Keras基本用法
参考 Keras基本用法 - 云+社区 - 腾讯云
Keras是目前使用最为广泛的深度学习工具之一,它的底层可以支持TensorFlow、MXNet、CNTK和Theano。如今,Keras更是被直接引入了TensorFlow的核心代码库,成为TensorFlow官网提供的高层封装之一。下面首先介绍最基本的Keras API,下面给出一个简单的样例,然后介绍如何使用Keras定义更加复杂的模型以及如何将Keras和原生态TensorFlow结合起来。
1、Keras基本用法
和TFLearn API类似,Keras API也对模型定义、损失函数、训练过程等进行了封装,而且封装之后的整个训练过程和TFLearn是基本一致的,可以分为数据处理、模型定义和模型训练三个部分。使用原生态的Keras API需要先安装Keras包,安装的方法如下:
pip install keras以下代码展示了如何使用原生态Keras在MNIST数据集上实现LeNet-5模型。
# -*- coding: utf-8 -*-
import keras
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Flatten, Conv2D, MaxPooling2D
from keras import backend as K
num_classes = 10
img_rows, img_cols = 28, 28
(trainX, trainY), (testX, testY) = mnist.load_data()
if K.image_data_format() == 'channels_first':
trainX = trainX.reshape(trainX.shape[0], 1, img_rows, img_cols)
testX = testX.reshape(testX.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
trainX = trainX.reshape(trainX.shape[0], img_rows, img_cols, 1)
testX = testX.reshape(testX.shape[0], img_rows, img_cols, 1)
input_shapes = (img_rows, img_cols, 1)
trainX = trainX.astype('float32')
testX = testX.astype('float32')
trainX /= 255.0
testX /= 255.0
trainY = keras.utils.to_categorical(trainY, num_classes)
testY = keras.utils.to_categorical(testY, num_classes)
model = Sequential()
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(64, (5,5), activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(500, activation='relu'))
model.add(Dense(num_classes, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer = keras.optimizers.SGD(),
metrics = ['accuracy'])
model.fit(trainX, trainY, batch_size=128, epochs=20, validation_data=(testX, testY))
score = model.evaluate(testX, testY)
print('Test loss:',score[0])
print('Test accuracy', score[1])
-------------------------------------------------------------
Output:
32/10000 [..............................] - ETA: 0s
608/10000 [>.............................] - ETA: 0s
1152/10000 [==>...........................] - ETA: 0s
1664/10000 [===>..........................] - ETA: 0s
2112/10000 [=====>........................] - ETA: 0s
2560/10000 [======>.......................] - ETA: 0s
3008/10000 [========>.....................] - ETA: 0s
3424/10000 [=========>....................] - ETA: 0s
3840/10000 [==========>...................] - ETA: 0s
4256/10000 [===========>..................] - ETA: 0s
4704/10000 [=============>................] - ETA: 0s
5152/10000 [==============>...............] - ETA: 0s
5600/10000 [===============>..............] - ETA: 0s
6112/10000 [=================>............] - ETA: 0s
6624/10000 [==================>...........] - ETA: 0s
6944/10000 [===================>..........] - ETA: 0s
7104/10000 [====================>.........] - ETA: 0s
7232/10000 [====================>.........] - ETA: 0s
7360/10000 [=====================>........] - ETA: 0s
7488/10000 [=====================>........] - ETA: 0s
7648/10000 [=====================>........] - ETA: 0s
7840/10000 [======================>.......] - ETA: 0s
8096/10000 [=======================>......] - ETA: 0s
8256/10000 [=======================>......] - ETA: 0s
8480/10000 [========================>.....] - ETA: 0s
8640/10000 [========================>.....] - ETA: 0s
8864/10000 [=========================>....] - ETA: 0s
9120/10000 [==========================>...] - ETA: 0s
9280/10000 [==========================>...] - ETA: 0s
9408/10000 [===========================>..] - ETA: 0s
9664/10000 [===========================>..] - ETA: 0s
9824/10000 [============================>.] - ETA: 0s
9984/10000 [============================>.] - ETA: 0s
10000/10000 [==============================] - 2s 178us/step
Test loss: 0.09795796233266592
Test accuracy 0.970300018787384
-------------------------------------------------------------------从以上代码中可以看出使用Keras API训练模型可以先定义一个Sequential类,然后在Sequential实例中通过add函数添加网络层。Keras把卷积层、池化层、RNN结构(LSTM、GRU),全连接层等常用的神经网络结构都做了封装,可以很方便地实现深层神经网络。在神经网络结构定义好之后,Sequential实例可以通过compile函数,指定优化函数、损失函数以及训练过程中需要监控等指标。Keras对优化函数、损失函数以及监控指标都有封装,同时也支持使用自定义的方式,在Keras的API文档中有详细的介绍,这里不再赘述。最后在网络结构、损失函数和优化函数都定义好之后,Sequential实例可以通过fit函数来训练模型。类似TFLearn中的fit函数,Keras的fit函数只需给出训练数据,batch大小和训练轮数,Keras就可以自动完成模型训练的整个过程。
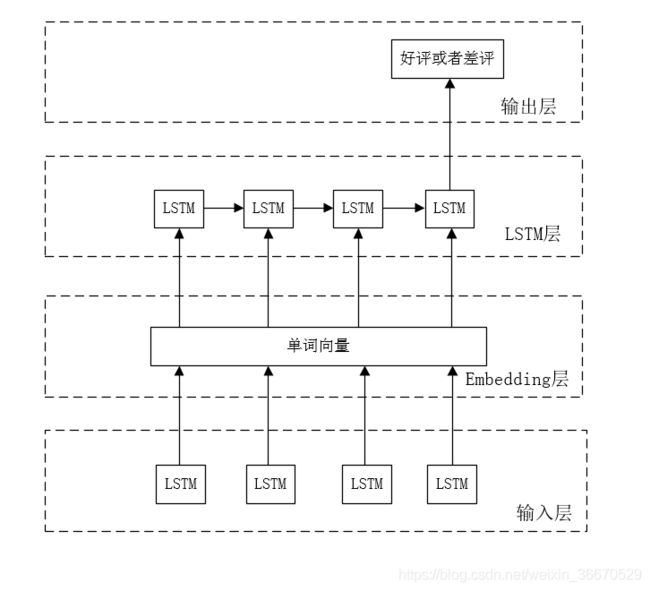
除了能够很方便地处理图像问题,Keras对训练神经网络的支持也是非常出色的。有了Keras APA,循环神经网络的训练体系也可以通过简单的一句命令完成。以下代码给出了如何通过Keras实现自然语言感情分类问题。使用循环网络判断语言的感情(比如在以下例子中需要判断一个评价是好评还是差评)和自然语言建模问题类似,唯一的区别在于除了最后一个时间点的输出是有意义的,其他时间点的输出都可以忽略,下图展示了使用循环网络处理感情分析问题的模型结构。
# -*- coding: utf-8 -*-
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers import Dense, Embedding
from keras.layers import LSTM
from keras.datasets import imdb
# 最多使用的单词数。
max_features = 20000
# 循环神经网络的截断长度。
maxlen = 80
batch_size = 32
# 加载数据并将单词转化为ID, max_features给出了最多使用的单词数。和自然语言模型类似,会将出现频率 # 较低的单词替换为统一的ID,通过Keras封装的API生成25000条训练数据和25000条测试数据,每一条数据可以
# 摆看成一段话,并且每段话都有一个好评或者差评的标签。
(trainX, trainY), (testX, testY) = imdb.load_data(num_words=max_features)
print(len(trainX), 'train sequences')
print(len(trainY), 'test_sequences')
# 在自然语言处理中,每一段话的长度都是不一样的,但循环神经网络的循环长度是固定的,所以这里需要首先
# 将所有段落统一成固定长度。对于长度不够的段落,要使用默认值0来填充,对于超过长度
# 的段落则直接忽略掉超过的部分。
trainX = sequence.pad_sequences(trainX, maxlen = maxlen)
testX = sequence.pad_sequences(testX, maxlen=mexlen)
# 输出统一长度之后的数据维度:
# ('x_train shape:', (25000, 80))
# ('x_test shape:', (25000, 80))
print('trainX shape:', trainX.shape)
print('testX shape:', trainX.shape)
# 再完成数据预处理之后的模型结构
model = Sequential()
# 构建embedding层。128代表了embedding层的向量维度。
model.add(Embedding(max_features, 128))
# 构建LSTM层。
model.add(LSTM(128,dropout=0.2))
# 构建最后的全连接层。注意在上面构建LSTM层时只会得到最后一个节点输出,
# 如果需要输出每个时间点的结果,那么可以将return_sequence参数设置为true。
model.add(Dense(1, activation='sigmoid'))
# 与MNIST样例类似地指定损失函数,优化函数和评测指标。
model.compile(loss='binary_crossentropy',optimizer='adam',metrics=['accuracy'])
# 与MNIST样例类似地指定训练数据,训练轮数,batch大小以及验证数据。
model.fitt(trainX, trainY, batch_size=batch_size, epochs=15, validation_data=(testX, testY))
# 在测试数据上评测模型
score = model.evaluate(testX, testY, batch_size=batch_size)
print('Test loss:', score[0])
print('Test accuracy:',score[1])以上两个样例针对Keras的基本用法做了详细的介绍。虽然Keras的封装,很多经典的神经网络结构能很快地被实现,不过要实现一些更加灵活的网络结构、损失函数或者数据输入方法,就需要对Keras的高级用法有更多的了解。
2、Keras高级用法
上面样例中最重要的封装就是Sequential类,所有的神经网络定义和训练都是通过Sequential实例来实现的。然而从这个类的名称可以看出,它只支持顺序模型的定义。类似Inception这样的模型结构,通过Sequential类就不容易直接实现了。为了支持更加灵活的模型定义方法,Keras支持以返回值的形式定义网络层结构。以下代码展示了如何使用这种方式定义模型。
# -*- coding:utf-8 -*-
import keras
from keras.datasets import mnist
from keras.layers import Input, Dense
from keras.models import Model
# 使用1中介绍的类似方法生成trainingX、trainingY、testX、testY,唯一的
# 不同是这里只使用了全连接层,所以不需要将输入整理成三维矩阵。
...
# 定义输入,这里指定的维度不用考虑batch大小。
inputs = Input(shape=(784,))
# 定义一层全连接,该层有500隐藏节点,使用ReLU激活函数,这一层的输入为inputs。
x = Dense(500, activate='relu')(inputs)
# 定义输出层。注意因为keras封装需要指定softmax作为激活函数。
predictions = Dense(10, activate='softmax')(x)
# 通过Model类创建模型,和Sequential类不同的是Model类在初始化的时候需要指定模型的输入和输出。
model = Model(inputs=inputs, outputs=predictions)
# 与1中类似的方法定义损失函数、优化函数和评测方法。
model.complie(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(),metrics=['accuracy'])
# 与1中类似的方法训练模型。
model.fit(trainX, trainY, batch_size=128, epoches=20, validation_data=(testX, testY))通过这样的方式,Keras就可以实现类似Inception这样大的模型结构。以下代码展示了如何通过Keras实现Inception结构。
from keras.layers import Conv2D, MaxPooling2D, Input
# 定义输入图像尺寸
input_img = Input(shape=(256,256,3))
# 定义第一个分支。
tower_1 = Conv2D(64,(1,1),padding='same',activation='relu')(input_img)
tower_1 = COnv2D(64,(3,3),padding='same',activation='relu')(tower_1)
# 定义第二个分支。与顺序模型不同,第二个分支的输入使用的是input_img,而不是第一个分支的输出。
tower_2 = Conv2D(64,(1,1),padding='same',activation='relu')(input_img)
tower_2 = Conv2D(65,(5,5),padding='same',activation='relu')(tower_2)
# 定义第三个分支。类似地,第三个分支的输入也是input_img,
tower_3 = MaxPooling2D((3,3),strides=(1,1),padding='same')(input_img)
tower_3 = Conv2D(64, (1,1), padding='same', activation='relu')(tower_3)
# 将第三个分支通过concatenate的方式拼接在一起
output = keras.layers.concatenate([tower_1, tower_2, tower_3], axis = 1)
除了可以支持顺序模型,Keras也可以支持有多个输入或者输出的模型。以下代码实现了下图所示的网络结构。

# -*- coding: utf-8 -*-
import keras
from tflearn,layers.core import fully_connected
from keras.datasets import mnist
from keras.layers import Input, Dense
from keras.models import Model
# 类似1的方式生成trainX, trainY, testX, testY
# 定义两个输入,一个输入为原始的图片信息,另一个输入为正确答案。
input1 = Input(shape=(784,), name="input1")
input2 = Input(shape=(10,), name="input2")
# 定义一个只有一个隐藏节点的全连接网络。
x = Dense(1, activation='relu')(input1)
# 定义只使用了一个隐藏节点的网络结构的输出层。
output1 = Desnse(10, activation='softmax',name="output1")(x)
# 将一个隐藏节点的输出和正确答案拼接在一起,这个将作为第二个输出层的输入。
y = keras.layers.concatenate([x, input2])
# 定义第二个输出层。
input3 = Dense(10, activation='softmax', name = "output2")(y)
# 定义一个有多个输入和多个输出的模型。这里只需要将所有的输入和输出给出即可。
model = Model(inputs=[inputs1, inputs2], outputs = [output1, output2])
# 定义损失函数、优化函数和测评方法。若多个输出的损失函数相同,可以只指定一个损失函数。
# 如果多个输出的损失函数不同,则可以通过一个列表或一个字典来指定每一个输出的损失函数。
# 比如可以使用:
# loss = {'output1':binary_crossentropy,'output2':binary_crossentropy}
# 求为不同的输出指定不同的损失函数。类似地,Keras也支持为不同输出产生的损失指定权重,
# 这可以通过loss_weights参数来完成。在下面的定义中,输出output1的权重为1,output2的
# 权重为0.1,所以这个模型会更加偏向于优化的第一个输出。
model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), loss_weights = [1,0.1], metrics = ['accuracy'])
# 模型训练过程。因为有两个输入和输出,所以这里提供的数据也需要有两个输入和两个期待的正确答案输出。
# 通过列表的方式提供数据时,Keras会假设数据给出的顺序和定义Model类时输入会给出的顺序是对应的。为 # 了避免顺序不一致导致的问题,推荐使用字典的形式给出:
# model.fit(
# {'input1':trainX, 'input2':trainY}
# {'output1':trainX, 'output2':trainY}
# ...)
model.fit([trainX, trainY], [trainY, trainY], batch_size=128, epochs=20, validation_data=([testX, testY], [testX, testY]))从以上输出可以看出Keras在训练过程中会展示每个输出层的loss和accuracy。因为输出层output1只使用了一个维度为1的隐藏点,所以正确率只有29.85%。虽然输出层output2使用了正确答案作为输入,但是因为在损失函数中权重较低(只有0.1),所以它的收敛速度较慢,在20个epoch时准确率也只有92.1%。如果将两个输出层的损失权重设为一样,那么输出层output1在20个epoch时的准确率将只有27%,而输出层output2的准确率可以达到99.9%。虽然通过返回值的方式已经可以实现大部分的神经网络模型,然而Keras API还存在两大问题。第一,原生态Keras API对训练数据的处理流程支持得不太好,基本上需要一次性将数据全部全部加载到内存。第二,原生态Keras API无法支持分布式训练。为了解决这两个问题,Keras提供了一种与原生态TensorFlow结合地更加紧密的方式。以下代码显示了如何将Keras和原生态TensorFlow API联合起来解决MNIST问题。
# -*- coding: utf-8 -*-
import tensorflow as tf
from tensorflow.example.tutorials.mnist import input_data
mnist_data=input_data.read_data_sets('/path/to/MNIST_data', one_hot=True)
# 通过TensorFlow中的placeholder定义输入。类似的,Keras封装数据的网络层结构也可以支持队列输入。
# 这样可以有效避免一次性加载所有数据的问题。
x = tf.placeholder(tf.float32, shape=(None, 764))
y_ = tf.placeholder(tf.float32, shape=(None, 10))
# 直接使用TensorFlow中提供的Keras API定义网络层结构。
net = tf.keras.layers.Dense(500, activate='relu')(x)
y = tf.keras.layers.Dense(10, activation='softmax')(net)
# 定义损失函数和优化方法。注意这里可以混用Keras的API和原生态TensorFlow的API。
loss = tf.reduce_mean(tf.keras.losses.categorical_crossentropy(y_, y))
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(loss)
# 定义正确的预测率作为指标。
acc_value = tf.reduce_mean(tf.keras.metric.categorical_accuracy(y_, y))
# 使用原生态TensorFlow的方式训练模型。这样就可以有效的实现分布式。
with tf.Session() as sess:
tf.global_variables_initializer().run()
for i in range(10000):
xs, ys = mnist_data.train.next_batch(100)
_, loss_value = sess.run([train_step, loss], feed_dict={x:xs, y_:ys})
if i % 1000 == 0:
print("After %d training step(s), loss on training batch is " "%g." % (i, loss_value))
print acc_value.eval(feed_dict={x:mnist_data.test.images, y_: mnist_data.test.labels})3、Keras的主要模块、类和函数
Modules
- activations module: Built-in activation functions.
- applications module: Keras Applications are canned architectures with pre-trained weights.
- backend module: Keras backend API.
- callbacks module: Callbacks: utilities called at certain points during model training.
- constraints module: Constraints: functions that impose constraints on weight values.
- datasets module: Keras built-in datasets.
- estimator module: Keras estimator API.
- experimental module: Public API for tf.keras.experimental namespace.
- initializers module: Keras initializer serialization / deserialization.
- layers module: Keras layers API.
- losses module: Built-in loss functions.
- metrics module: Built-in metrics.
- mixed_precision module: Public API for tf.keras.mixed_precision namespace.
- models module: Code for model cloning, plus model-related API entries.
- optimizers module: Built-in optimizer classes.
- preprocessing module: Keras data preprocessing utils.
- regularizers module: Built-in regularizers.
- utils module: Keras utilities.
- wrappers module: Wrappers for Keras models, providing compatibility with other frameworks.
Classes
- class Model:
Modelgroups layers into an object with training and inference features. - class Sequential: Linear stack of layers.
Functions
- Input(...):
Input()is used to instantiate a Keras tensor.