文章目录
- 一、前言
- 二、Xgboost一般的训练方法
-
- 2.1 问题及数据分析
- 2.2 搭建xgboost预测模型
- 2.3 XGBoost模型训练保存及模型评估
- 2.4 使用XGBoost模型进行预测
- 三、 使用F-fold方法训练和预测XGBoost模型
-
- 3.1 使用F-fold方法训练XGBoost模型
- 3.2 使用K-Fold产生的XGBoost模型进行综合预测
- 四、总结
一、前言
在机器学习中,K-Fold交叉验证是一种充分利用数据集的训练验证方式,有助于避免过拟合,同时也是一种超参数优化技术。本文将从代码实践的角度剖析在Xgboost模型中如何使用K-Fold技术进行训练和预测。
PS:只是想借着这个问题展示如何在Xgboost模型中使用K-Fold方法,数据是我在网上随便找的,大家重视代码实现,不用过分关注建模问题本身
本文依托一个使用Xgboost实现二手房交易价格预测问题,数据文件和全部代码链接如下:
K-Fold_XGBoost
二、Xgboost一般的训练方法
2.1 问题及数据分析
import pandas as pd
import numpy as np
feature_file = pd.read_csv("./DataHousePricePrediction/train.csv")
#可视化数据
feature_file.head()
输出结果为:

从数据上看,saleTime记录了售出实践,price是要预测的变量,rooms和baths等是决定售卖价格的11个变量。由数据出发可以将二手房交易价格预测问题看成是一个结构化数据的回归问题。输入的一个样本是由saleTime,rooms等变量组成的13维变量,输出的标签是一个1维变量:price价格。
数据处理:
from sklearn.model_selection import train_test_split
############################################
#数据处理
############################################
x = []# 特征数据
y = []# 标签
for index in feature_file.index.values:
#print('index', index)
#print(feature_file.values[0])
#print(feature_file.ix[index].values)
x.append(feature_file.values[index][2: -1]) # 从原文件中提取输入变量数据
y.append(feature_file.values[index][1]) # 从原文件中提取输出变量标签
x, y = np.array(x), np.array(y)
print('='*60)
print('输入数据的shape为: ', x.shape)
print('输出Label的shape为:', y.shape)
print('样本数为:', len(feature_file.index.values))
print('='*60)
# 划分训练集和验证集
X_train,X_valid,y_train,y_valid = train_test_split(x,y,test_size=0.2,random_state=12345)
print('训练集和对应Label的shape为: ', X_train.shape, y_train.shape)
print('验证集和对应Label的shape为: ', X_valid.shape, y_valid.shape)
输出结果为:

2.2 搭建xgboost预测模型
from xgboost import XGBRegressor
#定义xgboost
xgb = XGBRegressor(learning_rate =0.1,
n_estimators=150,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'reg:squarederror',
nthread=4,
scale_pos_weight=1,
seed=27)
上面的程序定义了一个用于处理回归任务类型的xgboost模型。其中,模型中选定的参数的含义可以看xgboost的官方文档:
XGBRegressor参数描述
2.3 XGBoost模型训练保存及模型评估
xgb.fit(X_train,y_train) #训练模型
xgb.save_model(f'./XGB_train.xgb') #保存参数文件
score = xgb.score(X_valid,y_valid)
print(score)
此时,XGBoost模型的训练结果将会存储为XGB_train.xgb文件。其中,.score 方法是用来衡量XGBRegressor 模型预测精准度的一个指标。具体的衡量方式及意义如下:

2.4 使用XGBoost模型进行预测
这里没有准备Test数据集,所以这里就用valid数据充当test进行预测,重点关注代码的实现问题。
#从训练好的文件中导入模型
xgb = XGBRegressor() #定义模型
xgb.load_model(f'./XGB_train.xgb') #导入参数文件
df_result = xgb.predict(X_valid)
df_result = pd.DataFrame(df_result) #numpy格式转pandas格式
df_result.to_csv("./precit_normal.csv", index=False) #将预测结果存至precit.csv文件中
三、 使用F-fold方法训练和预测XGBoost模型
3.1 使用F-fold方法训练XGBoost模型
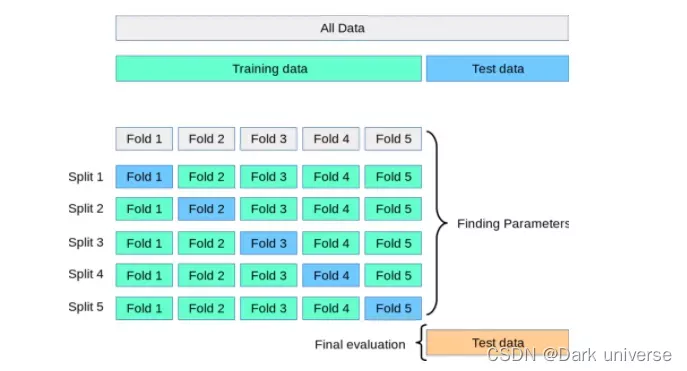
如第二章所示,在训练时我们会划定训练集和测试集,这样人工划定就存在一个问题,即:被划定成测试集的部分永远不能被用于训练,同理被划定为训练集的部分同样不能被用于测试。这对于一些本来数据就十分珍贵的任务来说时不能接受的(因为没有充分的利用数据)。针对此问题,K-Fold交叉验证方法应运而生。所谓K-Fold,就是对训练数据进行K折划分(划分成K份),其中(K-1) 折用于训练,剩下一折用于验证,这个过程重复K次,并通过获取训练的所有K个模型的平均值和标准差来计算一组特定超参数的模型性能分数,计算给出最优模型的超参数。最后,模型使用最优超参数在整个训练数据集上再次训练,并通过计算测试数据集上的评估分数来计算泛化性能。通过K-Fold方法实现了训练集中的每一组数据都有充当训练集和验证集的机会,充分利用了数据。K-Fold的划分如下图:
import pandas as pd
from sklearn.metrics import mean_squared_error as MSE
from sklearn.model_selection import KFold
#设置KFold的次数
n_splits = 5
kf = KFold(n_splits)
fold = 0
for train_index, test_index in kf.split(x):
# kf.split返回所划分的训练集和测试集所对应的索引位置
train_X = x[train_index]
train_y = y[train_index]
valid_X = x[test_index]
valid_y = y[test_index]
#print(train_X.shape)
#print(train_y.shape)
#定义xgboost
xgb = XGBRegressor(learning_rate =0.1,
n_estimators=150,
max_depth=5,
min_child_weight=1,
gamma=0,
subsample=0.8,
colsample_bytree=0.8,
objective= 'reg:squarederror',
nthread=4,
scale_pos_weight=1,
seed=27)
xgb.fit(train_X, train_y)
xgb.save_model(f'./XgbModels/XGB_fold{fold}.xgb')
fold = fold + 1
score = xgb.score(X_valid,y_valid)
print("第",fold,"次模型的的准确率为:", score)
3.2 使用K-Fold产生的XGBoost模型进行综合预测
#使用K-FOld产生的模型进行综合预测
for f in range(0,n_splits):
xgb = XGBRegressor()
xgb.load_model(f'XgbModels/XGB_fold{f}.xgb')
if f == 0:
df_result = xgb.predict(X_valid)
else:
df_result = df_result + xgb.predict(X_valid)
df_result /= n_splits
df_result = pd.DataFrame(df_result) #numpy格式转pandas格式
df_result.to_csv("./precit.csv", index=False) #将预测结果存至precit.csv文件中
四、总结
K-Fold方法可以充分利用数据,且经过K-Fold训练出的模型(综合使用时)泛化能力强,不易过拟合。在一些竞赛和解决实际问题时采用K-Fold时一个不错的提升性能的选择。