Faster RCNN网络源码解读(Ⅴ) --- GeneralizedRCNNTransform图像初始化代码解析
目录
一、代码作用(transform.py)
编辑
二、代码解析
2.1 GeneralizedRCNNTransform类
2.1.1 初始化函数__init__
2.1.2 normalize标准化处理
2.1.3 将图像以及bndbox进行缩放resize
2.1.4 batch_images
2.1.5 正向传播 forward
2.1.6 后处理模块postprocess
三、ImageList类
一、代码作用(transform.py)
前面我们已经说过怎样生成自定义数据集的部分了,我们通过自定义数据集会生成图像信息以及对应的标注信息,在这部分我们会对图像进行标准化处理以及对bndbox信息进行一个resize处理把他打包成batch放入网络中进行正向传播。
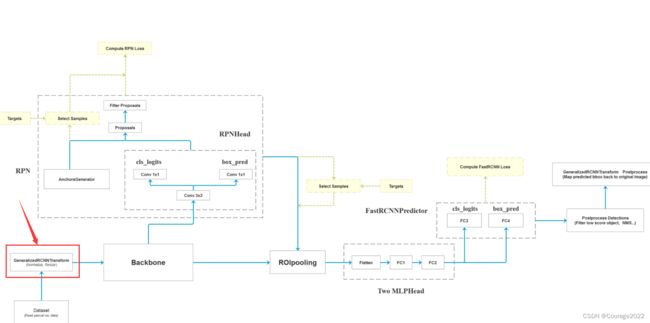
二、代码解析
2.1 GeneralizedRCNNTransform类
2.1.1 初始化函数__init__
#定义了输入进网络的最小边长,最大边长,均值,方差 def __init__(self, min_size, max_size, image_mean, image_std): super(GeneralizedRCNNTransform, self).__init__() #如果min_size是不是list或者tuple类型 if not isinstance(min_size, (list, tuple)): min_size = (min_size,) self.min_size = min_size # 指定图像的最小边长范围 self.max_size = max_size # 指定图像的最大边长范围 self.image_mean = image_mean # 指定图像在标准化处理中的均值 self.image_std = image_std # 指定图像在标准化处理中的方差定义了输入进网络的最小边长,最大边长,均值,方差。
即对于每张图片我们要给他缩放到最小值min_size和最大值max_size之间。还要将图像进行标准化处理,其均值和方差为传入参数。
2.1.2 normalize标准化处理
def normalize(self, image): """标准化处理""" dtype, device = image.dtype, image.device #将均值方差转换成pytorch的tensor格式 #mean传进来是个list,其中有三个元素,我们转换成tensor应该是 # [:, None, None]: shape [3] -> [3, 1, 1]种形式 mean = torch.as_tensor(self.image_mean, dtype=dtype, device=device) std = torch.as_tensor(self.image_std, dtype=dtype, device=device) # [:, None, None]: shape [3] -> [3, 1, 1] return (image - mean[:, None, None]) / std[:, None, None]
2.1.3 将图像以及bndbox进行缩放resize
def resize(self, image, target): # type: (Tensor, Optional[Dict[str, Tensor]]) -> Tuple[Tensor, Optional[Dict[str, Tensor]]] """ 将图片缩放到指定的大小范围内,并对应缩放bboxes信息 Args: image: 输入的图片 target: 输入图片的相关信息(包括bboxes信息) Returns: image: 缩放后的图片 target: 缩放bboxes后的图片相关信息 """ # image shape is [channel, height, width] #获取图像的高度,宽度信息 h, w = image.shape[-2:] if self.training: #如果在训练模式,取得我们传入的参数,即图像最小边长 size = float(self.torch_choice(self.min_size)) # 指定输入图片的最小边长,注意是self.min_size不是min_size else: # FIXME assume for now that testing uses the largest scale size = float(self.min_size[-1]) # 指定输入图片的最小边长,注意是self.min_size不是min_size if torchvision._is_tracing(): image = _resize_image_onnx(image, size, float(self.max_size)) else: #传入参数:最小尺度、最大尺度 image = _resize_image(image, size, float(self.max_size)) if target is None: return image, target #取出box信息 bbox = target["boxes"] # 根据图像的缩放比例来缩放bbox,参数为标注框,原来的图像尺寸,经过缩放后的图像尺寸 bbox = resize_boxes(bbox, [h, w], image.shape[-2:]) target["boxes"] = bbox return image, target首先获取图像的宽度和高度信息h, w。
将图像高度宽度信息转化成tensor信息,如果在训练模式,取得我们传入的参数,即图像最小边长size。将最小边长size和最大边长self.max_size输入到_resize_image函数对图像进行缩放。
def _resize_image(image, self_min_size, self_max_size): #比如一张图片我们是10*20 我们想让他控制在5*5间 #我们用 5/10 得到缩放因子0.5 0.5*20大于5 不行 #我们用 5/20 得到缩放因子0.25 0.25*20=5可以 # type: (Tensor, float, float) -> Tensor im_shape = torch.tensor(image.shape[-2:]) min_size = float(torch.min(im_shape)) # 获取高宽中的最小值 max_size = float(torch.max(im_shape)) # 获取高宽中的最大值 scale_factor = self_min_size / min_size # 根据指定最小边长和图片最小边长计算缩放比例 # 如果使用该缩放比例计算的图片最大边长大于指定的最大边长 if max_size * scale_factor > self_max_size: scale_factor = self_max_size / max_size # 将缩放比例设为指定最大边长和图片最大边长之比 # interpolate利用插值的方法缩放图片 # image[None]操作是在最前面添加batch维度[C, H, W] -> [1, C, H, W] # bilinear双线性插值只支持4D Tensor image = torch.nn.functional.interpolate( image[None], scale_factor=scale_factor, mode="bilinear", recompute_scale_factor=True, align_corners=False)[0] return image比如一张图片我们是10*20 我们想让他控制在5*5间,我们用 5/10 得到缩放因子0.5 0.5*20大于5 不行,我们用 5/20 得到缩放因子0.25 0.25*20=5可以。
经过此函数之后,我们的图像以及缩放到了初始化函数的最小图像大小到最大图像大小之间了。
随后我们取出bbox信息对标注图像框进行等比例缩放。
def resize_boxes(boxes, original_size, new_size): # type: (Tensor, List[int], List[int]) -> Tensor """ 将boxes参数根据图像的缩放情况进行相应缩放 Arguments: original_size: 图像缩放前的尺寸 new_size: 图像缩放后的尺寸 """ #将原来图片的尺寸和现在图片的尺寸转换为tensor格式 ratios = [ torch.tensor(s, dtype=torch.float32, device=boxes.device) / torch.tensor(s_orig, dtype=torch.float32, device=boxes.device) for s, s_orig in zip(new_size, original_size) ] ratios_height, ratios_width = ratios # Removes a tensor dimension, boxes [minibatch, 4] # Returns a tuple of all slices along a given dimension, already without it. #将边界框按索引值为1的方向展开 # [minibatch, 4] 当前图片有几个box信息 他们的坐标 xmin, ymin, xmax, ymax = boxes.unbind(1) xmin = xmin * ratios_width xmax = xmax * ratios_width ymin = ymin * ratios_height ymax = ymax * ratios_height return torch.stack((xmin, ymin, xmax, ymax), dim=1)经过resize函数后,我们将图片大小限制在了(min_size, max_size)之间,并且完成了对bndbox的缩放。
2.1.4 batch_images
将图像打包成一个batch输入到一个网络中,我们经过标准化处理和resize之后我们的图像大小并不是标准的大小每张图片都不一样的,我们要Resize。
我们经过resize函数后的图像并不是统一尺寸的图像,我们要通过这个函数进行图像打包处理(即让图片处于同一尺寸中)。
def batch_images(self, images, size_divisible=32): # type: (List[Tensor], int) -> Tensor """ 将一批图像打包成一个batch返回(注意batch中每个tensor的shape是相同的) Args: images: 输入的一批图片 size_divisible: 将图像高和宽调整到该数的整数倍 Returns: batched_imgs: 打包成一个batch后的tensor数据 """ #不会执行的 if torchvision._is_tracing(): # batch_images() does not export well to ONNX # call _onnx_batch_images() instead return self._onnx_batch_images(images, size_divisible) # 分别计算一个batch中所有图片中的最大channel, height, width,输出的是一个batch图片的最大高度、最大宽度和最大通道数 max_size = self.max_by_axis([list(img.shape) for img in images]) #传入的参数size_divisible=32 这样会使我们的长度宽度取整到离32最大的尺寸 stride = float(size_divisible) # max_size = list(max_size) # 将height向上调整到stride的整数倍 max_size[1] = int(math.ceil(float(max_size[1]) / stride) * stride) # 将width向上调整到stride的整数倍 max_size[2] = int(math.ceil(float(max_size[2]) / stride) * stride) # [batch, channel, height, width] #len(images)是图片个数 batch_shape = [len(images)] + max_size # 创建shape为batch_shape且值全部为0的tensor,tensor的 batched_imgs = images[0].new_full(batch_shape, 0) for img, pad_img in zip(images, batched_imgs): # 将输入images中的每张图片复制到新的batched_imgs的每张图片中,对齐左上角,保证bboxes的坐标不变 # 这样保证输入到网络中一个batch的每张图片的shape相同 # copy_: Copies the elements from src into self tensor and returns self #通道数目 长 宽 pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img) return batched_imgs这里的思想是假如我们要将八张图片打包成一个batch,首先获取这八张图片宽的最大值和宽的最大值,假设图中蓝色的矩阵,全部用0来填充。紧接着把每张图片的左上角与蓝色矩形框的左上角进行对齐。达到了输入图片都是同一size,这保持了图像的正常比例。
size_divisible=32这个参数的含义是将尺寸全部向上取整到32的整数倍方便系统进行优化。
batch_shape = [len(images)] + max_size
上局代码中,max_size是三维的,存储的一个batch图片的最大通道数,最大长度以及最大宽度, [len(images)]对应着图片的个数即batch的个数,这样构建了四维向量,[batch, channel, height, width]。
创建shape为batch_shape且值全部为0的tensor batched_imgs。
batched_imgs = images[0].new_full(batch_shape, 0)batched_imgs最终存储着尺寸大小相同的image。

2.1.5 正向传播 forward
def forward(self, images, # type: List[Tensor] targets=None # type: Optional[List[Dict[str, Tensor]]] ): # type: (...) -> Tuple[ImageList, Optional[List[Dict[str, Tensor]]]] images = [img for img in images] #遍历图像列表获取每张图片 for i in range(len(images)): image = images[i] #判断target是否为空,若不为空,则将索引为i的target赋值给target_index target_index = targets[i] if targets is not None else None if image.dim() != 3: raise ValueError("images is expected to be a list of 3d tensors " "of shape [C, H, W], got {}".format(image.shape)) #标准化处理, 对图像和对应的bboxes缩放到指定范围 image = self.normalize(image) #resize处理 image, target_index = self.resize(image, target_index) #替换图像 images[i] = image if targets is not None and target_index is not None: targets[i] = target_index # 记录resize后的图像尺寸 # 这时debug,每张图片的大小不一样 image_sizes = [img.shape[-2:] for img in images] # 将images打包成一个batch(8*3*1216*1088)数量 通道 长宽 images = self.batch_images(images) #是个list 每个元素都是一个(int int)的tuple,记录resize之后的尺寸 image_sizes_list = torch.jit.annotate(List[Tuple[int, int]], []) for image_size in image_sizes: assert len(image_size) == 2 image_sizes_list.append((image_size[0], image_size[1])) image_list = ImageList(images, image_sizes_list) return image_list, targets输入的参数是未经初始化的图片image以及标注信息target。
将所有图片存放在images列表中。
遍历所有图片,将遍历到的图片放到image变量中,判断这个图片的target信息是否为空,若为空target_index的值赋予为none否则赋予target_index的值为该张图片的标注信息。
检查完图像合理化后:
①对图像进行标准化处理image = self.normalize(image)
②对图像进行resize处理 image, target_index = self.resize(image, target_index)
③替换图像
images[i] = image if targets is not None and target_index is not None: targets[i] = target_index④记录resize之后的图像尺寸
image_sizes = [img.shape[-2:] for img in images]
这里每张图片的大小是不一样的。
⑤将images打包成一个batch(8*3*1216*1088)数量 通道 长宽
images = self.batch_images(images)
⑥定义了一个image_sizes_list,它是一个list,每个元素是一个(int,int)的tuple,记录resize之后batch之前的尺寸。
我们来缕清一下思路:
输入到本类之前的图像是大小不一的,我们经过resize函数将图像进行缩放到了一定范围内,最后经过batch处理将图片处理到统一尺寸,由于resize之后进行预测的边界框信息是resize之后的,但是我们绘制我们的预测结果时其实要在原图上进行绘制。
image_list 含两个尺寸信息,返回给调用函数。image_list和target数据即即将输入backbone中的数据。


2.1.6 后处理模块postprocess
#对网络的预测结果进行后处理(主要将bboxes还原到原图像尺度上) #result : 是网络的最终预测结果 包括bndbox信息及每个bndbox对应的位置信息,标签值以及对应的概率 #image_shapes :将图像经过resize之后的每一个图像的高度和宽度 #original_image_sizes :每张图片在缩放前的高度和宽度 def postprocess(self, result, # type: List[Dict[str, Tensor]] image_shapes, # type: List[Tuple[int, int]] original_image_sizes # type: List[Tuple[int, int]] ): # type: (...) -> List[Dict[str, Tensor]] """ 对网络的预测结果进行后处理(主要将bboxes还原到原图像尺度上) Args: result: list(dict), 网络的预测结果, len(result) == batch_size image_shapes: list(torch.Size), 图像预处理缩放后的尺寸, len(image_shapes) == batch_size original_image_sizes: list(torch.Size), 图像的原始尺寸, len(original_image_sizes) == batch_size Returns: """ if self.training: return result #i是对应的索引,(pred, im_s, o_im_s)对应result, image_shapes, original_image_sizes # 遍历每张图片的预测信息,将boxes信息还原回原尺度 # im_s 缩放后的图像尺度 o_im_s图像原始尺度 for i, (pred, im_s, o_im_s) in enumerate(zip(result, image_shapes, original_image_sizes)): boxes = pred["boxes"] boxes = resize_boxes(boxes, im_s, o_im_s) # 将bboxes缩放回原图像尺度上 result[i]["boxes"] = boxes return result
三、ImageList类
from typing import List, Tuple from torch import Tensor class ImageList(object): """ Structure that holds a list of images (of possibly varying sizes) as a single tensor. This works by padding the images to the same size, and storing in a field the original sizes of each image """ def __init__(self, tensors, image_sizes): # type: (Tensor, List[Tuple[int, int]]) -> None """ Arguments: tensors (tensor) padding后的图像数据 image_sizes (list[tuple[int, int]]) padding前的图像尺寸 """ self.tensors = tensors self.image_sizes = image_sizes def to(self, device): # type: (Device) -> ImageList # noqa cast_tensor = self.tensors.to(device) return ImageList(cast_tensor, self.image_sizes)输入参数tensor :batch处理后的图像。
输入参数image_sizes :与batch处理前的尺寸,这里每张图片大小不一样。