NLP-文本处理:依存句法分析(主谓、动宾、动补...)【基于“分词后得到的词语列表A”+“A进行词性标注后得到的词性列表B”来进行依存句法分析】【使用成熟的第三方工具包】
句法分析(syntactic parsing)是自然语言处理中的关键技术之一,它是对输入的文本句子进行分析以得到句子的句法结构的处理过程。对句法结构进行分析,一方面是语言理解的自身需求,句法分析是语言理解的重要一环,另一方面也为其它自然语言处理任务提供支持。例如句法驱动的统计机器翻译需要对源语言或目标语言(或者同时两种语言)进行句法分析。
第三方工具包:
哈工大LTP首页
哈工大LTP4 文档
语义角色类型
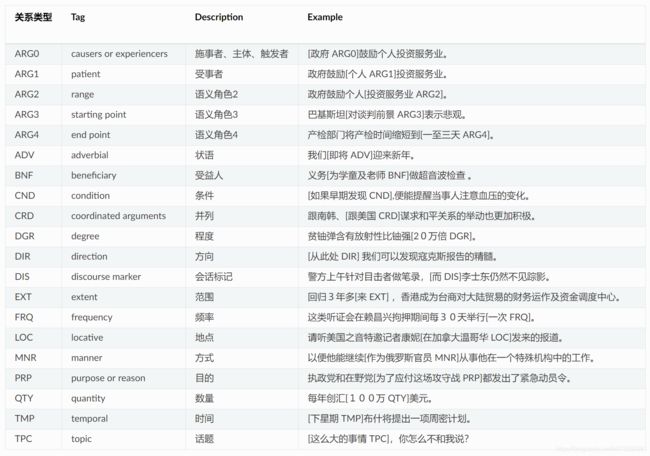
依存句法关系

语义依存关系

import os
from pyltp import Segmentor, Postagger, Parser, NamedEntityRecognizer, SementicRoleLabeller
# pip install pyltp -i https://pypi.tuna.tsinghua.edu.cn/simple 可以先下载好whl文件
#LTP语言平台:http://ltp.ai/index.html
#咱们使用的工具包,pyltp:https://pyltp.readthedocs.io/zh_CN/latest/api.html
#LTP附录:https://ltp.readthedocs.io/zh_CN/latest/appendix.html#id3
#安装方法:https://github.com/HIT-SCIR/pyltp
class LtpParser:
def __init__(self):
LTP_DIR = "./ltp_data_v3.4.0"
self.segmentor = Segmentor() # 分词
self.segmentor.load(os.path.join(LTP_DIR, "cws.model"))
self.postagger = Postagger() # 词性标注
self.postagger.load(os.path.join(LTP_DIR, "pos.model"))
self.parser = Parser() # 句法依存分析
self.parser.load(os.path.join(LTP_DIR, "parser.model"))
self.recognizer = NamedEntityRecognizer() # 命名实体识别
self.recognizer.load(os.path.join(LTP_DIR, "ner.model"))
self.labeller = SementicRoleLabeller() # 语义角色标注
self.labeller.load(os.path.join(LTP_DIR, 'pisrl_win.model'))
# 依存句法分析【为句子中的每个词语维护一个保存句法依存儿子节点的字典】
def build_parse_child_dict(self, words, postags): # words:分词后的结果;postags:词性标注后的结果;arcs:依存句法分析树
child_dict_list = []
format_parse_list = []
arcs = self.parser.parse(words, postags) # 建立依存句法分析树
print("分词列表:words = {}".format(words))
print("词性分析:postags = {}".format(postags))
rely_ids = [arc.head - 1 for arc in arcs] # 提取该句话的每一个词的依存父节点id【0为ROOT,词语从1开始编号】: [2, 0, 2, 5, 8, 8, 6, 3] - 1 = [1, -1, 1, 4, 7, 7, 5, 2]【此时 -1 表示ROOT】
print("各个词语所依赖的父节点:rely_ids = {0}".format(rely_ids))
heads = ['Root' if rely_id == -1 else words[rely_id] for rely_id in rely_ids] # 匹配依存父节点词语
print("各个词语所依赖的父节点词语 = {0}".format(heads))
relations = [arc.relation for arc in arcs] # 提取依存关系
print("各个词语与所依赖的父节点的依赖关系 = {0}".format(relations))
for word_index in range(len(words)):
print("\n")
print("word_index = {0}----word = {1}".format(word_index, words[word_index]))
child_dict = dict() # 每个词语与所有其他词语的关系字典
for arc_index in range(len(arcs)): # arc_index==0时表示ROOT【还没进入“我想听一首迪哥的歌”语句】,arc_index==1时表示“我”
# 当“依存句法分析树”遍历,遇到当前词语时,说明当前词语在依存句法分析树中与其他词语有依存关系
if word_index == rely_ids[arc_index]: # arcs[arc_index].head 表示arcs[arc_index]所代表的词语依存弧的父结点的索引。 ROOT 节点的索引是 0 ,第一个词开始的索引依次为1,2,3,···【“我”的索引为1】arc. relation 表示依存弧的关系。
print("word_index = {0}----arc_index = {1}----rely_ids[arc_index] = {2}----relations[arc_index] = {3}".format(word_index, arc_index, rely_ids[arc_index], relations[arc_index]))
if relations[arc_index] in child_dict: # arcs[arc_index].relation表示arcs[arc_index]所代表的词语与父节点的依存关系(语法关系)
child_dict[relations[arc_index]].append(arc_index) # 添加 child_dict = {'ATT': [4]}----> child_dict = {'ATT': [4, 5]}
else:
child_dict[relations[arc_index]] = [] # 新建
child_dict[relations[arc_index]].append(arc_index) # child_dict = {[]}----> child_dict = {'ATT': [4]}
print("child_dict = {0}".format(child_dict))
child_dict_list.append(child_dict)# 每个词对应的依存关系父节点和其关系
print("\nchild_dict_list = {0}".format(child_dict_list))
# 整合每个词语的句法依存关系
print()
for i in range(len(words)):
a = [relations[i], words[i], i, postags[i], heads[i], rely_ids[i]-1, postags[rely_ids[i]-1]]
print("整合每个词语的句法依存关系---->a = {}".format(a))
format_parse_list.append(a)
return child_dict_list, format_parse_list
'''parser主函数'''
def parser_main(self, sentence):
# 分词
words = list(self.segmentor.segment(sentence))
# 词性标注
postags = list(self.postagger.postag(words))
# 依存句法分析
child_dict_list, format_parse_list = self.build_parse_child_dict(words, postags)
return words, postags, child_dict_list, format_parse_list
if __name__ == '__main__':
parse = LtpParser()
sentence = '我想听一首迪哥的歌'
words, postags, child_dict_list, format_parse_list = parse.parser_main(sentence)
print("\n\n\n分词-->len(words) = {0}----words = {1}".format(len(words), words))
print("\n词性标注-->len(postags) = {0}----postags = {1}".format(len(postags), postags))
print("\n依存句法分析-->每个词对应的依存关系儿子节点和其关系-->len(child_dict_list) = {0}----child_dict_list = {1}".format(len(child_dict_list), child_dict_list))
print("\n依存句法分析--整合-->len(format_parse_list) = {0}----format_parse_list = {1}".format(len(format_parse_list), format_parse_list))
输出结果:
分词列表:words = ['我', '想', '听', '一', '首', '迪哥', '的', '歌']
词性分析:postags = ['r', 'v', 'v', 'm', 'q', 'nh', 'u', 'n']
各个词语所依赖的父节点:rely_ids = [1, -1, 1, 4, 7, 7, 5, 2]
各个词语所依赖的父节点词语 = ['想', 'Root', '想', '首', '歌', '歌', '迪哥', '听']
各个词语与所依赖的父节点的依赖关系 = ['SBV', 'HED', 'VOB', 'ATT', 'ATT', 'ATT', 'RAD', 'VOB']
word_index = 0----word = 我
child_dict_list = [{}]
word_index = 1----word = 想
word_index = 1----arc_index = 0----rely_ids[arc_index] = 1----relations[arc_index] = SBV
child_dict = {'SBV': [0]}
word_index = 1----arc_index = 2----rely_ids[arc_index] = 1----relations[arc_index] = VOB
child_dict = {'SBV': [0], 'VOB': [2]}
child_dict_list = [{}, {'SBV': [0], 'VOB': [2]}]
word_index = 2----word = 听
word_index = 2----arc_index = 7----rely_ids[arc_index] = 2----relations[arc_index] = VOB
child_dict = {'VOB': [7]}
child_dict_list = [{}, {'SBV': [0], 'VOB': [2]}, {'VOB': [7]}]
word_index = 3----word = 一
child_dict_list = [{}, {'SBV': [0], 'VOB': [2]}, {'VOB': [7]}, {}]
word_index = 4----word = 首
word_index = 4----arc_index = 3----rely_ids[arc_index] = 4----relations[arc_index] = ATT
child_dict = {'ATT': [3]}
child_dict_list = [{}, {'SBV': [0], 'VOB': [2]}, {'VOB': [7]}, {}, {'ATT': [3]}]
word_index = 5----word = 迪哥
word_index = 5----arc_index = 6----rely_ids[arc_index] = 5----relations[arc_index] = RAD
child_dict = {'RAD': [6]}
child_dict_list = [{}, {'SBV': [0], 'VOB': [2]}, {'VOB': [7]}, {}, {'ATT': [3]}, {'RAD': [6]}]
word_index = 6----word = 的
child_dict_list = [{}, {'SBV': [0], 'VOB': [2]}, {'VOB': [7]}, {}, {'ATT': [3]}, {'RAD': [6]}, {}]
word_index = 7----word = 歌
word_index = 7----arc_index = 4----rely_ids[arc_index] = 7----relations[arc_index] = ATT
child_dict = {'ATT': [4]}
word_index = 7----arc_index = 5----rely_ids[arc_index] = 7----relations[arc_index] = ATT
child_dict = {'ATT': [4, 5]}
child_dict_list = [{}, {'SBV': [0], 'VOB': [2]}, {'VOB': [7]}, {}, {'ATT': [3]}, {'RAD': [6]}, {}, {'ATT': [4, 5]}]
整合每个词语的句法依存关系---->a = ['SBV', '我', 0, 'r', '想', 0, 'r']
整合每个词语的句法依存关系---->a = ['HED', '想', 1, 'v', 'Root', -2, 'u']
整合每个词语的句法依存关系---->a = ['VOB', '听', 2, 'v', '想', 0, 'r']
整合每个词语的句法依存关系---->a = ['ATT', '一', 3, 'm', '首', 3, 'm']
整合每个词语的句法依存关系---->a = ['ATT', '首', 4, 'q', '歌', 6, 'u']
整合每个词语的句法依存关系---->a = ['ATT', '迪哥', 5, 'nh', '歌', 6, 'u']
整合每个词语的句法依存关系---->a = ['RAD', '的', 6, 'u', '迪哥', 4, 'q']
整合每个词语的句法依存关系---->a = ['VOB', '歌', 7, 'n', '听', 1, 'v']
分词-->len(words) = 8----words = ['我', '想', '听', '一', '首', '迪哥', '的', '歌']
词性标注-->len(postags) = 8----postags = ['r', 'v', 'v', 'm', 'q', 'nh', 'u', 'n']
依存句法分析-->每个词对应的依存关系儿子节点和其关系-->len(child_dict_list) = 8----child_dict_list = [{}, {'SBV': [0], 'VOB': [2]}, {'VOB': [7]}, {}, {'ATT': [3]}, {'RAD': [6]}, {}, {'ATT': [4, 5]}]
依存句法分析--整合-->len(format_parse_list) = 8----format_parse_list = [['SBV', '我', 0, 'r', '想', 0, 'r'], ['HED', '想', 1, 'v', 'Root', -2, 'u'], ['VOB', '听', 2, 'v', '想', 0, 'r'], ['ATT', '一', 3, 'm', '首', 3, 'm'], ['ATT', '首', 4, 'q', '歌', 6, 'u'], ['ATT', '迪哥', 5, 'nh', '歌', 6, 'u'], ['RAD', '的', 6, 'u', '迪哥', 4, 'q'], ['VOB', '歌', 7, 'n', '听', 1, 'v']]
Process finished with exit code 0
参考资料:
一文读懂依存句法分析