【深度学习】Weight Normalization: 一种简单的加速深度网络训练的重参数方法
前言:为什么要Normalization
深度学习是一种在给定数据的情况下,学习求解目标函数最小化或者最大化的模型。在深度网络中,模型参数往往包含了大量的weights和biases。在求解优化模型的时候,通常是利用一阶梯度的求解来更新网络的权重。
众所周知,优化深度网络时需要通过计算一阶梯度,而目标函数的曲率会极大的影响优化的难易度。如果目标函数的Hessian矩阵的条件数太低,将会表现出一种病理曲率的问题,其结构就是早晨一阶梯度下降会遇到问题。
(注:条件数:在数值分析领域,一个函数关于一个参数的条件数(Condition Number)测量了函数的输出值相对于输入参数的变化强度。这用来测量一个函数相对于输入变化或误差有多敏感,以及输出结果相对于输入中的误差的误差变化。)
然而一个目标函数的曲率并不是对重参数不变的,因此可以采取相同模型中多种等效的重参数方法来使得目标函数的优化空间的曲率更加的平滑。寻找一种好的重参数方法在深度学习中起着至关重要的作用。
(这里插一句题外话,作为CV领域常用的normalization, Batch Normalization,一开始Google在2013的论文声称其本质是解决ICS问题,然而最新的论文表明BN并没有解决ICS问题,其解决的是对目标函数空间增加了平滑约束,从而使得利用更大的学习率获得更好的局部优解)
Weight Normalization
对于人工神经网络中的一个神经元来说,其输出 y y y表示为:
y = ϕ ( w x + b ) y=\phi(\bm{wx}+b) y=ϕ(wx+b)
其中 w \bm{w} w是k维权重向量, b b b是标量偏差, x \bm{x} x是k维输入特征, ϕ ( . ) \phi(.) ϕ(.)是激活函数。
WN的重参数表示:对权重 w \bm{w} w用参数向量v和标量g进行表示,则新参数表示为:
w = g ∥ v ∥ v \bm{w}=\frac{g}{\|\bm{v}\|}\bm{v} w=∥v∥gv
其中 v \bm{v} v是k维向量,g是标量, ∥ v ∥ \|\bm{v}\| ∥v∥为 v \bm{v} v的欧式范数。我们注意到,此时 w \bm{w} w则被重参数为 v \bm{v} v和g两个参数。
通过上述重参数表示,我们可以发现 ∥ w ∥ = g \|\bm{w}\| =g ∥w∥=g,与参数 v \bm{v} v独立,而权重 w \bm{w} w的方向也变更为 v ∥ v ∥ \frac{v}{\|\bm{v}\|} ∥v∥v。因此重参数将权重向量 w \bm{w} w用了两个独立的参数表示其幅度和方向。实验证明,在利用SGD优化算法时,重参数加速了网络的收敛速度。
Gradients
我们对于WN重参数表示后,则对于 v \bm{v} v, g g g:
▽ g L = ▽ w L ⋅ v ∥ v ∥ \triangledown_{g} L = \frac{\triangledown_{w} L \cdot \bm{v}}{\|v\|} ▽gL=∥v∥▽wL⋅v
▽ v L = g ⋅ ▽ w L ∥ v ∥ − g ⋅ ▽ g L ∥ v ∥ ⋅ v \triangledown_{v} L = \frac{\bm{g} \cdot \triangledown_{w} L}{\|v\|} - \frac{\bm{g} \cdot \triangledown_{g} L}{\|v\|} \cdot {\bm{v}} ▽vL=∥v∥g⋅▽wL−∥v∥g⋅▽gL⋅v
其中 ▽ w L \triangledown_{w} L ▽wL为目标函数对未进行WN的权重为w的偏导。
与BN的关系
BN也作为一种参数重写的normalization,相比与BN,WN带有如下优点:WN的计算量非常低,并且其不会因为mini-batch的随机性而引入噪声统计。在RNN,LSTM,或者Reinforcement Learning上,WN能够表现出比BN更好的性能。
数据依赖的初始化
除了对深度网络的参数重写,BN还能对神经网络的每层输出进行控制。因此,BN对参数初始化有着更加鲁棒的性能。然而WN则缺少这一特性,因此参数初始化则显得尤为重要。我们提出对 v v v向量进行从一个固定范围的正态分布上采样,其中均值为0,标准差为0.05。在训练之前,我们对g和b利用初始的minibatch进行初始化。
对于每一个神经元:
t = v ⋅ x ∥ v ∥ t=\frac{v \cdot x}{\|v\|} t=∥v∥v⋅x
y = ϕ ( t − μ [ t ] σ [ t ] ) y = \phi(\frac{t-\mu[t]}{\sigma[t]}) y=ϕ(σ[t]t−μ[t])
则因为 y = ϕ ( w x + b ) y=\phi(\bm{wx}+b) y=ϕ(wx+b),因此通过初始化则将让每层layer在通过非线性激活函数之前均为0均值,方差为1:
g = 1 σ [ t ] g = \frac{1}{\sigma[t]} g=σ[t]1
b = − μ [ t ] σ [ t ] b = \frac{-\mu[t]}{\sigma[t]} b=σ[t]−μ[t]
注意:这种依赖数据的初始化方法仅仅适用在能采用BN的情况下,对RNNs或者LSTMs只能采取标准的初始化方式。
Mean-Only Batch Normalization
在每一层的layer的激活函数之前,我们发现 t = w ⋅ x = g ∥ v ∥ v ⋅ x t=\bm{w \cdot x} =\frac{g}{\|\bm{v}\|}\bm{v} \cdot x t=w⋅x=∥v∥gv⋅x,我们发现虽然我们将权重w进行分离,但是每一层的激活函数之前的输出的均值仍然与 v \bm{v} v有关。因此作者将WN与BN进行结合,采用移动平均去计算每个mini-batch上的均值 μ [ t ] \mu[t] μ[t],因此:
t = w x t ^ = t − μ [ t ] + b y = ϕ ( t ^ ) t = \bm{wx} \\ \hat{t} = t - \mu[t] + b \\ y = \phi(\hat{t}) t=wxt^=t−μ[t]+by=ϕ(t^)
对激活函数之前的t的反向传播的损失函数为:
▽ t L = ▽ t ^ L − μ [ ▽ t ^ L ] \triangledown_{t} L = \triangledown_{\hat{t}} L - \mu[\triangledown_{\hat{t}} L] ▽tL=▽t^L−μ[▽t^L]
对损失函数来说,mean-only batch normalization 可以有效的在反向传播中centering梯度。并且对于仅均值的BN来说,其计算量要小于full-BN的方法。另外,这个方法比Full-BN引入更轻微的噪声。
实验部分
作者分别做了三个方向的实验:图片识别,生成模型及深度强化学习。
- 实验一:图片识别 classification

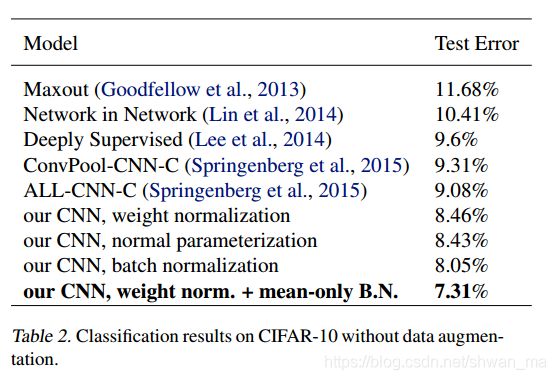
实验结果:
- 虽然BN的收敛速度最快,但是在训练中,BN在每个epoch比没有BN的网络慢16%
- WN则没有发现会导致每个epoch的训练时间增加
- WN和正常的参数初始化的错误率相似,在8.45%左右,WN+mean-only BN的错误率最低。
- 实验二:图片生成 Generative
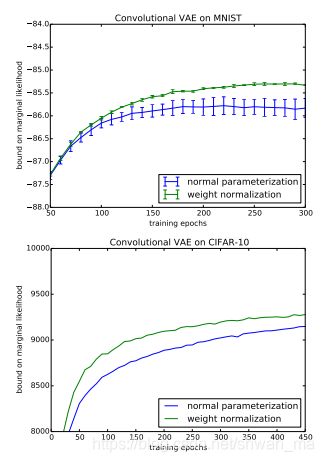
Convolutional VAE: 生成的Marginal log likelihood lower bound on the MNIST 和 CIFAR-10的结果如下两图:
DRAW:变分自编码:

- 实验三 强化学习:Reinforcement Learning: DQN:
实验总结:
发现WN在分类任务中与一般的parameterization的test error获得差不多的错误率。然而,在生成模型中,WN的实验结果却远远好于一般的parameterization。