DQN及其变种(DDQN,Dueling DQN,优先回放)代码实现及结果
DQN及其变种理论部分见DQN及其变种(Double DQN,优先回放,Dueling DQN)
(一)DQN
导入包和环境
import math, random
import gym
import numpy as np
import torch
import torch.nn as nn
import torch.optim as optim
from IPython.display import clear_output
import matplotlib.pyplot as plt
from collections import deque
env = gym.make("CartPole-v1").unwrapped
绘图模块
def plot(frame_idx, rewards, losses):
clear_output(True)
plt.figure(figsize=(20,5))
plt.subplot(131)
plt.title('episode %s. reward: %s' % (frame_idx, np.mean(rewards[-10:])))
plt.plot(rewards)
plt.subplot(132)
plt.title('loss')
plt.plot(losses)
plt.show()
经验回放池
class ReplayBuffer(object):
def __init__(self, capacity):
self.buffer = deque(maxlen=capacity)
def push(self, state, action, reward, next_state, done):
state = np.expand_dims(state, 0)
next_state = np.expand_dims(next_state, 0)
self.buffer.append((state, action, reward, next_state, done))
def sample(self, batch_size):
state, action, reward, next_state, done = zip(*random.sample(self.buffer, batch_size))
return np.concatenate(state), action, reward, np.concatenate(next_state), done
def __len__(self):
return len(self.buffer)
replay_buffer = ReplayBuffer(1000)
神经网络
class NetWork(nn.Module):
def __init__(self, num_inputs, num_outputs):
super(NetWork, self).__init__()
self.layers = nn.Sequential(
nn.Linear(num_inputs, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, num_outputs))
def forward(self, x):
return self.layers(x)
DQN智能体:自定义属性,选择动作,学习参数优化
class DQN(object):
def __init__(self):
self.policy_model = NetWork(env.observation_space.shape[0], env.action_space.n)
self.target_model = NetWork(env.observation_space.shape[0], env.action_space.n)
self.optimizer = optim.Adam(self.policy_model.parameters())
self.loss_func = nn.MSELoss()
def action(self,state,step):
epsilon_start = 1.0
epsilon_final = 0.01
epsilon_decay = 500
epsilon = epsilon_final + (epsilon_start - epsilon_final) * math.exp(-1. * step / epsilon_decay)
if random.random() > epsilon:
state = torch.FloatTensor(state).unsqueeze(0)
q_value = self.policy_model.forward(state)
action = q_value.max(1)[1].item()
else:
action = random.randrange(env.action_space.n)
return action
def learn(self,replay_buffer,batch_size,step):
if step % 100 == 0:
self.target_model.load_state_dict(self.policy_model.state_dict())
state, action, reward, next_state, done = replay_buffer.sample(batch_size)
state = torch.FloatTensor(np.float32(state))
next_state = torch.FloatTensor(np.float32(next_state))
action = torch.LongTensor(action)
reward = torch.FloatTensor(reward)
done = torch.FloatTensor(done)
policy_q_values = self.policy_model(state).gather(1, action.unsqueeze(1)).squeeze(1)
target_q_values = self.target_model(next_state).max(1)[0].detach()
expected_q_value = reward + gamma * target_q_values * (1 - done)
loss = self.loss_func(policy_q_values,expected_q_value)
self.optimizer.zero_grad()
loss.backward()
self.optimizer.step()
return loss
DQN=DQN()
主循环
num_frames = 10000
batch_size = 128
gamma = 0.99
total_loss = []
total_reward = []
episode_reward = 0
state = env.reset()
for index in range(1, num_frames + 1):
action = DQN.action(state,index)
next_state, reward, done, _ = env.step(action)
replay_buffer.push(state, action, reward, next_state, done)
state = next_state
episode_reward += reward
if done:
state = env.reset()
total_reward.append(episode_reward)
episode_reward = 0
if len(replay_buffer) > batch_size:
loss = DQN.learn(replay_buffer,batch_size,index)
total_loss.append(loss.item())
if index % 200 == 0:
plot(index, total_reward, total_loss)
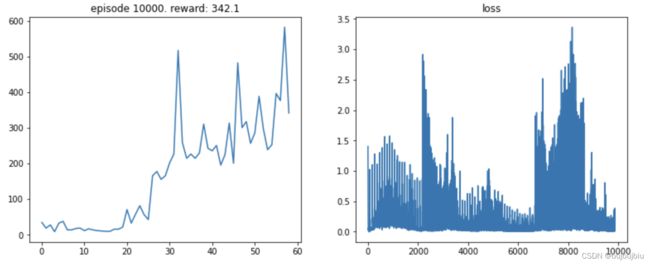
结果

(二)DDQN
DDQN与DQN差别在于更新目标网络q值
DQN代码如下:
policy_q_values = self.policy_model(state).gather(1, action.unsqueeze(1)).squeeze(1)
target_q_values = self.target_model(next_state).max(1)[0].detach()
DDQN代码如下:
policy_q_values = self.policy_model(state).gather(1, action.unsqueeze(1)).squeeze(1)
max_action = self.policy_model(next_state).max(1)[1]
target_q_values = self.target_model(next_state).gather(1, max_action.unsqueeze(1)).squeeze(1)
其它部分代码相同,结果如下

(三)Dueling DQN
Dueling DQN与DQN相比只有神经网络部分不同
DQN网络如下:
class NetWork(nn.Module):
def __init__(self, num_inputs, num_outputs):
super(NetWork, self).__init__()
self.layers = nn.Sequential(
nn.Linear(num_inputs, 128),
nn.ReLU(),
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, num_outputs))
def forward(self, x):
return self.layers(x)
Dueling DQN网络如下
class NetWork(nn.Module):
def __init__(self, num_inputs, num_outputs):
super(NetWork, self).__init__()
self.feature = nn.Sequential(
nn.Linear(num_inputs, 128),
nn.ReLU())
self.advantage = nn.Sequential(
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, num_outputs))
self.value = nn.Sequential(
nn.Linear(128, 128),
nn.ReLU(),
nn.Linear(128, 1))
def forward(self, x):
x = self.feature(x)
advantage = self.advantage(x)
value = self.value(x)
return value + advantage - advantage.mean()
其它部分相同,结果如下:
(四)优先回放
待更新