每日一篇小论文 ---- Weight Normalization
@每日一篇小论文----arXiv:1602.07868v3
Weight Normalization
我们提出权重归一化:神经网络中权重向量的重新参数化,将那些权重向量的长度与它们的方向分离。通过以这种方式重新参数化,我们改进了优化问题的条件,并加快了随机梯度下降的收敛速度。我们的重新参数化受到批量标准化的启发,但不会在批处理中的示例之间引入任何依赖关系。这意味着我们的方法也可以成功地应用于诸如LSTM之类的递归模型以及诸如深度强化学习或生成模型的噪声敏感应用,其中批量归一化不太适合。虽然我们的方法更简单,但它仍然提供了全批量标准化的大部分加速。此外,我们的方法的计算开销较低,允许在相同的时间内采取更多的优化步骤。我们证明了我们的方法在监督图像识别,生成建模和深度强化学习中的应用的有用性。
核心思想
对方向权重做归一化,并添加scalar,
即: w = g ∣ ∣ v ∣ ∣ v w = \frac{g}{||v||}v w=∣∣v∣∣gv
意义
减弱因数据集不平均,而对于权重产生的影响
参考程序
class _WNConv(convolutional_layers._Conv):
def __init__(self, *args, **kwargs):
self.weight_norm = kwargs.pop('weight_norm')
super(_WNConv, self).__init__(*args, **kwargs)
def build(self, input_shape):
input_shape = tensor_shape.TensorShape(input_shape)
if self.data_format == 'channels_first':
channel_axis = 1
else:
channel_axis = -1
if input_shape[channel_axis].value is None:
raise ValueError('The channel dimension of the inputs '
'should be defined. Found `None`.')
input_dim = input_shape[channel_axis].value
kernel_shape = self.kernel_size + (input_dim, self.filters)
kernel = self.add_variable(name='kernel',
shape=kernel_shape,
initializer=self.kernel_initializer,
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint,
trainable=True,
dtype=self.dtype)
# weight normalization
if self.weight_norm:
g = self.add_variable(name='wn/g',
shape=(self.filters,),
initializer=init_ops.ones_initializer(),
dtype=kernel.dtype,
trainable=True)
self.kernel = tf.reshape(g, [1, 1, self.filters]) * nn_impl.l2_normalize(kernel, [0, 1])
else:
self.kernel = kernel
if self.use_bias:
self.bias = self.add_variable(name='bias',
shape=(self.filters,),
initializer=self.bias_initializer,
regularizer=self.bias_regularizer,
constraint=self.bias_constraint,
trainable=True,
dtype=self.dtype)
else:
self.bias = None
self.input_spec = base.InputSpec(ndim=self.rank + 2,
axes={channel_axis: input_dim})
self._convolution_op = nn_ops.Convolution(input_shape,
filter_shape=self.kernel.get_shape(),
dilation_rate=self.dilation_rate,
strides=self.strides,
padding=self.padding.upper(),
data_format=utils.convert_data_format(
self.data_format,
self.rank + 2))
self.built = True
以下内容参考:https://www.wengbi.com/thread_79528_1.html
为什么wn有效?
1.考虑以下情形:假设我们有60亿个id,每个id有1W张不同场景下的人脸图片,我们把这个做成一个训练集,直接用softmax去学习其分布,我们能不能说我们学到了全世界的人脸分布?答案是可以的,因为我们的test set再大,其id也不会超过全球的总人数,加之我们每个id下面的人脸图片足够多(1W)张,我们有理由确信这个分布是可信的。
2.考虑以下情形:假设现在我们只有3个id,其中第一,第二个id下面有100张很相似的人脸图片,第三个id下面只有1张。现在我们用softmax去学习其分布,并用一个2维向量表示学到的特征,那么它的分布应该是下面这样的(二维可视化):
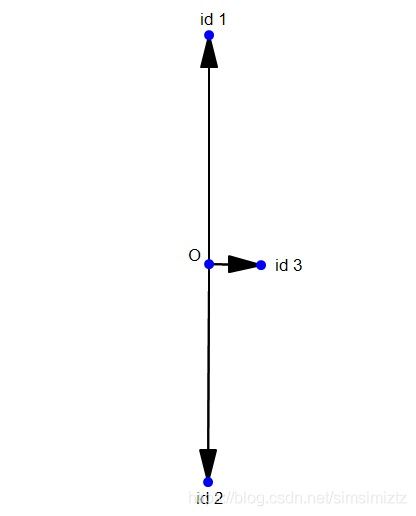
可以自己模拟一下,会发现这种情况下的softmax loss是最小的。也就是说,由于id1和id2的图片数量远大于id3的图片数量,导致id3在分类的时候基本处于一个随波逐流的状态。那么id3肯定不乐意的,同样都是人,为什么差距就那么大呢?没办法,谁让你底下只有1张图片呢?
但是我们自己肯定是有个判断的:id3是绝对可以拿出100张人脸图片的,只是在这个训练集中他没有拿出100张,他只拿出了1张。
这就好比我们丢硬币猜正反面,我们丢了10次硬币,其中有9次是正面,1次是背面。那么我们会预测下一次是正面的概率是90%吗?不是,我们知道概率是50%。相比于贝叶斯的先验概率,我们有一个更强的先验概率。
对于人脸同样如此,我们做Weight Normalization,正是因为我们可以主观上判定:每一个人都可以拿出同样多的人脸图片。
那么做了Weight Normalization,上面的可视化会变成这样的:
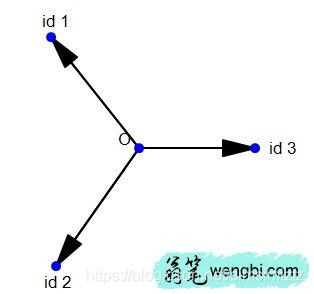
是不是瞬间就感觉合理多了。
3.上面这个例子还缺少一个充分条件,那就是id的weight长度是和id下面的人脸图片数量是成正比的。关于这一点,Guo Yandong在其论文里面做了详细的实验:
论文: One-shot Face Recognition by Promoting Underrepresented Classes
作者自己建了一个人脸base数据集,也就是我之前提到的MS_20K,包括20K个id,每个id下面有50-100张人脸图片;然后作者建立了一个novel数据集,包括1K个id,每个id下面有20张图片,作者称其为low shot learning,也就是为了探究样本不均衡的问题。