详解正则表达 + 万用达式
前言:
对于HTML对象的检索,我们可以使用正则表达、CSS选择器、Xpath、Beautiful Soup和PyQuery等解析库检索目标信息。正则表达的检索效率一般是比较慢的,但是正则表达式对部分相同节点的html文本进行检索效率较快。因为对于相同节点的部分html文本,无法从父节点和class节点来确定目标文本的位置,而正则表达式可以快速的检索出目标文本。
目录
正则表达式:
实例引入:
匹配规则:注释
✏示例:
正则使用方法:
1.match()方法
正则通用表达式:
贪婪表达式:
非贪婪表达式:
✨转义匹配:
✨修饰符:
2.search()方法
3.findall()方法
4.sub()方法
5.compile()方法
正则表达式:
正则表达式:又称规则表达式。(英语:Regular Expression,在代码中常简写为regex、regexp或RE),计算机科学的一个概念。正则表达式通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是处理字符串的强大工具,它有自己特定的语法结构,可以实现字符串的检索、替换、匹配验证。
实例引入:
这里提供两个测试正则表达的网站。
1.开源中国提供的正则表达式测试工具:在线正则表达式测试
2.正则表达在线测试:正则表达式在线测试 | 菜鸟工具
再这两个网站特别是第二个网站,可以找到众多常用便捷的正则表达式

我们先体验一下正则的用法。
我们打开 .开源中国提供的正则表达式测试工具:在线正则表达式测试
接着我们输入如下待匹配文本。
My chinese name is 李华 my url http://lihua.com. and email [email protected].
接着我们分别点击常用正则表达式选框中的,匹配中文字符、匹配网址url、匹配Email地址。我们可以在正则表达式框中看到用于匹配目标信息的正则表达式,在匹配结果框看到匹配的结果。
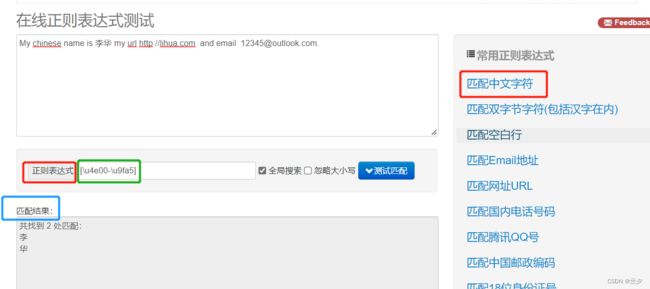


还没有学过正则表达式时,我们看上面的正则表达式就像一堆乱字符,毫无规律可言,但是恰恰相反,正则表达式的写法遵循着一定的规则。
下面我们进入正题。
匹配规则:注释
| 表达式 | 作用 |
| \d | 匹配任意数字,等价于[0-9] |
| \D | 匹配任意非数字字符 |
| \w | 匹配数字、字母、下划线 |
| \W | 匹配非数字、非字符、非下划线 |
| \s |
匹配任意空白字符,等价于[\t\n\r\f] |
| \S | 匹配任意非空字符 |
| \A | 匹配字符串开头 |
| \z | 匹配字符串结尾,如果存在换行符也会匹配到换行符 |
| \Z | 匹配字符串结尾,如果存在换行则只会匹配到换行前最后一个字符 |
| \n | 匹配一个换行符 |
| \t | 匹配一个制表符 |
| \G | 匹配最后匹配完成的位置 |
| ^ | 匹配一行字符串的开头 |
| $ | 匹配一行字符串的结尾 |
| . | 除换行符外,匹配任意字符当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符 |
| [...] | 表示一行字符,如[abc],表示匹配a,b,c |
| [^...] | 匹配不在[]中的字符,如[^abc]表示a,b,c外的字符 |
| + | 匹配一个或多个表达式 |
| * | 匹配0个或多个表达式 |
| ? | 匹配0个或1个前面的正则表达式定义的片段,非贪婪方式 |
| {n} | 精确匹配n个前面的表达式 |
| {n,m} | 匹配n到m次由前面正则表达式定义的片段,贪婪方式 |
| a|b | 匹配a或b |
| () | 匹配(取)括号内的表达式,也表示一个组 |
✏示例:
-----------------------------------------------------
| 字符 | 待匹配文本 | 表达式 | 匹配结果 |
| \d | 1c23 | \d | 123 |
| \D | 1c2中 | \D | c中 |
| \w | "c2中_? | \w | c2_ |
| \W | "c2中_? | \W | "中? |
| \s | "c 2 中_? | \s | (匹配到空格显示空格) |
| \S | "c 2 中_? | \S | "c2中_? |
| \A | "hello word" | \A(he) | he |
| \Z | "hello word" | \(rd)Z | rd |
| \z | "hello word" | \z | |
| \n | hello word |
\n | (匹配到换行符) |
| \t | hello word | \t | (匹配到制表符) |
| \G | hello word | \G | (匹配到空格) |
| ^ | hello word | ^h | h |
| $ | hello word | rd$ | rd |
| . | hello word | . | hello word |
| [...] | hello word | [hel] | hell |
| [^...] | hello word | [hel] | oword |
| + | hello word | [hel]+[0] | hello |
| * | hello word | \w*[o] | hellowo |
| ? | hello word | ? | (匹配到空格) |
| {n} | 123word | \d{2} | 12 |
| {n,m} | 1234word | \d{2,2} | 1234 |
| a|b | 123word | \d|[o] | 1234o |
| () | 123中wore | \d(\d) | 2 |
正则使用方法:
正则表达式可应用在多种编程语言中。其中就包含有Python的re库提供了整个正则表达式的实现,利用这个库,可以在Python中使用正则表达式。在Python中写正则表达式几乎都用这个库,下面就来了解它的一些常用方法。值得注意的是,有时候python的re库会在极少数情况会出现转译的报错,这时候可以使用import regex as re,导入正则表达库。
1.match()方法
使用match方法匹配字符的一般写法为
re.match('正则表达式', '要查找的文本对象')
match()方法会尝试从字符串的起始位置匹配正则表达式,如果匹配,就返回匹配成功的结果;如果不匹配,就返回
None。因为match()是从字符串起始位置匹配表达式,所以在正则表达式中一定要含有匹配字符串开头的表达式,如,^'字符串开头'.
下面我们使用match()方法来实际操作一下。
import re string = 'my phone number 123-4567-8899' result = re.match('^my\s\w{5}\s\w{6}\s(\d{3})-(\d{4})-(\d{4})', string) print(result) print(result.group()) print(result.group(1)) print(result.group(2)) print(result.group(3))输出:
my phone number 123-4567-8899
123
4567
8899-----------------------------------------------------------
解释说明:
re.Match object表示使用match匹配成功,span表示匹配范围,match表示匹配到的结果。
首先使用match()方法我们需要先写匹配开头的表达式(^Hello),接着用\s匹配第一个空格,用\w{5}匹配phone(5个字母),再次使用\s匹配第二个空格,使用\w{6}匹配number,有一次使用\s匹配空格,最后使用(\d{3})-(\d{4})-(\d{4})一次匹配123,4567,8899.
这里我们再说明()的用处,上面我们说到
()表示
这里的组就是group(),第一个括号(\d{3})表示group(1),第二个括号(\d{4})表示group(2),以此类推。group()没有参数时默认输出整个匹配到的字符。
匹配(取)括号内的表达式,也表示一个组
那么当我们使用match()方法匹配时,如果我们只想获取电话号码我们只需将三个括号合并成一个,然后输出,group(1)即可。
result = re.match('^my\s\w{5}\s\w{6}\s(\d{3}-\d{4}-\d{4})', string)
print(result)
print(result.group(1))
从上面的例子可以看到,正则常规的表达式是比较长且繁琐的,那么我们是不是每次都要写这样的表达式呢?
当然不是,我们一般都不会这么写正则表达式,我们最常用的是通用的正则表达式
正则通用表达式:
贪婪表达式:
其中一个通用万能公式就是贪婪表达式:.*
.(点)可以匹配任意字符(除换行符),*(星)代表匹配前面的字符0次或多次(组合起来就是匹配无限次),所以它们组合在一起就可以匹配任意字符了
我们仍以上面例题为例
使用贪婪表达式匹配
import re string = 'my phone number 123-4567-8899' result = re.match('^my.*(\d{3}-\d{4}-\d{4})', string) print(result) print(result.group()) print(result.group(1))输出:
可以看到我们使用.*就取代了\s\w{5}\s\w{6}\s这部分表达式,不用再为匹配其他字符写出繁琐的表达式。
那么既然.*可以匹配任意字符,那为什么表达式不写成^my.*(\d.*)?
如果写成这样的话我们看运行结果
import re string = 'my phone number 123-4567-8899' result = re.match('^my.*(\d.*)', string) print(result) print(result.group()) print(result.group(1))输出:
my phone number 123-4567-8899
9为什么没有输出完整的号码,这是因为.*是贪婪的通用匹配,.*会尽可能的匹配更多的在字符,所以第一次的.*会匹配到倒数第二个9的位子,因为要留出一位数字给\d,那么我们所.*匹配任意多字符也可以匹配0个字符,所以第二个.*匹配0个字符。
为了快速简洁匹配出完整的号码,我们引入非贪婪表达式。
非贪婪表达式:
非贪婪表达式:.*?
我们使用非贪婪表达式
import re string = 'my phone number 123-4567-8899' result = re.match('^my.*?(\d.*)', string) print(result) print(result.group()) print(result.group(1))输出:
my phone number 123-4567-8899
123-4567-8899可以看到使用非贪婪表达式后得到了正确结果,非贪婪表达式会尽可能少的匹配符合表达式的字符,所以.*?只会匹配my到1间的字符,1给\d匹配,剩下的就给.*?匹配。
所以贪婪和非贪婪正是对两种表达式特点的贴切描述。
✨转义匹配:
我们看到两个通用公式都说包含 . 符号的,那么如果在要匹配度文本中一定需要匹配 . 符号怎幺才不会和正则表达式的 . 符号混淆?
这就需要用到反斜杠来转义(python,和C语言字符串都有该转义的定义)。
import re string = """https://mp.csdn.net""" result = re.match('https://mp\.csdn\.net', string, re.S) print(result)输出:
✨修饰符:
我们给上面的例子加上一个换行符
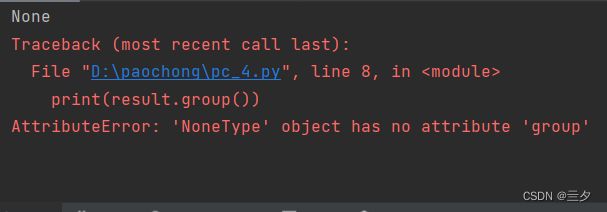
import re string = """my phone number 123-4567-8899""" result = re.match('^my.*?(\d.*)', string) print(result) print(result.group()) print(result.group(1))输出:
可以看到,因为没用匹配到任何符合要求的文本,在调用group()的情况下直接报错。这时因为两个通用表达式都无法匹配换行符,所以无法匹配内容。
那么我们可以加修饰符re.S解决这个问题。
import re string = """my phone number 123-4567-8899""" result = re.match('^my.*?(\d.*)', string, re.S) print(result) print(result.group()) print(result.group(1))输出:
my phone
number 123-4567-8899
123-4567-8899所以我们使用通用公式时尽量加上修饰符re.S
下面我们介绍各个修饰符的含义
re.S
使 . 匹配包含换行符在内的任意字符
re.I
使匹配对大小写不敏感
re.L
做本地化识别(locale-aware)匹配
re.M
多行匹配,影响^和
$re.U
根据Unicode字符集解析字符。这个标志影响
\w、\W、\b和\Bre.X
该标志通过给予你更灵活的格式以便你将正则表达式写得更易于理解
接着我们介绍其他查找方法
2.search()方法
由于match()方法在写正则表达式时总是需要匹配开头,一旦开头不匹配那么就会匹配失败,这样我们写正则表达式就有了限制,不够灵活。
那么我们可以使用search()方法,search()在匹配时会扫描整个字符串,然后返回第一个成功匹配的结果。也就是说,我们写的正则表达不用写出匹配开头的语句,正则表达式可以是字符串的一部分,在匹配时,
search()方法会依次扫描字符串,直到找到第一个符合规则的字符串,然后返回匹配内容,如果搜索完了还没有找到,就返回None。
以下面的本部分html文本为例。
html = “
更新至第2话6647万
669.1万
假设我们要爬取6647万
import re
html = """
更新至第2话
6647万
669.1万
输出:
(.*?)', html, re.S) print(result)
输出:
['\n 6647万\n ', '\n 669.1万\n ']
正则很贴心,因为我们要匹配的是多个内容,所以findall()方法匹配到的内容是以列表的形式输出的,便于我们观察和遍历。
值得注意的是:因为findall()方法匹配到的内容是以列表的形式输出所以findall()方法没有group(),使用group()方法会出错。
4.sub()方法
除了使用正则表达式提取信息外,有时候还需要借助它来修改文本。(repla()也有修改文本的功能,不过对于大量同类的修改sub()方法更佳)
sub()方法一般写法:sub('正则表达式', '要替换成的字符', 要修改的文本)
比如我们想去除字母中混有的数字
import re string = "hello12wo34r0d" result = re.sub('\d.*?', '', string) print(result)输出:
helloword
将数字换成问号
import re string = "hello12wo34r0d" result = re.sub('\d.*?', '?', string) print(result)输出:
hello??wo??r?d
5.compile()方法
compile方法可以将正则字符串编译成正则表达式对象,以便在后面的匹配中复用。
compile()方法一般写法:re.compile('正则表达式')
如我们将hello删除
import re string1 = "hello sun" string2 = "hello moon" text = re.compile('\w{5}') result1 = re.sub(text, '', string1) result2 = re.sub(text, '', string2) print(result1) print(result2)输出:
sun
moon
这样我们就没有必要重复写3个同样的正则表达式,此时可以借助compile()方法将正则表达式编译成一个正则表达式对象,以便复用。另外,
compile()还可以传入修饰符,例如re.S等修饰符,这样在search()、findall()等方法中就不需要额外传了。所以,compile()方法可以说是给正则表达式做了一层封装,以便我们更好地复用。
参考:
python爬虫2
开源中国提供的正则表达式测试工具
正则表达在线测试
今天就到这,明天见。
❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄end❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄