R语言文本聚类实例——以《金庸全集》为例
写在前面
因为结课论文的需要,我想写一篇关于分析金庸小说的小论文,查了些资料,感觉还行,一动手,发现问题大了去了。
所有的资料都有一个共同的问题:碎片化,不成体系。乍一看感觉是可行的,但是你真的动手去做的时候,就发现两个问题:
1、无从下手。脑子里的想法不知道怎么开始落实。
2、连不起来。各个步骤你基本都能查到,但是没办法理成一个完整、切实可行的流程。
以上是我着手做这件事的时候遇到的问题,把这些问题都解决好花了我小半个月的时间(时间零散,加上人也笨),终于可以把它整个的走一遍了。跟着我来,从获取素材开始,带你完整的走一遍文本聚类分析,不一定直接对你有用,但是它一定是一个好的分析模板。
下是目录,先直观的看看需要哪些步骤:
1、文本获取
2、文本预处理
3、导入R(代码开始)
4、分词和词频统计
5、选取聚类指标
6、数据整合
7、文本聚类及可视化
8、总结
1、文本获取
文本的获取当然很简单,自己从网上找到金庸先生的小说就好了,想分析哪个版本就下载哪个版本,这些资料很容易找到。
需要注意的是R语言对中文还是不太友好,需要找简体的小说,不能有繁体字,否则之后的分析会很麻烦。
2、文本预处理
这一步很重要,因为得到的原始小说是无法正常导入R中的。我在这一步尝试了很久,它一直提示读取到某某字符发生错误,而这些字符你在下载来的小说里根本就找不到。。。
弄了很久,我才想到一个有损信息质量的操作:
去标点符号。把所有你知道的标点符号都去掉,只留下汉字和空格、换行符,在导入R就顺利得多了。去标点符号需要用word,把小说一部一部的复制进word,通过【通配符】把所有的标点符号都替换成空格,就达到了目的。
我用到的通配符有:[『』,。、?!:“”……《》](英文的“[ ]”是通配符的标志)。
具体步骤如下:
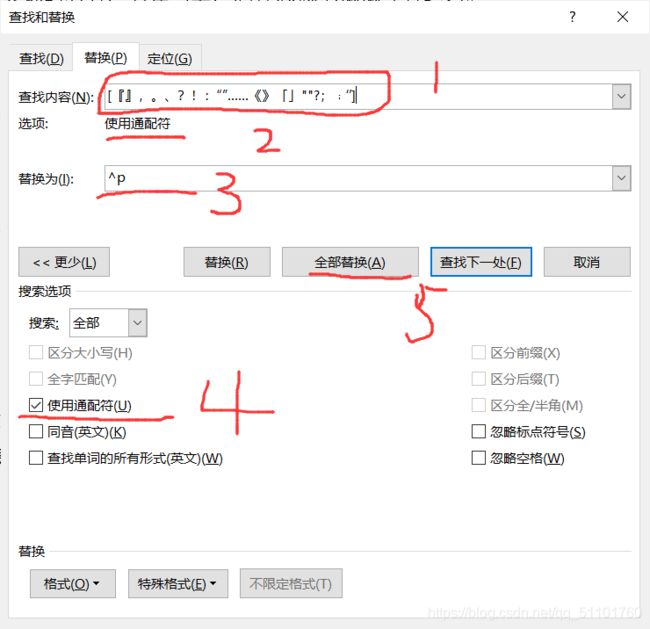
这里需要一点时间,因为整部小说很长,word处理它可能需要一两分钟,需要一点点耐心,而且得一部一部得弄,会有点小烦。
3、导入R(代码开始)
做好第一步的数据预处理,后面的难度就下降很多了。把14部小说以向量的形式导入R,还是那个笨办法:一部一部的导入。
当然也有更轻松的方法,不过它不够简单易懂。
导入的代码如下:
#设置工作空间
setwd("C:\\Users\\Administrator\\Desktop\\金庸小说全集-旧版")
#导入文本
x <- readLines("白马啸西风.txt")
head(x) #查看头几行,看是否乱码这里以及本文的所有代码,都只有设置工作空间的代码要改,其它的都不用,只要把处理好的小说保存为txt格式就和我的代码完全对上了。
如果能看到小说的前几行,也没有乱码,那就没问题了。
4、分词和词频统计
确定小说能够导入之后,就可以进行文本分析的步骤了。这里的代码和上一部分的代码有一些重复,不过完全不影响,可以以此复制粘贴,肯定可以运行。
#设置工作空间
setwd("C:\\Users\\Administrator\\Desktop\\金庸小说全集-旧版")
#导入包【 下载:install.packages("包名") ,下载不成功:选择镜像】
library(Rwordseg)
library(rJava)
#白马啸西风
#导入文本
x <- readLines("白马啸西风.txt")
#开始分词
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
#拆分列表为向量
y <- unlist(y)
#过滤数字
y <- y[!grepl('[0-9]',y)]
#过滤空白以及单个词
y <- y[nchar(y)>=2]
#1、词频统计 2、进行排序 3、留下前50个 4、封装成数据框
y1 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
#看看效果
y1
#碧血剑
x2 <- readLines("碧血剑.txt")
y2 <- segmentCN(x2,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y2 <- unlist(y2)
y2 <- y2[!grepl('[0-9]',y2)]
y2 <- y2[nchar(y2)>=2]
y2 <- as.data.frame(sort(table(y2),decreasing = TRUE)[1:50])
y2
#飞狐外传
x <- readLines("飞狐外传.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y3 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y3
#鹿鼎记
x <- readLines("鹿鼎记.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y4 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y4
#射雕英雄传
x <- readLines("射雕英雄传.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y5 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y5
#神雕侠侣
x <- readLines("神雕侠侣.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y6 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y6
#书剑恩仇录
x <- readLines("书剑恩仇录.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y7 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y7
#天龙八部
x <- readLines("天龙八部.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y8 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y8
#侠客行
x <- readLines("侠客行.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y9 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y9
#笑傲江湖
x <- readLines("笑傲江湖.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y10 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y10
#雪山飞狐
x <- readLines("雪山飞狐.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y11 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y11
#倚天屠龙记
x <- readLines("倚天屠龙记.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y12 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y12
#鸳鸯刀
x <- readLines("鸳鸯刀.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y13 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y13
#越女剑
x <- readLines("越女剑.txt")
y <- segmentCN(x,nature = FALSE, nosymbol = TRUE, returnType = c("vector", "tm"), isfast = FALSE, outfile = "", blocklines = 10000)
y <- unlist(y)
y <- y[!grepl('[0-9]',y)]
y <- y[nchar(y)>=2]
y14 <- as.data.frame(sort(table(y),decreasing = TRUE)[1:50])
y14
#把14个数据框合并成一个
jydata <- cbind(y1,y2,y3,y4,y5,y6,y7,y8,y9,y10,y11,y12,y13,y14)
jydata
#导出数据成txt文本文件(两种方式),方便下次导入
write.table(jydata,file ="f2.txt", row.names = FALSE, col.names =FALSE, quote =FALSE)
#导出的文件在工作空间所在的位置
这部分的代码注释都很清楚了,就不在过多的解释,文本分析的原理我也不想在这儿解释,如果能搜到这篇文章,我相信至少也是对它有初步了解的吧。
就算不懂也没事,你只需要知道,代码复制过去,能运行出正确的结果就行了。
需要提醒的是,这部分代码要运行很长时间,我的R运行完它们花了大概20分钟。这也能让我们清晰的感受到R的处理速度……
可以在脑子里想象这样一个画面:一根刻满汉字的无限长的木头,你拿着一把快刀,在可以分词的地方把它砍断,如此重复,木头越来越短,知道全部变成一小截一小截的……
5、选取聚类指标
分完词之后,得到的是小说里面出现频率最高的词,这些词频的不同就可以表现出不同小说的差异程度。
当然,分词的结果并不太理想,有一些词都不是自然词,这是R分词词库的问题,暂时可以忽略。
我要说的是虽然目前的分词结果并不理想,但对后面的分析没有太大的影响,因为那些奇奇怪怪的词我们都用不到它。
选取所有小说都出现过的词,以此作为聚类的指标,代码如下:
#设置工作空间
setwd("C:\\Users\\86178\\Desktop\\初步分析导出的数据")
#导入看看对不对
data1 <- read.table("f2.txt")
data1
a1 <- data1[,1]
a2 <- data1[,3]
a3 <- data1[,5]
a4 <- data1[,7]
a5 <- data1[,9]
a6 <- data1[,11]
a7 <- data1[,13]
a8 <- data1[,15]
a9 <- data1[,17]
a10 <- data1[,19]
a11 <- data1[,21]
a12 <- data1[,23]
a13 <- data1[,25]
a14 <- data1[,27]
#创建方法:筛选相同的词作为指标
repeat.R <- function(a,b){
as <- vector()
k=0
for(i in 1:length(a)){
for(j in 1:length(b)){
if(a[i]==b[j]){
as[k+1] <- a[i]
k=k+1
}
}
}
return(as)
}
#第一次筛选
t1 <- repeat.R(a1,a2)
t2 <- repeat.R(a3,a4)
t3 <- repeat.R(a5,a6)
t4 <- repeat.R(a7,a8)
t5 <- repeat.R(a9,a10)
t6 <- repeat.R(a11,a12)
t7 <- repeat.R(a13,a14)
#第二次筛选
tt1 <- repeat.R(t1,t2)
tt1
tt2 <- repeat.R(t3,t4)
tt2
tt3 <- repeat.R(t5,t6)
tt3
#第三次筛选
ttt1 <- repeat.R(tt1,tt2)
ttt1
#ttt2 <- repeat.R(tt3,t7)
#第四次筛选
tttt <- repeat.R(ttt1,tt3)
tttt
#频数的操作
b1 <- data1[,2]
b2 <- data1[,4]
b3 <- data1[,6]
b4 <- data1[,8]
b5 <- data1[,10]
b6 <- data1[,12]
b7 <- data1[,14]
b8 <- data1[,16]
b9 <- data1[,18]
b10 <- data1[,20]
b11 <- data1[,22]
b12 <- data1[,24]
b13 <- data1[,26]
b14 <- data1[,28]
#创建方法:筛选相同的词的频率
repeat.R2 <- function(t,a,b){
as <- vector()
k=0
for(i in 1:length(t)){
for(j in 1:length(a)){
if(t[i]==a[j]){
as[k+1] <- b[j]
k=k+1
}
}
}
return(as)
}
m1 <- repeat.R2(tttt,a1,b1)
m2 <- repeat.R2(tttt,a2,b2)
m3 <- repeat.R2(tttt,a3,b3)
m4 <- repeat.R2(tttt,a4,b4)
m5 <- repeat.R2(tttt,a5,b5)
m6 <- repeat.R2(tttt,a6,b6)
m7 <- repeat.R2(tttt,a7,b7)
m8 <- repeat.R2(tttt,a8,b8)
m9 <- repeat.R2(tttt,a9,b9)
m10 <- repeat.R2(tttt,a10,b10)
m11 <- repeat.R2(tttt,a11,b11)
m12 <- repeat.R2(tttt,a12,b12)
#m13 <- repeat.R2(tttt,a13,b13)
#m14 <- repeat.R2(tttt,a14,b14)
m13 <- c(67,38,45,0,35,25,21,25,27)
m14 <- c(16,9,0,9,21,0,0,0,10)
ldata <-matrix(c(m1,m2,m3,m4,m5,m6,m7,m8,m9,m10,m11,m12,m13,m14),nrow=14,byrow = TRUE)
ldata
colnames(ldata) <- c("一个","自己","咱们","他们","一声","只见","出来","知道","原来")
rownames(ldata) <- c("白马啸西风","碧血剑","飞狐外传","鹿鼎记","射雕英雄传","神雕侠侣","书剑恩仇录","天龙八部","侠客行","笑傲江湖","雪山飞狐","倚天屠龙记","鸳鸯刀","越女剑")
#看看效果
ldata
#转成数据框
ldata <- as.data.frame(ldata)
#导出数据成txt文本文件(两种方式)
write.table(ldata,file ="dt.txt", row.names = TRUE, col.names =TRUE, quote =FALSE)
上一步的代码已经说了,导出的文件在工作空间所在的位置,把分析结果导出成文件的好处就是下次想再处理就不用再从头开始跑代码了。
现在得到的是一个很规律的数据框,和课本、资料上的聚类分析的数据基本上一样了。
做到这一步就发现对我们而言难点是数据的处理过程,而非数据的分析过程,数据分析过程书上都会有,然而数据到达可以分析之前的处理过程书上是没有的。编书的人以为这点儿常识我们应该懂的,但其实我们并不太懂。。
6、数据整合
这步原本是可以没有的,因为这是上一步的一个小失误的弥补,我本来可以直接改掉,不过分享一些犯错的过程也不错。
所有的错误都是经验,它有时候甚至比成功更令人印象深刻。
#创建向量
ldata <- read.table("dt.txt")
#查看类型(我们需要的是数据框类型"data.frame")
class(ldata)
#重新做一个数据
c1 <- c("白马啸西风","碧血剑","飞狐外传","鹿鼎记","射雕英雄传","神雕侠侣","书剑恩仇录","天龙八部","侠客行","笑傲江湖","雪山飞狐","倚天屠龙记","鸳鸯刀","越女剑")
c2 <- ldata[,1]
c3 <- ldata[,2]
c4 <- ldata[,3]
c5 <- ldata[,4]
c6 <- ldata[,5]
c7 <- ldata[,6]
c8 <- ldata[,7]
c9 <- ldata[,8]
c10 <- ldata[,9]
ldata2 <- as.data.frame(matrix(c(c1,c2,c3,c4,c5,c6,c7,c8,c9,c10),nrow=14))
colnames(ldata2) <- c("小说名称","一个","自己","咱们","他们","一声","只见","出来","知道","原来")
#导出数据成txt文本文件(两种方式)
write.table(ldata2,file ="PollutionData.txt", row.names = TRUE, col.names =TRUE, quote =FALSE)
这才是我们需要的数据,现在就可以进行分析了。
7、文本分析及可视化
这一部分的分析代码基本上讲聚类的书都有,不过要让它能为我们所用还需要一点点的修改。相应的变量名、参数的修改等。
这些事我都做了,如果上面的代码你都能运行的话,下面这些也一样会很顺利。你可以看看R的作图区域了,那儿有分析的结果。
#数据导入
PoData<-read.table(file="PollutionData.txt",header=TRUE)
CluData<-PoData[,2:10]
#K-Means聚类
set.seed(12345)
CluR<-kmeans(x=CluData,centers=4,nstart=4,iter.max=10)
CluR$size
CluR$centers
# K-Means聚类结果的可视化
par(mfrow=c(1,1))
PoData$CluR<-CluR$cluster
plot(PoData$CluR,pch=PoData$CluR,ylab="类别编号",xlab=" ",main="聚类的类成员",cex.main=0.8,axes=FALSE)
par(las=2)
axis(1,at=1:14,labels=PoData[,1],cex.axis=0.7)
axis(2,at=1:4,labels=1:4,cex.axis=1)
box()
legend("topright",c("第一类","第二类","第三类","第四类"),pch=1:4,cex=0.7)
# K-Means聚类特征的可视化
plot(CluR$centers[1,],type="l",ylim=c(0,1882),xlab="聚类变量",ylab="组均值(类中心)",main="各类聚类变量均值的变化折线图",cex.main=0.8,axes=FALSE)
par(las=1)
axis(1,at=1:9,labels=c("一个","自己","咱们","他们","一声","只见","出来","知道","原来"),cex.axis=0.8)
box()
lines(1:9,CluR$centers[2,],lty=2,col=2)
lines(1:9,CluR$centers[3,],lty=3,col=3)
lines(1:9,CluR$centers[4,],lty=4,col=4)
legend("topleft",c("第一类","第二类","第三类","第四类"),lty=1:4,col=1:4,cex=0.6)
# K-Means聚类效果的可视化评价
CluR$betweenss/CluR$totss*100
par(mfrow=c(2,3))
plot(PoData[,c(2,3)],col=PoData$CluR,main="名词分析",cex.main=0.9,xlab="'咱们'",ylab="'他们'")
points(CluR$centers[,c(1,2)],col=rownames(CluR$centers),pch=8,cex=2)
plot(PoData[,c(2,4)],col=PoData$CluR,main="名词分析",cex.main=0.9,xlab="'自己'",ylab="'咱们'")
points(CluR$centers[,c(1,3)],col=rownames(CluR$centers),pch=8,cex=2)
plot(PoData[,c(3,4)],col=PoData$CluR,main="名词分析",cex.main=0.9,xlab="'知道'",ylab="'原来'")
points(CluR$centers[,c(2,3)],col=rownames(CluR$centers),pch=8,cex=2)
plot(PoData[,c(5,6)],col=PoData$CluR,main="动词、量词分析",cex.main=0.9,xlab="'一个'",ylab="'出来'")
points(CluR$centers[,c(4,5)],col=rownames(CluR$centers),pch=8,cex=2)
plot(PoData[,c(5,7)],col=PoData$CluR,main="动词、量词分析",cex.main=0.9,xlab="'出来'",ylab="'只见'")
points(CluR$centers[,c(4,6)],col=rownames(CluR$centers),pch=8,cex=2)
plot(PoData[,c(6,7)],col=PoData$CluR,main="动词、量词分析",cex.main=0.9,xlab="'只见'",ylab="'出来'")
points(CluR$centers[,c(5,6)],col=rownames(CluR$centers),pch=8,cex=2)
fitted(CluR)
CluData-fitted(CluR)
CluR$totss
CluR$withinss
CluR$tot.withinss
CluR$betweenss
# 层次聚类
PoData<-read.table(file="PollutionData.txt",header=TRUE)
CluData<-PoData[,2:10]
DisMatrix<-dist(CluData,method = "euclidean")
CluR<-hclust(d=DisMatrix,method="ward.D")
# 层次聚类的树形图
par(mfrow=c(1,1))
plot(CluR,labels=PoData[,1],cex.main=0.8)
box()
# 层次聚类的碎石图
plot(CluR$height,13:1,type="b",cex=0.7,xlab="距离测度",ylab="聚类数目")
# 取4类的聚类解并可视化
#par(mfrow=c(2,1))
PoData$memb<-cutree(CluR,k=4)
table(PoData$memb)
plot(PoData$memb,pch=PoData$memb,ylab="类别编号",xlab=" ",main="聚类的类成员",cex.main=0.8, axes=FALSE) #加上ann = FALSE可以去掉标题
par(las=2)
axis(1,at=1:14,labels=PoData[,1],cex.axis=0.8)
axis(2,at=1:4,labels=1:4,cex.axis=1)
box()
#完毕!你真棒!
所有的小说都有的词实在没有太多的个性,比如“一个”、“一声”,“自己”,“他们”等等,但是因为不同的书这些词出现的频率不一样,我们是可以通过这些普通的词把它们区分开的。
最后的聚类结果如下(其中之一):

可以看到如果分为4类,那么《天龙八部》就独立成类,它某种意义上也是金庸小说的最高峰,《射雕三部曲》也在同一类里面,所以我们的聚类是有效的,和大众的主观分类是一致的。
到这里整个文本聚类的过程就完整了,接下来就是论文加工了。我可是连论文都没写就先发文章了,点个赞呗。
8、总结
写这篇文章的原因开头也说了,我在做这个分析的时候查不到这资料,所以想把它补上来,希望能对下一个查找这方面资料的朋友有所帮助。
还是那句话,对我们而言难点是数据的处理过程,而非数据的分析过程,数据分析过程书上都会有,然而数据到达可以分析之前的处理过程书上是没有的。编书的人以为这点儿常识我们应该懂的,但其实我们并不太懂。基本功都不会的情况下,基本功就是最最重要的。
最后,点个赞呗。如果帮到你了,能顺便加个收藏吗?
我就知道你最好了!