机器人抓取检测论文阅读笔记——详解用于抓取的Residual Squeeze-and-Excitation Network
论文名:Residual Squeeze-and-Excitation Network with Multi-scale Spatial Pyramid Module for Fast Robotic Grasping Detection
用于快速机器人抓取检测的具有多尺度空间金字塔模块的剩余挤压和激励网络
文章目录
- 一、前言
- 二、论文摘要
- 三、处理抓取问题的方法归类(小白学习点)
- 四、论文核心技术解读
-
- 4.1 抓取问题简述
- 4.2 算法的解决思路
- 4.3 算法核心技术详解1——残差挤压和激励网络(RSEN)
- 4.4 算法核心技术详解2——多尺度空间金字塔模块(MSSPM)
- 4.5 算法核心技术详解3——层次特征融合(Hierarchical feature fusion)
- 五、实验结果
- 六、结论
一、前言
从这篇文章开始,我将陆续更新一些“机械臂抓取”方向的论文阅读笔记。中间会穿插一些我自己的理解和想法,希望能给和我一样从零学习的小伙伴们一些灵感。
论文下载地址
这篇文章没有代码,但是他的行文思路和代码结构(我预测的)应该和GRCNN很像,尤其是网络输出部分,所以想要浏览或者复现代码的小伙伴们可以参考GRCNN的论文+代码。
博客主要是记录和分析论文中一些关键的知识点,只谈重点,论文的通篇翻译推荐以下这篇博客:https://blog.csdn.net/zhangzhikang_zzk/article/details/122319128
二、论文摘要
本文提出了一种高效的全卷积神经网络,通过使用 300×300 深度图像作为输入来生成机器人抓取。具体来说,引入了一个残差挤压和激励网络(RSEN)来进行深度特征提取。在 RSEN 块之后,开发了多尺度空间金字塔模块 (MSSPM) 来获取多尺度上下文信息。每个 RSEN 块和 MSSPM 的输出被合并为分层特征融合的输入。然后,对融合的全局特征进行上采样以执行像素级学习以掌握姿势估计。在 Cornell 和 Jacquard 抓取数据集上的实验结果表明,所提出的方法具有 5ms 的快速推理速度,同时在 Cornell 和 Jacquard 上分别实现了 96.4% 和 94.8% 的高抓取检测精度,在精度和运行速度之间取得了平衡。我们的方法还通过 UR5 机械臂获得了 90% 的物理抓取成功率。
从摘要可知,论文主要有三大创新点:RSEN、MSSPM和特征融合。所以下面的部分主要对这两部分进行介绍。
三、处理抓取问题的方法归类(小白学习点)
重要学习点和入门明灯:文中在“RELATED WORK”部分对目前的处理机械臂抓取问题的方法做出了一个经典的分类,并列举了相应的论文。这对于刚入门的小白想快速梳理行业发展脉络来讲可太重要了!!!点赞
我将文中的内容做成了思维导图:

四、论文核心技术解读
4.1 抓取问题简述
本文解决抓取问题的思路是:基于抓取点。将抓取点定义为:g = (p, ϕ, w, q)。其中p = (x, y, z)是待抓取物体抓取点的三维坐标,φ为夹持器绕 z 轴的旋转角度,w为夹持器的打开和关闭距离,q为这个点被抓取成功的概率。通俗来讲,我们现在要设计一个算法,让算法计算输入图像上每个像素点(会对应一个三维物理世界点)的抓取成功概率,然后选择q最大的点进行抓取。 这里强烈推荐大家去读原文,我把这部分的截图放出来,虽然是英文的,但是介绍的很清晰。

4.2 算法的解决思路
下图是算法的框架图。
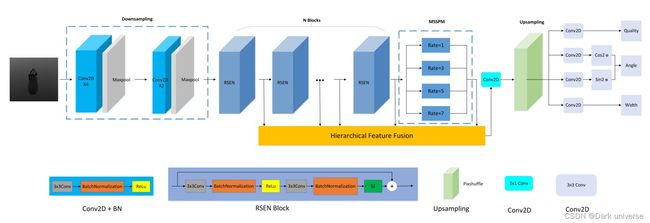
第一件事,明确输入和输出:
由图可知,算法的输入:一张depth深度图
输出:三张和原图像相同大小的矩阵(图像),分别是表示抓取质量的quality矩阵,表示抓取角度的angle矩阵,表示夹爪张开宽度的width矩阵。这里矩阵中的每一个点就是对应原输入图像点(三维物理世界中的那个点)的抓取成功概率,要调整的机械臂角度和夹爪应该张开的角度(这里因为输入图像可以通过坐标系变换获取到对应点的三维坐标(下x,y,z),所以算法不需要再输出这个)。
再次说明:是否要抓取这个点,我们要看他的抓取成功概率quality,确定抓取这个点后我们还需要知道机械臂该去往的位置(x,y,z)(可以通过坐标系变换在输入图像中算出),调整的抓取角度angle,夹爪张开距离width。通过算法可以获知所有变量,所以抓取系统构建完成,算法是可用的。
通过观察算法的框架,算法的处理流程如下:
输入图像先通过Downsampling模块进行下采样,原理是通过两次卷积和2*2最大池化,这里没什么新技术,就不看了。然后图像进入到n个RSEN模块,然后再进入MSSPM模块,将这两个模块的输出矩阵进行特征融合后,最后再上采样Upsampling,最后获得输出矩阵。
我们发现这一过程中只有RSEN、MSSPM和特征融合是没听过的新技术,所以下面进行详细解读和分析。
4.3 算法核心技术详解1——残差挤压和激励网络(RSEN)
RSEN其实就是由一个33的卷积,bn归一化层,Relu激活函数层,再一个33的卷积,BN归一化和SE构成。这里有一个输入和输出的短接shortcut,所以应该能猜到这个SE模块应该有将经过第二个BN层的特征变化至输入大小的作用。实际上的SE和这个差不多,具体的细节不讲了,想了解的小伙伴可以参考这篇博客:https://blog.csdn.net/renxingshen2022/article/details/125773673
在我看来仅以工程代码的角度讲,一些所谓的高级变化和模块无非就是卷积的各式操作的叠加。作者说引入RSEN主要是为了:为了获得更有意义的语义特征,我们引入了一个残差挤压和激发网络(RSEN)来产生基于局部跳跃连接的层次特征,其中包括 2 个卷积层,后面跟着一个挤压和激发块,用于增强层次特征渠道级别。(原文:To get more meaningful semantic features, we introduce a residual squeeze-and-excitation network (RSEN) to produce hierarchical features based on local skip connection, which include 2 convolution layers followed by a squeeze-and- excitation block [28] for enhancing hierarchical features at a channel-wise level)。但这里要强调的有两点:一是RSEN并不改变特征图的大小,二是特征图每进入一个RSEN模块就要输出到特征融合模块里。
4.4 算法核心技术详解2——多尺度空间金字塔模块(MSSPM)
先明确一点:输入和输出。这个模块的输入是经过了n次RSEN产生的特征图,输出是四个特征图的汇总(也就是一个特征图)。这里处理特征图的技术是:空洞卷积,相关的概念及使用方法可以参考博客:https://blog.csdn.net/weixin_55073640/article/details/123085418 图中的rate指的是空洞卷积的速率,不同的速率对应不同的卷积结果。空洞卷积可以通过调节速率来控制卷积感受野的大小,因此文中通过空洞卷积实现了多尺度空间金字塔模块。
这里仍然要强调两点:一是空洞卷积并不改变特征图的大小(文中应该是补边的),也就是说四种速率下产生的卷积特征图是一样大的;而是这四张图是直接逐像素相加变成一张输出特征图送入特征融合模块的。
4.5 算法核心技术详解3——层次特征融合(Hierarchical feature fusion)
关于这个模块我也存在着一定的疑惑,所以下面的讲解不一定对(因为没有源码,所以我的猜想不能验证,如果有确定理解的小伙伴可以在下面call我,不胜感激)。
先结合上下文明确这部分的输入输出。
输入是RSEN模块和MSSPM模块的特征图(从前文分析出这两个模块的输出特征图应该是一样大的,至少在h和w方向上是的)。
输出应该是一个特征图,且该特征图经过Upsampling后变成和输入图像相同大小(在h和w方向上),文中的Upsampling为pixelshuffer方法,pytorch中有集成(文中说代码是基于pytroch写的),原理和实现见下面的博客:
https://blog.csdn.net/level_code/article/details/123637969
通过pixelshuffer处理的特点可以反推出特征融合模块的输出特征图在h和w方向的大小上应该和最终的图像呈相同的倍数关系。

上图是文中对于这部分的描述,前文中说算法一共使用了7个RSEN模块(n=6),MSSPM模块的输出只有一个: x m s s p m x_{msspm} xmsspm。现在看公式11。公式的右半部分是输入特征图,一共有8个(n=6),从前文核心技术的分析可知,这8个特征图的大小应该是一致的。
我对于这部分变换的一种理解:现在进行一下大小的推理(忽略通道数c,只考虑矩阵的h和w):文中输入的深度图大小为300 * 300,经历了两次2 * 2的最大池化,应该变成75 * 75,也就是现在待融合的特征图的大小。文中说采用concatenation operation技术进行拼接,这里没有对其进行进一步的解释。这个名词对应的是矩阵拼接操作,在numpy中对应的操作应该是:np.concatenate()。也就是说现在经过特征融合后的特征图大小应该是:(c1,75*8,75),最后通过Upsampling中的pixelshuffer方法转成(c2, 300,300)。
这里只是我对于这个模块的变化操作应用到矩阵上的一种理解,不一定正确(没有代码,太痛苦了)。
五、实验结果
模型在参数为2.94M的情况下实现了5ms的快速推理速度。此外,该抓取算法在Cornell和Jacquard抓取数据集的检测精度达到96.4%和94.8%。通过使用UR5机器人手臂进行物理抓取实验,我们的方法也取得了90%的成功率。为了帮大家再次理解网络的输出结果,可以看下图,图中可视化了网络的输出结果。

六、结论
这篇文章的结构和GRCNN很像,并且论文中对抓取的实现方式做了详细的分类介绍,可以借鉴;论文的实验做的也比较详细,实验设计思路也可以借鉴。唯一的缺点是没有公布源码。