【pandas】教程:6-如何计算摘要统计
Pandas 计算摘要统计
本节使用的数据为 data/titanic.csv,链接为 pandas案例和教程所使用的数据-机器学习文档类资源-CSDN文库
- 加载数据
import pandas as pd
titanic = pd.read_csv("data/titanic.csv")
titanic.head()
PassengerId Survived Pclass \
0 1 0 3
1 2 1 1
2 3 1 3
3 4 1 1
4 5 0 3
Name Sex Age SibSp \
0 Braund, Mr. Owen Harris male 22.0 1
1 Cumings, Mrs. John Bradley (Florence Briggs Th... female 38.0 1
2 Heikkinen, Miss. Laina female 26.0 0
3 Futrelle, Mrs. Jacques Heath (Lily May Peel) female 35.0 1
4 Allen, Mr. William Henry male 35.0 0
Parch Ticket Fare Cabin Embarked
0 0 A/5 21171 7.2500 NaN S
1 0 PC 17599 71.2833 C85 C
2 0 STON/O2. 3101282 7.9250 NaN S
3 0 113803 53.1000 C123 S
4 0 373450 8.0500 NaN S
- 求乘客的平均年龄
titanic["Age"].mean()
# output
# 29.69911764705882
不同的统计都可以应用于数值型列
- titanic 乘客年龄中位数和票价中位数
titanic[["Age", "Fare"]].median()
Age 28.0000
Fare 14.4542
dtype: float64
titanic[["Age", "Fare"]].describe()
Age Fare
count 714.000000 891.000000
mean 29.699118 32.204208
std 14.526497 49.693429
min 0.420000 0.000000
25% 20.125000 7.910400
50% 28.000000 14.454200
75% 38.000000 31.000000
max 80.000000 512.329200
DataFrame里的多列组成了DataFrame;
describe内置的信息统计函数;
除了自定义的统计函数,我们还可以聚合一些指定的统计方式,如下:
titanic.agg(
{
"Age": ["min", "max", "median", "skew"],
"Fare": ["min", "max", "median", "mean"],
}
)
Age Fare
min 0.420000 0.000000
max 80.000000 512.329200
median 28.000000 14.454200
skew 0.389108 NaN
mean NaN 32.204208
根据类别分组聚类统计数据

- Titanic 女性乘客和男性乘客的平均年龄?
titanic[['Sex', 'Age']].groupby("Sex").mean()
Age
Sex
female 27.915709
male 30.726645
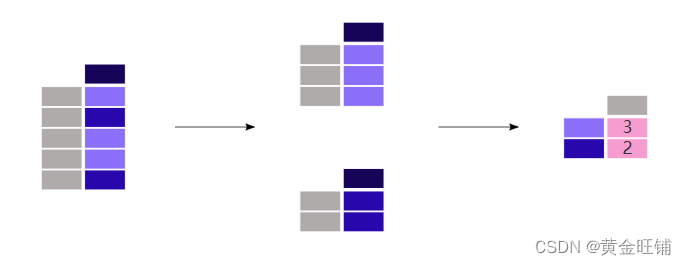
我们对男乘客和女乘客的平均年龄感兴趣,可以选择
Sex和Age这两列,然后用groupby()方法对每列进行聚类。解决这类问题的更通用的方式是split-apply-combine;
split数据成组- 对每个组单独
apply统计方法combine结合这些数据apply和combine在pandas里通常是一起做的。
上面的方法也可以写成如下:
titanic.groupby("Sex")["Age"].mean()
先对
Sex进行聚类分析,然后选择Age

- 每个不同性别和舱号的平均票价?
titanic.groupby(['Sex', 'Pclass'])['Fare'].mean()
Sex Pclass
female 1 106.125798
2 21.970121
3 16.118810
male 1 67.226127
2 19.741782
3 12.661633
Name: Fare, dtype: float64
groupby可以同时对多组数据同时进行;
类别计数
- 每个舱位人数分别是多少
titanic["Pclass"].value_counts()
3 491
1 216
2 184
Name: Pclass, dtype: int64
value_counts()方法会统计每个类别有多少。
size和count都可以结合groupby使用。size包含了NaN数据并且提供表数据的行数,而count排除了那些 缺失数据,在value_counts方法中,可以使用dropna来包含或者排除NaN数据。
记住
- 可以在整个列或行上计算聚合统计信息。
Groupby提供了拆分-应用-组合模式的功能。
value_counts是一个比较方便的统计函数,可以根据不同类别进行统计;
【参考】
How to calculate summary statistics? — pandas 1.5.2 documentation (pydata.org)