目标检测之SPP(Spatial Pyramid Pooling)论文学习
0.摘要
作者:何凯明
ILSVRC2014比赛上物体检测上排名第2,在物体分类上排名第3,是一篇十分很好的论文,体现了何凯明深厚的数学功底,有一些启发:比如多尺度池化是否可以加入注意力机制,多尺度的思想是否可以应用到特征提取阶段(类似densenet、或者多尺度放缩进行数据增强再进行交替训练强化网络)。
SPP 显著特点
- 使用多个窗口(pooling window)
- SPP 可以使用同一图像不同尺寸(scale)作为输入, 但是得到同样长度的池化特征。
在一般的CNN结构中,在卷积层后面通常连接着全连接。而全连接层的特征数是固定的,所以在网络输入的时候,会固定输入的大小,因此会采取一些裁剪(crop)和拉伸(warp)的手段。
图像的纵横比(ratio aspect) 和 输入图像的尺寸是被改变的。这样就会扭曲原始的图像一般空间金子塔池化层,都是放在卷积层到全连接层之间的一个网络层。SPP层对特征进行池化,并产生固定长度的输出,这个输出再喂给全连接层

2.基于空间金字塔池化的深度网络
2.1卷积层和特征图
作者实验了一下一些filer提取的fmap可视化,实验结果很有意思,结论的译文和原文如下。
图2(c)显示了ImageNet数据集中激活最强的若干图像。可以看到一个过滤器能够被一些语义内容激活。例如,第55个过滤器(图2,左下)对圆形十分敏感;第66层(图2,右上)对上尖尖形状特别敏感;第118个过滤器(图2,右下)对下尖尖形状非常敏感。这些输入图像中的形状会激活相应位置的特征图(图2中的箭头)
In Figure 2, we visualize some feature maps. They are generated by some filters of the conv5layer. Figure 2© shows the strongest activated images of these
filters in the ImageNet dataset. We see a filter can be activated by some semantic content. For example, the 55-th filter (Figure 2, bottom left) is most activated by a circle shape; the 66-th filter (Figure 2, top right) is most activated by a ∧-shape; and the 118-th filter (Figure 2, bottom right) is most activated by a ∨-shape .These shapes in the input images (Figure 2(a)) activate the feature maps at the corresponding positions (the arrows in Figure 2).
2.2 空间金字塔池化层
卷积层接受任意输入大小,但它们也产生可变大小的输出。分类器(SVM / softmax)或全连接层需要固定长度的矢量。这些向量可以通过将特征汇集在一起的Bag-of-Words方法生成:
2.2.1 Bag-of-Words
BoW模型最初应用于文本处理领域,用来对文档进行分类和识别。在应用BoW模型来表述图像时,图像被看作是文档,而图像中的关键特征被看作为“单词”,其应用于图像分类时主要包括三个步骤:
第一步:利用SIFT算法从不同类别的图像中提取视觉词汇向量,这些向量代表的是图像中局部不变的特征点(类似卷积层);

第二步:将所有特征点向量集合到一块,利用K-Means算法合并词义相近的视觉词汇,构造一个包含K个词汇的单词表(类似池化层);
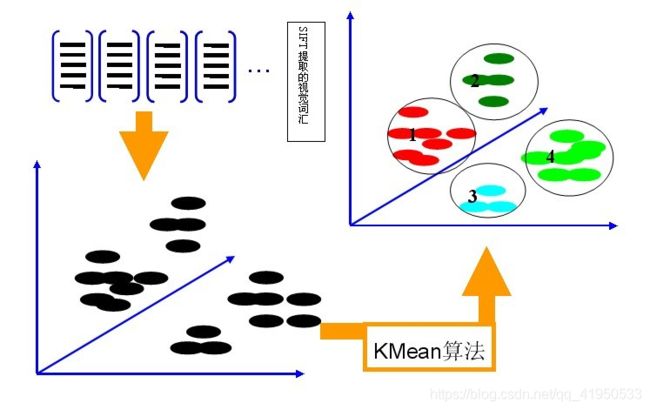
第三步:统计单词表中每个单词在图像中出现的次数,从而将图像表示成为一个K维数值向量(类似全连接层)
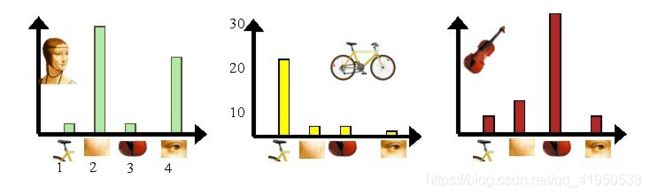
bow缺点是没有位置(空间)信息,因为图片都被完全切割了。Spatial Pyramid Matching是带位置信息的bow。也是spp借鉴的思想之一,都是远古传统机器学习的论文。空间金字塔池化改进了BoW,因为它可以通过在局部空间中pooling来维护空间信息。
2.2.2单个输入大小空间金字塔池化
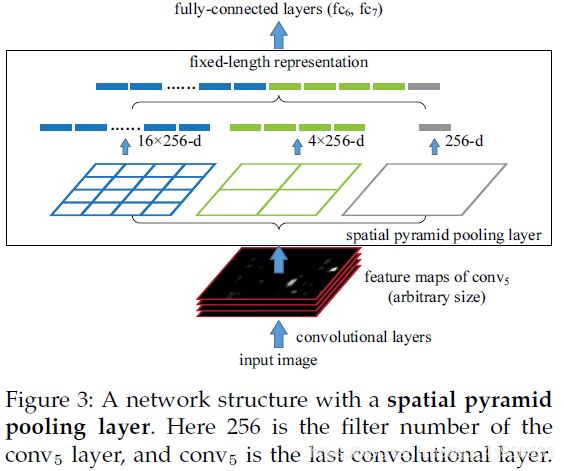
如上图所示,当我们输入一张图片的时候,我们利用不同大小的刻度,对一张图片进行了划分。上面示意图中,利用了三种不同大小的刻度,对一张输入的图片进行了划分,最后总共可以得到16+4+1=21个块,我们即将从这21个块中,每个块提取出一个特征,这样刚好就是我们要提取的21维特征向量。
第一张图片,我们把一张完整的图片,分成了16个块,也就是每个块的大小就是(w/4,h/4);
第二张图片,划分了4个块,每个块的大小就是(w/2,h/2);
第三张图片,把一整张图片作为了一个块,也就是块的大小为(w,h)
空间金字塔最大池化的过程,其实就是从这21个图片块中,分别计算每个块的最大值,从而得到一个输出神经元。最后把一张任意大小的图片转换成了一个固定大小的21维特征。上面的三种不同刻度的划分,每一种刻度我们称之为:金字塔的一层,每一个图片块大小我们称之为:windows size了。如果你希望,金字塔的某一层输出n*n个特征,那么你就要用windows size大小为:(w/n,h/n)进行池化了。
最粗糙的金字塔会覆盖整个图像。这实际上是一个“全局池化”操作,全局平均池化用于减小模型大小并减少过度拟合,弱监督对象识别中全局最大池化也有优势。
本文中input层是224224,之后con5之后变成了1313,对于nxn块(bins),L层的金字塔级,要实现一个滑窗池化过程,窗口大小为win = 上取整[13/n],步幅str = 下取整[13/n]
论文中全连接层总共256×(9+4+1)个神经元, 即输全连接层输入大小为256×(9+4+1)。由于pooling窗口(w×w)很明显如果我们用一个pooling窗口怎么也很难得到f=9+4+1=14,再加上如果输入图像尺度变化的话,是根本不可能,所以这里用了3个pooling窗口,如下:。

将3个pooling后的结果合并,很容易发现和我们的期望一致
2.2.3多个输入大小空间金字塔池化
前提:每个数均可表示成若干个完全平方数,完全平方数是可以重复的。
基于此条公理,我们合理的调控win和str两个数值就可以再任意输入(任意但没完全任意)的情况下,都可以获得等规模的全连接层的输入,及使得任意大小的特征图都能够转换成固定大小的特征向量,这就是空间金字塔池化的作用(多尺度特征提取出固定大小的特征向量)
本文中作者考虑两种尺寸:除了224×224之外还有180×180。我们将上述224×224区域的大小resize为180×180,而不是裁剪较小的180×180区域。因此,两种尺度的区域仅在分辨率不同,但在内容和位置信息上是一样的。
2.3目标检测
利用SPP-Net进行物体检测识别的具体算法的大体流程如下:
1、首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
2、特征提取阶段。这一步就是和R-CNN最大的区别了,同样是用卷积神经网络进行特征提取,但是SPP-Net用的是金字塔池化。这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度是大大地快啊。因为R-CNN就相当于遍历一个CNN两千次,而SPP-Net只需要遍历1次。
rcnn:把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个候选窗台提取出一个特征向量,也就是说利用CNN进行提取特征向量。
3、最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
3.结果
由于是老论文,而且是也是易插拔模块所以就不展示实验结果和网络结构了,复述一下作者的结论吧:
1.多窗口的pooling会提高实验的准确率
输入同一图像的不同尺寸,会提高实验准确率(数据增强)
2.图像输入的尺寸对实验的结果是有影响的
替代的是网络的Poooling层,对整个网络结构没有影响,所以可以使得整个网络可以正常训练
3.也可以当作目标检测