Rope3d数据集分析
建议看给的链接里的内容,下面的都是自己的一些理解,会有不准确的地方,欢迎批评指正。
这些数据集还不太会使用,希望大佬们提出宝贵的意见。
---------------------------------------------------------------------------------------------------------------------------------
一、链接
数据集文献:https://openaccess.thecvf.com/content/CVPR2022/html/Ye_Rope3D_The_Roadside_Perception_Dataset_for_Autonomous_Driving_and_Monocular_CVPR_2022_paper.html
数据集:
https://thudair.baai.ac.cn/rope
处理数据集(开发代码):
GitHub - liyingying0113/rope3d-dataset-tools
参考:
DAIR-V2X车路协同数据集 (baai.ac.cn)
这个链接里讲的很细,我就不复制粘贴了,就只记录一下自己的感悟吧~
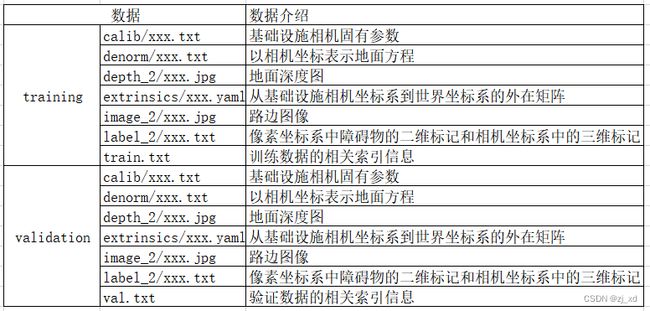
二、数据集整体内容
如下图所示(原图见DAIR-V2X车路协同数据集 (baai.ac.cn)):
三、关于数据集,我的理解
看了数据集文献之后,大致能知道每个数据讲的是什么了。
training和validation的格式都一样,都是KITTI格式。
1.calib (calibration)---基础设施相机固有参数
格式如下:
P2: 2188.969252 0.000000 982.541072 0 0.000000 2334.065991 530.992877 0 0.000000 0.000000 1.000000 0
从mmdetection3d的说明文档里看到:

为什么要有这个投影矩阵呢?
文献中3.1的Coordinate Systems and Calibration里是这样说的:

直译:
数据集中使用了三种坐标系统:世界坐标(即通用横向墨卡托坐标系(UTM坐标))、摄像机坐标以及激光雷达坐标。
为了获得可靠的地真度2D-3D联合标注,需要不同传感器之间的标定(calibration)。
首先,对Camera进行标定,通过检测棋盘图获得本征(intrinsics),
然后由车辆定位模块进行Lidar-to-World的标定,在UTM Coord中获得高清地图。在World-to-Camera的标定中,我们首先将包含车道和人行横道端点的高清地图投影到2D图像上,获得原始变换。随后进行束调整细化,以获得最终的转换。
然后通过简单地乘以lidar-to-World和World-to-Camera的转换就可以得到Lidar-to-Camera的转换。
在得到三个坐标系之间的变换后,我们可以通过将接地点[x,y,z](ground point)拟合到摄像机坐标中的接地平面(ground plane),即αx+βy+γz+ d= 0,轻松计算出接地方程G(α, β, γ, d).
看下图方便理解:
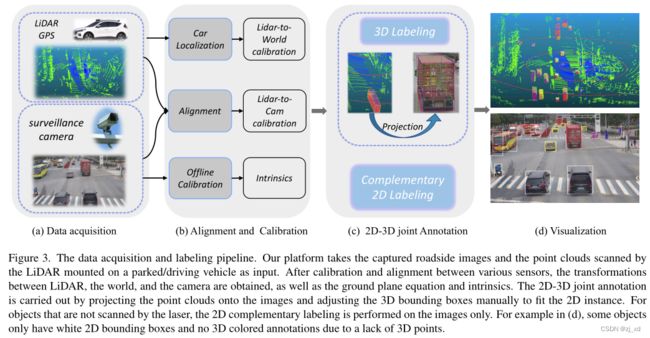
图中介绍的直译:
图3。数据采集和标记pipeline。我们的平台将捕获的路边图像和安装在停放/行驶车辆上的激光雷达扫描的点云作为输入。通过各种传感器之间的标定(calibration)和对齐,得到LiDAR、World和Camera之间的变换,以及地平面方程和本征。2D-3D联合标注是通过将点云投影到图像上并手动调整3D边界框以适应2D实例来实现的。对于未被激光扫描的物体,只对图像进行二维补充标记。例如,在(d)中,一些对象只有白色的2D边界框,没有3D彩色注释,因为缺乏3D点。
2.denorm
以相机坐标表示地面位置。
格式:
0.008187128 -0.975265 -0.2208872 7.23388195038
我理解的是接地方程的解G(α, β, γ, d)。
3.depth
深度图的大小和image里图像的大小是一样的,文献中说3Dobject分布在10~140m,大多数在60~80 m。
depth样例如下图:

文中还提到了一个深度图的用法,是在介绍单目3D单目检测时提到的,是利用现成的深度估计器把图像像素转换成伪雷达点云。
4.extrinsics
从基础设施相机坐标系到世界坐标系的外在矩阵,yaml文件,格式如下图所示:
child_frame_id: camera1
header:
frame_id: world
seq: 0
stamp:
nsecs: 0
secs: 0
matched_points: 0
points_ground_coffe:
- 461658.6658612792
- 4406589.451878548
- 14.95037841796875
.
.
.
transform:
rotation:
w: -0.1692714123924695
x: 0.2125247456622584
y: -0.7510155914854161
z: 0.6017939869869603
translation:
x: 461628.1622675338
y: 4406614.309054163
z: 21.98328398585188
中间省去了将近9000个数,格式与- 14.95037841796875相同
5.image—2
由不同传感器拍摄的图片:

6.label——2
kitti格式的标签,样例如下:
trafficcone 0 0 2.8233288222806237 1615.88208 349.272003 1628.89624 383.210327 0.709856 0.301356 0.162486 16.0145106961 -4.08680757179 51.3620837615 3.12557252261
标注格式介绍:
类别里除了上述的,还有trafficcone,unknown_unmovable,unknown_movable,triangle plate。
7.train.txt
本文件里面写的主要是图片的名称
格式如下:
145418_fa2sd4a13W152AIR_420_1626246966_1626246983_18_obstacle
1901_fa2sd4adatasetf328h9k14camera151_420_1629886829_1629887126_257_obstacle
1784_fa2sd4adatasetWest152_420_1621245269_1621245419_37_obstacle
1679_fa2sd4adatasetNorth151_420_1616056928_1616057233_186_obstacle