深度学习模型CV-Transformer(一)
Attention注意力机制与self-attention自注意力机制
参考文章:
https://zhuanlan.zhihu.com/p/265108616
https://zhuanlan.zhihu.com/p/96492170
概述
Attention注意力
Attention注意力用我们比较好理解的说法就是:输入进来一行序列(一句话),我们总能从这句话中找到并聚焦到重要的信息上,而忽略大多不重要的信息。权重越大,就越聚焦关注其权重对应的value的值上,权重代表信息的重要程度,Value则是其对应的信息。
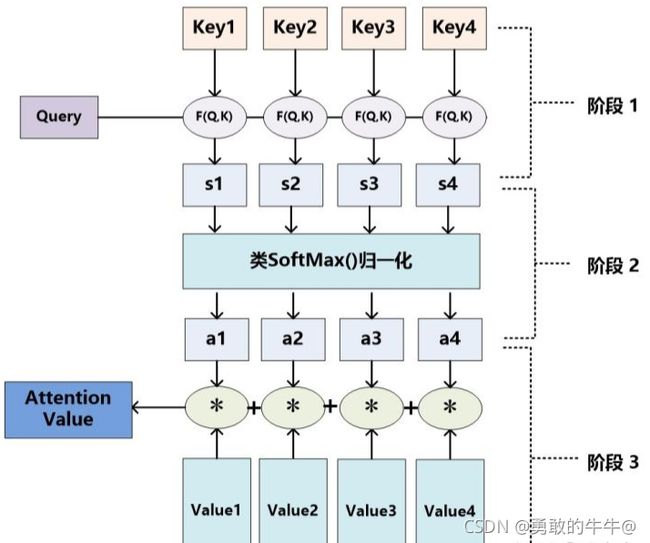
Attention机制的具体计算过程,可以将其归纳为两个过程:第一个过程是根据 Q u e r y Query Query和 K e y Key Key计算权重系数,第二个过程根据权重系数对 V a l u e Value Value进行加权求和。而第一个过程又可以细分为两个阶段:第一个阶段根据 Q u e r y Query Query和 K e y Key Key计算两者的相似性或者相关性---->第二个阶段对第一阶段的原始分值进行归一化处理。这样,可以将Attention的计算过程抽象为如图展示的三个阶段。
------->阶段1: Q u e r y Query Query和 K e y Key Key计算两者的相似性或者相关性
------>阶段2:对第一阶段的原始分值进行归一化处理
------>阶段3:根据权重系数对 V a l u e Value Value进行加权求和
到这里其实对其中的Q、K、V还是模棱两可,不知道所以然,这篇文章写的非常棒,可以初步对Q、K、V有重新的认识:https://zhuanlan.zhihu.com/p/96492170
看了这篇文章,下面是自己的理解(参考偏多,原文非常得棒):
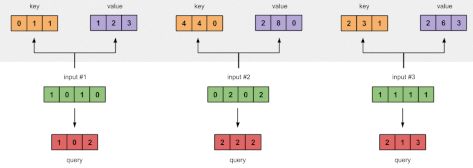
图中:绿色模块为输入信息,红色模块为–>查询(Query),橙色模块为–>键(Key),紫色模块为–>值(Value)
1.准备输入
2.初始化权重
3.推导:键(Key)、查询(Query)和值(Value)
4.计算输入 1 的注意力分数
5.计算 softmax得分
6.将分数与值相乘
7.对加权的值求和得到输入1的对应输出1
8.为输入 2 和 3 重复 4-7 步骤
对于输入,不论是语音,文本,还是图片,都要经过计算机的处理变成计算机可以识别的语言,从上面的文章中,总结得到:在神经网络设置中,这些权重通常是较小的数值,初始化也是使用合适的随机分布来实现,比如高斯分布、Xavier 分布、Kaiming 分布。
- 可以认为对于一个输入信息的Key(K:键)是经过输入信息与键的权重做矩阵的点积得来。
- Query(Q:查询)是经过输入信息与查询的权重做矩阵的点积得来。
- Value(V:值)是经过输入信息与值的权重做矩阵的点积得来。
对于多个输入,要分别与三组权重,分别生成多个输入信息相对的 Q 、 K 、 V Q、K、V Q、K、V,也就是不管有多少输入,每个输入都有自己专属的 Q 、 K 、 V Q、K、V Q、K、V。
此时输入信息都有了自己专属的表示信息( Q 、 K 、 V Q、K、V Q、K、V)。接下来该计算每个输入信息的注意力分数:输入1的Q与所有输入K组成的矩阵做点积,就得到了针对输入1的所有其他输入的分数(其实就是一个数值),如下图所示
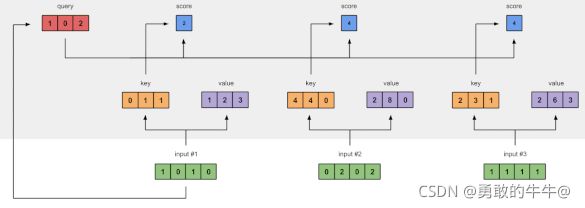
[ 1 0 2 ] × [ 0 4 2 1 4 3 1 0 1 ] = [ 2 4 4 ] \left[\begin{array}{ccc} 1 & 0 & 2\end{array}\right]\times\left[\begin{matrix}0 & 4 & 2 \cr 1 & 4 &3\cr 1 & 0 &1\end{matrix}\right] = \left[\begin{array}{ccc} 2 & 4 & 4\end{array}\right] [102]×⎣⎡011440231⎦⎤=[244]
有了每个输入只针对输入1的得分,将这些分数经过 S o f t m a x Softmax Softmax,会得到针对这些得分的一个矩阵,矩阵内参数和为1。比如对于上面图例输入1查询(Q)的得分为[2, 4, 4],softmax([2, 4, 4]) = [0.2, 0.4, 0.4],得到这个分数后,每个位置(输入)的分数分别与输入的值(K)相乘,也就是:
0.2 × 输 入 1 的 K = K 1 − − > 0.4 × 输 入 2 的 K = K 2 − − > 0.4 × 输 入 3 的 K = K 3 0.2\times输入1的K = K_1-->0.4\times输入2的K = K_2-->0.4\times输入3的K = K_3 0.2×输入1的K=K1−−>0.4×输入2的K=K2−−>0.4×输入3的K=K3
该过程叫做加权,得到的是加权值,然后把 K 1 + K 2 + K 3 K_1+K_2+K_3 K1+K2+K3三个加权值相加得到的就是针对于输入1的自注意力值。
如果有多个输入,依次按着同样的顺序计算对于每个输入的输出。
(在文章中表明不单单只有矩阵做点积的一种运算方式,当然了这里的三种权重初始化也是遵循某种规则随机生成的)
Self-attention自注意力机制
实际上,在处理图像问题时,每一个像素点都可以看成一个三维的向量,维度就是图像的通道数,所以图像也可以看成是很多向量输入的模型,自注意力机制和CNN的概念类似,都是希望网络不仅仅考虑某一个向量,也就是CNN中希望模型不仅仅考虑某一个像素点,而是让模型考虑一个正方形或者矩形的感受野(Receptive field),对于自注意力机制来说,相当于模型自己决定receptive field是怎样的形状和类型。
自注意力机制的计算过程如下:
1.将输入单词转化成嵌入向量(可以理解为矩阵)
2.根据嵌入向量得到 Q 、 K 、 V Q、K、V Q、K、V三个向量
3.为每个向量计算一个 s c o r e : s c o r e = Q ∗ ( a l l ) K score:score = Q*(all)K score:score=Q∗(all)K(*是矩阵乘法,点积;all(K)如上注意力机制同理)
3---->另一种说法:Self-Attention模块要计算任意两个词之间的相容度(compatibility,也称为attention score)
4.为了梯度的稳定,Transformer使用了score归一化,即除以 d K \sqrt{dK} dK
5.对score施以softmax激活函数
6.softmax乘Value值V,得到加权的每个输入向量的评分 V i V_i Vi
7.相加之后得到最终的输出结果z : Z = ∑ i = 0 n V i Z = \sum_{i=0}^{n}{V_i} Z=∑i=0nVi
从整体的计算过程来看,和注意力机制的算法过程大同小异,只不过是在为了梯度的稳定,做了除法。
亮点
相比于 CNN、RNN ,其复杂度更小,参数也更少。所以对算力的要求也就更小。
Attention 解决了 RNN及其变体模型不能并行计算的问题。Attention机制每一步计算不依赖于上一步的计算结果,因此可以和CNN一样并行处理。
BoTNet
参考文章:https://blog.csdn.net/wuli_xin/article/details/119950636
概述:
亮点:
引入了比较流行的 T r a n s F o r m e r s TransFormers TransFormers结构,算是比较大的创新
模型结构:
论文地址:https://arxiv.org/abs/2101.11605
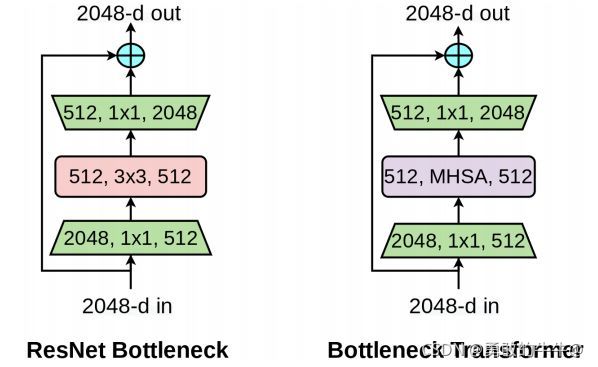
左图是resnet提出的经典残差模块,右图是引入 ( M u l t i − H e a d S e l f − A t t e n t i o n , M H S A ) (Multi-Head Self-Attention, MHSA) (Multi−HeadSelf−Attention,MHSA)的残差模块,称作 B o T BoT BoT。
从上图中观察,唯一的不同就是MHSA单元替换了 3 × 3 3\times3 3×3卷积单元,但是在目标检测,分类任务精度上面有很大的提升。
如果是改进网络的话,为了发小论文,这个改进可以试着改进一下,具体在看效果。
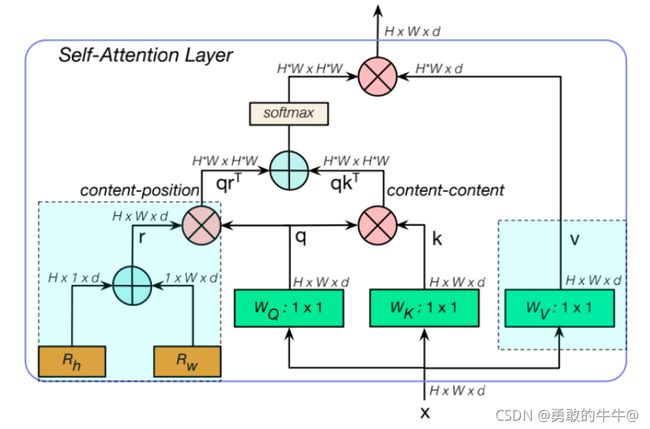
MHSA包含了位置的attention和内容的attention
在 B o T BoT BoT模块中使用的多头自注意力 M H S A MHSA MHSA层,其中 q , k , v , r q,k,v,r q,k,v,r指的是查询、键、值和位置编码, R h R_h Rh和 R w R_w Rw指的是高度和宽度的相对位置编码。
位置编码参考文章:https://zhuanlan.zhihu.com/p/354963727
位置编码很疑惑
通过论文中描述: W q , W k , W v W_q,W_k,W_v Wq,Wk,Wv都是 1 × 1 1\times1 1×1的逐点卷积,进而得到 q , k , v q,k,v q,k,v
与Transformer中的MHSA有所区别的是,MHSA在position部分 使用两个向量当做横纵两个纬度的空间注意力,相加之后,与q相乘得到content-position,再将content-position和content-content相乘得到空间敏感的相似性feature,从而让MHSA关注合适区域,更加容易收敛。
BoTNet要替换ResNet中的3*3的卷积部分代码:
参考文章:https://blog.csdn.net/PaddlePaddle/article/details/120051989
与BoTNet提出的模块思路相似的论文,还有CoTNet
论文地址:https://arxiv.org/abs/2107.12292
同样在ResNet的残差模块中,直接采用COT单元替换残差模块的 3 × 3 3\times3 3×3卷积,这块的思路和BoT单元采取的方法一致。将Transformer中的自注意力机制的动态上下文信息聚合与卷积的静态上下文信息聚合进行了集成,提出了一种新颖的Transformer风格的“即插即用”CoT模块。 C o T CoT CoT单元和 B o T BoT BoT单元都可以称为即插即用的单元,看到这里,如果这两个单元真的如论文中所说,对检测任务和分类任务都有精度的提升,可以尝试把这两个单元加在其他的检测模型中,比如yolo系列等其他的。按道理来说,保证特征图的尺寸和输入输出通道数与前后的输出输入一致,就可以验证是不是真的可以适用于其他的模型。—>作为一个晓得tricks被发现(有待验证2021.10.28)
解决的问题:
可以提升精度,而没有很大程度影响速度
———————————————————————————————————————————————————————————
———————————————————————————————————————————————————————————
COTNet
参考文章:
https://zhuanlan.zhihu.com/p/398074144
https://zhuanlan.zhihu.com/p/394539550
概述
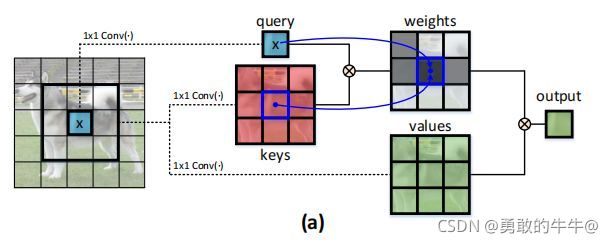
- 大多数现有的Transformer直接在二维特征图上的进行Self-Attention,基于每个空间位置的query和key获得注意力矩阵,但相邻的key之间的上下文信息未得到充分利用。本文设计了一种新的注意力结构CoT Block,这种结构充分利用了key的上下文信息,以指导动态注意力矩阵的学习,从而增强了视觉表示的能力。如上图所示

- CoT 首先通过 3 × 3 卷积对输入键进行上下文编码,从而产生输入的静态上下文表示。进一步地,我们将经过编码的键与输入查询连接起来,通过两个连续的 1×1 卷积学习动态多头注意力矩阵。最后,学习到的注意力矩阵乘以输入值以实现输入的动态上下文表示,并且融合静态和动态上下文表示作为最终输出。(简单的说,就是作者先用卷积来提取了局部了信息,从而充分发掘了key内部的静态上下文信息 )如上图所示
下图是Multi-head Self-attention模块
(内容全部是复制,然后有一点自己的理解,来源于:https://zhuanlan.zhihu.com/p/394539550)
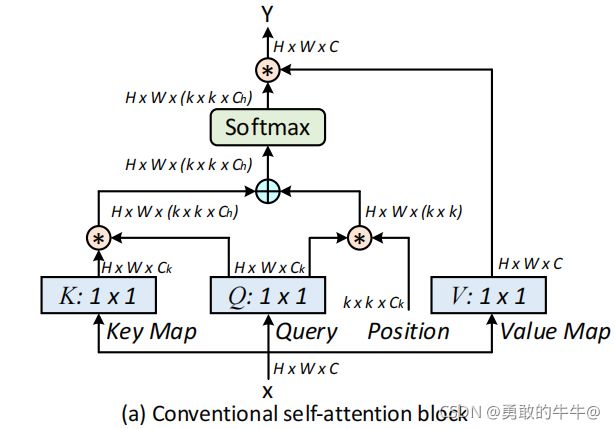
1.在视觉的backbone中,通用的可扩展的局部多头自我注意(scalable local multi-head self-attention),如上图所示。首先用1x1的卷积把X映射到Q、K、V三个不同的空间,Q和K进行相乘获得局部的关系矩阵: R = Q ∗ K R = Q*K R=Q∗K(*代表点积)
2.由于原始的Self-Attention对输入特征的位置是不敏感的,所以还需要在Q上加上位置信息,然后将结果与关系矩阵相加: R ^ = R + P ∗ Q \hat R = R + P*Q R^=R+P∗Q
3.对于上步骤的结果,我们还需要对上面得到的结果进行归一化,得到Attention Map: A = s o f t m a x ( R ^ ) A = softmax(\hat R) A=softmax(R^)
4.得到Attention Map之后,我们需要将 k × k k\times k k×k的局部信息进行聚合,然后与V相乘,得到Attention之后的结果: Y = A ∗ V Y = A * V Y=A∗V
Contextual Transformer Block(CoT核心模块)

传统的Self-Attention可以很好地触发不同空间位置的特征交互。然而,在传统的Self-Attention机制中,所有的query-key关系都是通过独立的quey-key pair学习的,没有探索两者之间的丰富上下文,这极大的限制了视觉表示学习。因此,作者提出了CoT Block,如上图所示,这个结构将上下文信息的挖掘和Self-Attention的学习聚合到了一个结构中。
- 1.对输入特征 X X X,首先定义了三个变量 Q = X , K = X , V = W v X Q = X,K = X,V = W_vX Q=X,K=X,V=WvX(这里只是将V进行了特征的映射,Q和K还是采用了原来的X值 )。
- 2.在K上进行了 k × k k\times k k×k的分组卷积,来获得具备局部上下文信息表示的K,(记作 K 1 K_1 K1),这个 K 1 K_1 K1可以看做是在局部信息上进行了静态的建模。
- 3.接着将 K 1 K_1 K1和Q进行了 C o n c a t Concat Concat,然后对 C o n c a t Concat Concat的结果进行了两次连续的 1 × 1 1\times1 1×1卷积操作,得到Attention Map: A = [ K 1 , Q ] W θ W δ A = [K_1,Q]W_\theta W_\delta A=[K1,Q]WθWδ
- 4.然后将Attention Map和V进行了点积相乘,得到了动态上下文建模的特征信息: A ^ = A ∗ V \hat A = A * V A^=A∗V
- 5.最后CoT模块的结果为局部静态上下文建模的 K 1 K_1 K1和全局动态上下文建模的 A ^ \hat A A^ Fusion之后的结果。
总结
从COT模块的设计可以发现,其中没有引入位置等信息,完全是对输入的图像做特征处理。对比BoTNet和CoTNet,有相同的细节也有不同的细节,比如在BoTNet模型中 Q 、 K 、 V Q、K、V Q、K、V的生成都是随机的三个权重得来,最后这三个权重都是模型学习的参数,而CoTNet则只引入了一个 W v W_v Wv一个权重参数需要学习,其余的就是引入位置关系这里,这里一直都不是很清楚~~
代码
class CoTNetLayer(nn.Module):
def __init__(self, dim=512, kernel_size=3):
super().__init__()
self.dim = dim
self.kernel_size = kernel_size
self.key_embed = nn.Sequential(
# 通过K*K的卷积提取上下文信息,视作输入X的静态上下文表达
nn.Conv2d(dim, dim, kernel_size=kernel_size, padding=1, stride=1, bias=False),
nn.BatchNorm2d(dim),
nn.ReLU()
)
self.value_embed = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size = 1, stride=1, bias=False), # 1*1的卷积进行Value的编码
nn.BatchNorm2d(dim)
)
factor = 4
self.attention_embed = nn.Sequential( # 通过连续两个1*1的卷积计算注意力矩阵
nn.Conv2d(2 * dim, 2 * dim // factor, 1, bias=False), # 输入concat后的特征矩阵 Channel = 2*C
nn.BatchNorm2d(2 * dim // factor),
nn.ReLU(),
nn.Conv2d(2 * dim // factor, kernel_size * kernel_size * dim, 1, stride=1) # out: H * W * (K*K*C)
)
def forward(self, x):
bs, c, h, w = x.shape
k1 = self.key_embed(x) # shape:bs,c,h,w 提取静态上下文信息得到key
v = self.value_embed(x).view(bs, c, -1) # shape:bs,c,h*w 得到value编码
y = torch.cat([k1, x], dim=1) # shape:bs,2c,h,w Key与Query在channel维度上进行拼接进行拼接
att = self.attention_embed(y) # shape:bs,c*k*k,h,w 计算注意力矩阵
att = att.reshape(bs, c, self.kernel_size * self.kernel_size, h, w)
att = att.mean(2, keepdim=False).view(bs, c, -1) # shape:bs,c,h*w 求平均降低维度
k2 = F.softmax(att, dim=-1) * v # 对每一个H*w进行softmax后
k2 = k2.view(bs, c, h, w)
return k1 + k2 # 注意力融合
版本2:版本2和版本1几乎一样,但是在运行速度上面测试,版本2 总是比版本1 块0.几秒。
import time
import numpy as np
import torch
from torch import flatten, nn
from torch.nn import init
from torch.nn.modules.activation import ReLU
from torch.nn.modules.batchnorm import BatchNorm2d
from torch.nn import functional as F
class CoTAttention(nn.Module):
def __init__(self, dim=512,kernel_size=3):
super().__init__()
self.dim=dim
self.kernel_size=kernel_size
self.key_embed=nn.Sequential(
nn.Conv2d(dim,dim,kernel_size=kernel_size,padding=kernel_size//2,groups=4,bias=False),
nn.BatchNorm2d(dim),
nn.ReLU()
)
self.value_embed=nn.Sequential(
nn.Conv2d(dim,dim,1,bias=False),
nn.BatchNorm2d(dim)
)
factor=4
self.attention_embed=nn.Sequential(
nn.Conv2d(2*dim,2*dim//factor,1,bias=False),
nn.BatchNorm2d(2*dim//factor),
nn.ReLU(),
nn.Conv2d(2*dim//factor,kernel_size*kernel_size*dim,1)
)
def forward(self, x):
bs,c,h,w=x.shape
k1=self.key_embed(x) #bs,c,h,w
v=self.value_embed(x).view(bs,c,-1) #bs,c,h,w
y=torch.cat([k1,x],dim=1) #bs,2c,h,w
att=self.attention_embed(y) #bs,c*k*k,h,w
att=att.reshape(bs,c,self.kernel_size*self.kernel_size,h,w)
att=att.mean(2,keepdim=False).view(bs,c,-1) #bs,c,h*w
k2=F.softmax(att,dim=-1)*v
k2=k2.view(bs,c,h,w)
return k1+k2
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
time1 = time.time()
cot = CoTAttention(dim=512,kernel_size=3)
#cot = CoTNetLayer(dim=512,kernel_size=3)
output=cot(input)
time2 = time.time()
print("时间:{}".format(time2-time1))
print(output.shape)
从代码上来说,确实算是即插即用的模块,不过存在的一点不足是,如果想用他直接来代替其他模块的卷积,要先考虑这个卷积模块有没有填充,也就是输入经过卷积之后的输出是多少,为什么要考虑输入输出呢?就拿这个COT模块而言,他的输入和输出的尺寸和通道数是不变的,输入等于输出。所以也就是你想替换的卷积如果尺寸不变,但输出的通道数变了,直接替换这个模块也是不行的。
使用
很有参考价值的一个“网站”:
https://link.zhihu.com/?target=https%3A//github.com/xmu-xiaoma666/External-Attention-pytorch%2322-CoTAttention-Usage
总结
2021年11月1日,我将CoT注意力模块加在了CSPDarknet53骨干网络中,使原始的CBM(卷积+标准化+激活)变成了(注意力+卷积+标准化+激活),最后的结果有待验证~~
2021年11月2日,这个改进的(注意力+卷积+标准化+激活)结果出来了,参数量大的惊人,但是后来想想,也确实,虽然COT模块中是分组卷积,但是直接加在CBM模块中,这个卷积的数量是倍数增长的,所以训练出来的参数量非常大。最好的方式还是将CoT模块替换掉CBM中的卷积,因为从作者的论文中来看,作者将CoT模块直接替换了Resnet模块中的 3 × 3 3\times3 3×3卷积,参数量还在原基础上减少了,如下图所示:
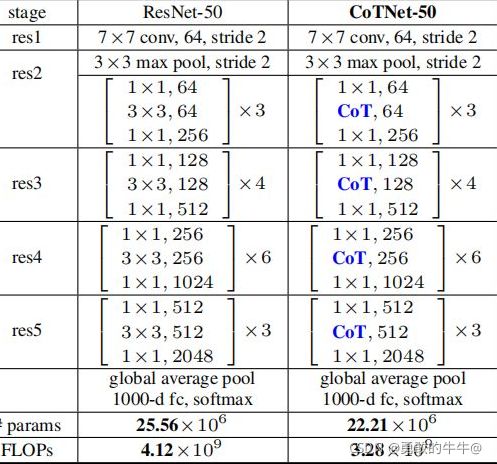
CoT模块中使用了分组卷积,其实这个想法估计也是为了减少参数量,因为它本身有很多的步骤才能替换单纯的一个 3 × 3 3\times3 3×3卷积。所以可以从CoT模块作为切入点,深刻探讨如何改进CoT模块。
CSPDarknet53 - 原始的CBM模块包括( 3 × 3 3\times3 3×3卷积+标准化 B N BN BN+激活 M i s h Mish Mish)
改进一:
CCBM:包括(COT模块+ 1 × 1 1\times1 1×1卷积+标准化 B N BN BN+激活 M i s h Mish Mish)
Swin Transformer
参考文章:
https://zhuanlan.zhihu.com/p/361366090?ivk_sa=1024320u
大多的论述都是参考文章的原文,然后加一些自己的想法,不是原创
概述
该文章以Swin-T为主线进行讲解,Swin-T是Swin系列最简洁(模型相对小)的版本。Swin-T的结构如图所示:
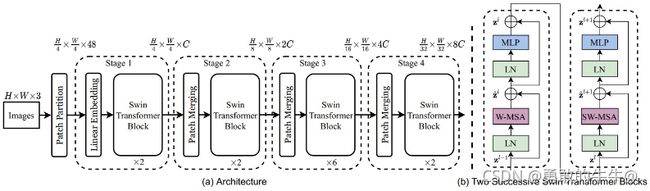
从结构图上来看,Swin Transformer的网络结构很简单,由4个stage和一个输出头组成。Swin Transformer的4个Stage的网络框架的是一样的,每个Stage仅有几个基本的超参来调整,包括隐层节点个数,网络层数,多头自注意的头数,降采样的尺度等。
从图中来看,输入图像之后是一个 P a t c h P a r t i t i o n Patch Partition PatchPartition,再之后是一个 L i n e a r E m b e d d i n g Linear Embedding LinearEmbedding层,这两个加在一起其实就是一个 P a t c h M e r g i n g Patch Merging PatchMerging层。 P a t c h M e r g i n g Patch Merging PatchMerging层的作用是对图像进行降采样,类似于CNN中Pooling层。
未完
ViT(分类)
参考文章:B站:跟李沐学AI
最关键的就是自注意力机制,文本信息处理,会将输入信息依次喂入进网络,每个信息之间都有一定的互动性。所谓互动性,也就是说每个元素之间的关联性。但是作用在CV领域,有人想到把2维的图片拉直,也就是将所有像素拍成列作为输入,可想而知,每个图片都有几万个像素,作为小批量的输入,输入数据量更是大的可怕。所以有人提出,既然Transformer的核心在自注意力,那不如将特征提取后的特征图作为自注意力的输入,大大减少了参数量,和复杂度。Vision Transformer的考虑到一张图片的像素数量很大,单纯的像文本处理一样去处理图片任务,还是存在一定问题的,后来的思想是将输入的图片(224224)拆分成1616个小的图片,就是一整张图片由16个小图片组成。然后Vision Transformer的输入就成了1414,这样的参数量还是可以接受的。1414=196的特征作为输入,在此之上还要加上一个位置信息。输入也就是197,但是每个的维度是16163=768的信息量,通过以上分析,encoder模型的输入是197768,而经过lenar Norm和多头注意力和MLP之后,做后的输出还是197768。而Vision Transformer模型的架构就是多个这种encoder模型组成的。