(39)CUDA out of memory. Tried to allocate 76.00 MiB (GPU 0; 10.76 GiB total capacity; 8.45 GiB ...
问题描述:
在两块2080Ti显卡上训练去雾算法FFANet(gps=3, blocks=19),batch=2恰好能够正常训练,训练结束进行模型测试,每次读取一张图片进行模型推理,结果报错显存不够:
RuntimeError: CUDA out of memory. Tried to allocate 76.00 MiB (GPU 0; 10.76 GiB total capacity; 8.60 GiB already allocated; 75.19 MiB free; 8.61 GiB reserved in total by PyTorch)分析:训练时候batch=2,一次读入两张图片,由于是去雾网络训练,所以正常情况batch=2时,读入的是两张清晰图像和对应的两张有雾图像,共四张图像。所以推理的时候,一次性读入一张图像显存足够,因此不是数据的问题,debug发现数据载入和模型加载都没有问题,下面是test的部分代码:
dehaze_net = net.dehaze_net(gps=3,blocks=19).cuda()
dehaze_net = torch.nn.DataParallel(dehaze_net)
cudnn.benchmark = True
dehaze_net.load_state_dict(torch.load('logs/logs1/Epoch100-Total_Loss0.0036-Val_Loss0.0000.pth'))
clean_image = dehaze_net(data_hazy)经查阅资料,找到报错显存不足的以下几种情况:
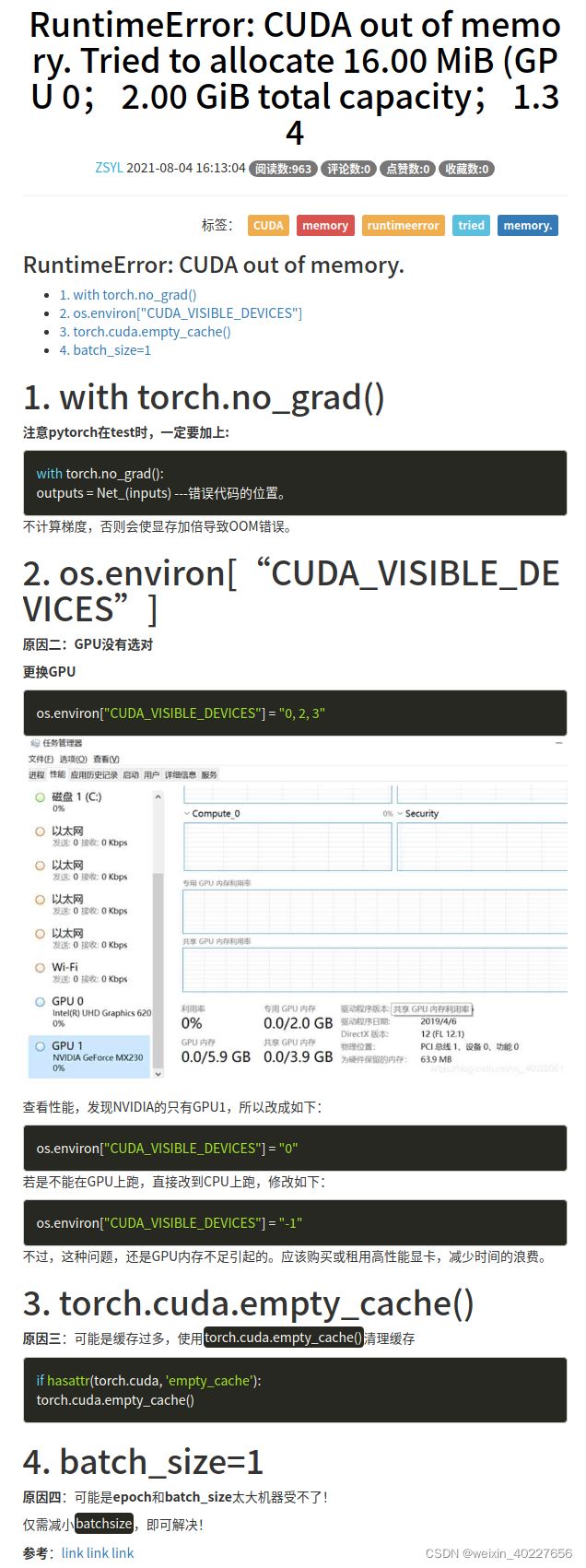
参考:
RuntimeError: CUDA out of memory. Tried to allocate 16.00 MiB (GPU 0; 2.00 GiB total capacity; 1.34
【E-02】内存不足RuntimeError: CUDA out of memory. Tried to allocate 16.00 MiB (GPU 0; 2.00 GiB total capacity; 1.34 GiB already allocated; 14.76 MiB free; 1.38 GiB reserved in total by PyTorch) - 忆凡人生 - 博客园
2020-03-19 RuntimeError: CUDA out of memory. Tried to allocate 38.00 MiB (GPU 0; 10.76 GiB total ... - 简书
RuntimeError: CUDA out of memory. Tried to allocate 14.00 MiB (GPU 0; 6.00 G)的解决【实测成功】_captain飞虎大队的博客-CSDN博客
问题解决:
综合分析发现在推理时,没有添加
with torch.no_grad():
导致在测试推理时,模型仍在计算梯度信息,虽然没有反向传播无法改变网络参数,但是会导致计算量和参数量大大增加,从而增加显存的占用,因此,将测试代码修改如下:
dehaze_net = net.dehaze_net(gps=3,blocks=19).cuda()
dehaze_net = torch.nn.DataParallel(dehaze_net)
cudnn.benchmark = True
dehaze_net.load_state_dict(torch.load('logs/logs1/Epoch100-Total_Loss0.0036-Val_Loss0.0000.pth'))
with torch.no_grad():
clean_image = dehaze_net(data_hazy)问题解决。