R语言学习记录:聚类分析的R实现
时间: 2018-08-04
参考教程: Learn R | 统计建模之聚类分析(上)、 Learn R | 统计建模之聚类分析(下)
学习内容:聚类分析的R实现
数据来源:《应用多元统计分析》 王学民 编著 P198 习题6.5
聚类分析
1. 计算欧式距离
使用dist函数可以计算欧式距离:
> data <- iris[1:4]
> dist_iris <- dist(data)
> head(as.matrix(dist_iris)[,1:4],4)
1 2 3 4
1 0.0000000 0.5385165 0.509902 0.6480741
2 0.5385165 0.0000000 0.300000 0.3316625
3 0.5099020 0.3000000 0.000000 0.2449490
4 0.6480741 0.3316625 0.244949 0.00000002. 读取excel数据,并进行标准化处理
R中有几个用来读取excel数据的包,如:readxl、openexlsx等。其中readxl包只能读取xlsx格式的excel表。
由于readxl包不支持读取第一列作为列名,而本次练习使用的excel表中含有行名和列名,因此本次练习选用openexlsx包读取excel数据。
安装包:install.packages(“openxlsx”)
载入包:library(“openxlsx”)
读取数据使用read.xlsx函数,函数格式为:
read.xlsx(xlsxFile, sheet=1, startRow=1, colNames=TRUE, rowNames=FALSE, detectDates=FALSE, skipEmptyRows=TRUE, skipEmptyCols=TRUE, rows=NULL, cols=NULL, check.names=FALSE, namedRegion=NULL, na.strings=”NA”, fillMergedCells=FALSE)
使用的excel表:
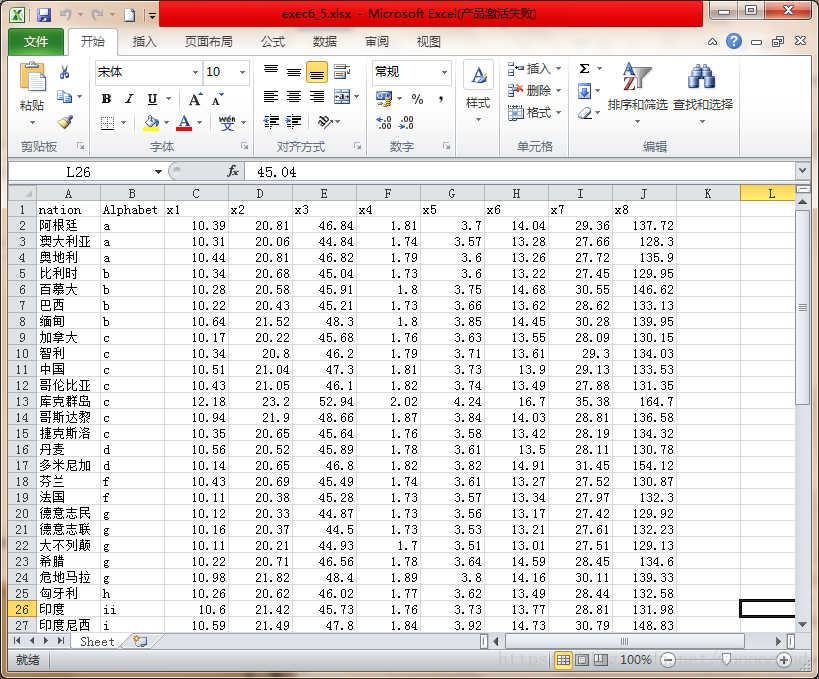
读取数据:
> data2 <-read.xlsx("E:\\Learning_R\\聚类分析\\exec6_5.xlsx", rowNames = TRUE, rows = 1:56, cols = c(1,3,4,5,6,7,8,9,10))
# 对数据进行标准化处理(均值为0,方差为1)
> data2_scale <- scale(data2)
# 计算各观测值之间的欧式距离
> data2_dist <- dist(data2_scale)3. 层次聚类分析
使用hclust函数进行聚类分析。
格式:hclust(data, method = )
其中,参数method表示使用的方法,常用的层次聚类分析方法有最短距离法、最长距离法、中间距离法、重心法、类平均法和离差平方和法(Ward法)。
如:
3. 1. 最短距离法
# 使用最小距离法进行聚类操作
> data2_average2 <- hclust(data2_dist,method='single')
> plot(data2_average2, hang=-1,cex=.8) 
-
- 最长距离法
# 使用最大距离法进行聚类操作
> data2_average3 <- hclust(data2_dist,method='complete')
> plot(data2_average3, hang=-1,cex=.8) 
-
- 中间距离法
# 使用中间距离法进行聚类操作
> data2_average4 <- hclust(data2_dist,method='median')
> plot(data2_average4,hang=-1,cex=.8)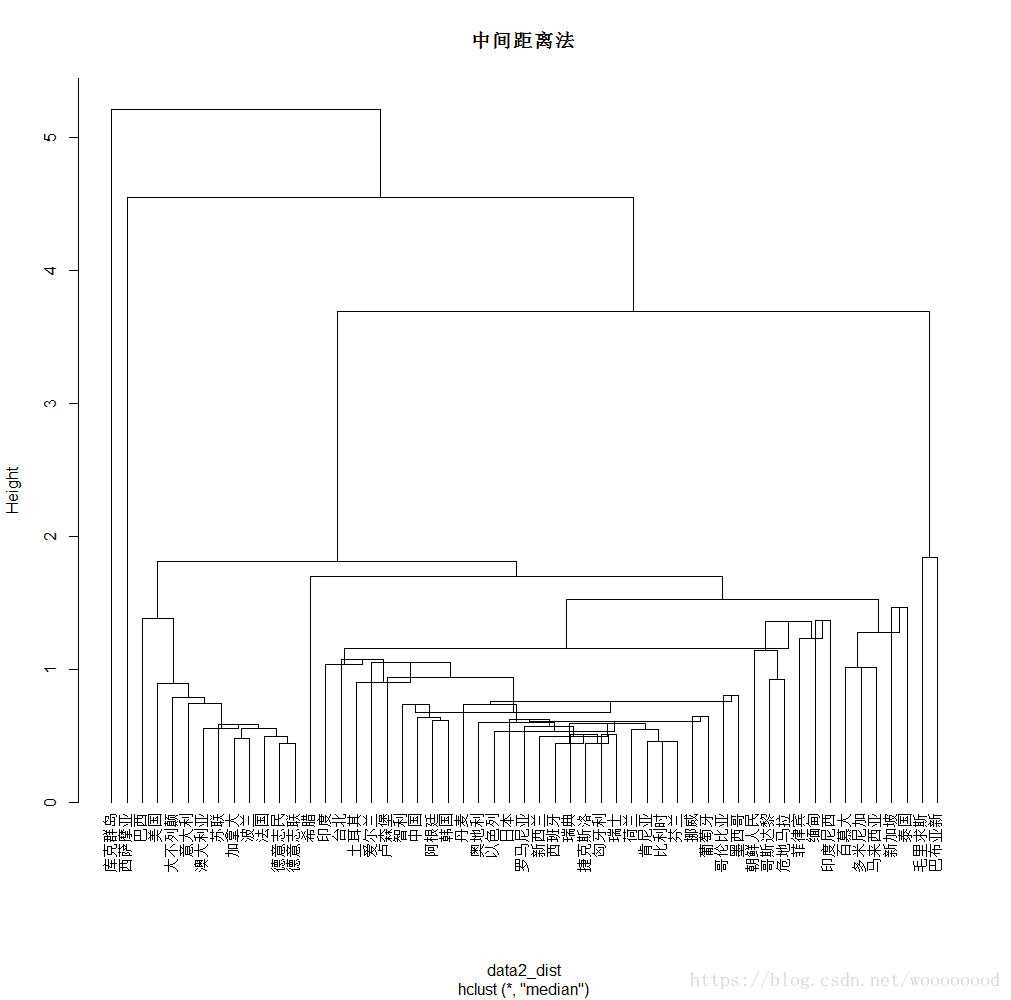
-
- 重心法
# 使用重心法进行聚类操作
> data2_average5 <- hclust(data2_dist,method='centroid')
> plot(data2_average5,hang=-1,cex=.8) 
-
- 类平均法
# 使用类平均法进行聚类操作
> data2_average <- hclust(data2_dist,method='average')
> plot(data2_average,hang=-1,cex=.8)
-
- 离差平方和法
# 使用离差平方和法进行聚类操作
> data2_average6 <- hclust(data2_dist,method='ward.D
')
> plot(data2_average6,hang=-1,cex=.8)
4. 动态聚类方法
-
- k均值法
k均值法针对于均值,对于异常值较为敏感。
如:
- k均值法
# 设定分为4类,可自行调整
kmeans(data2_scale2,4)
library(ggfortify)
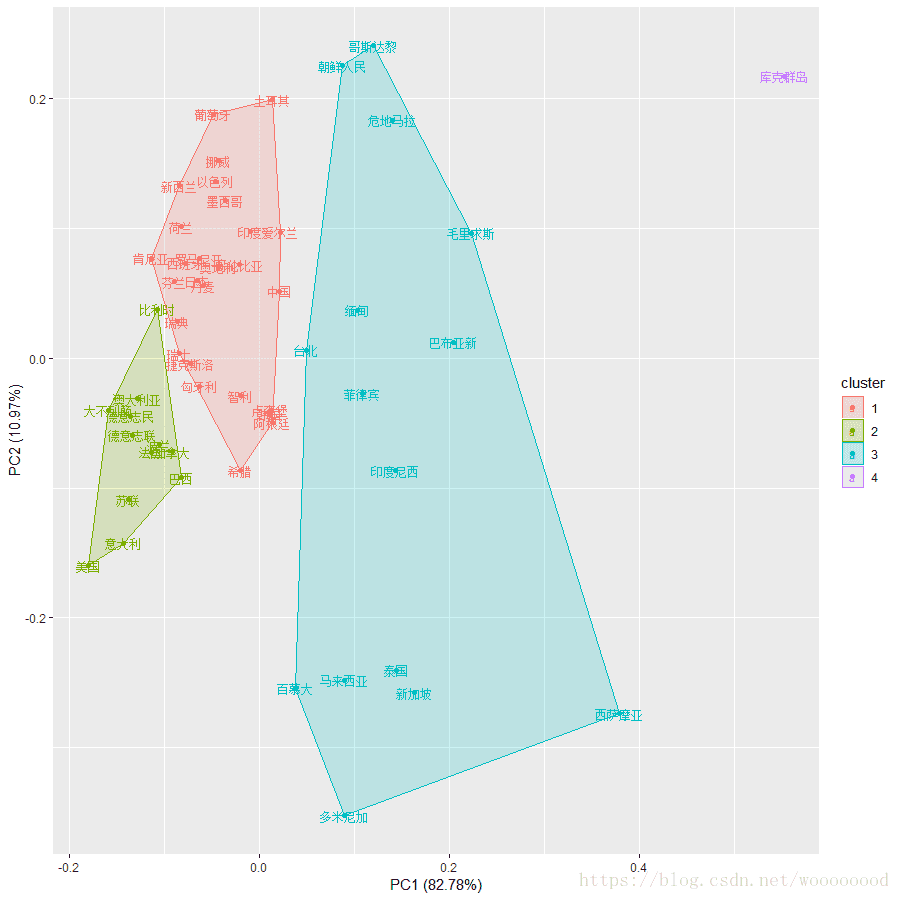
autoplot(kmeans(data2_scale2, 4), data = data2_scale2, label=TRUE, label.size = 3,frame = TRUE)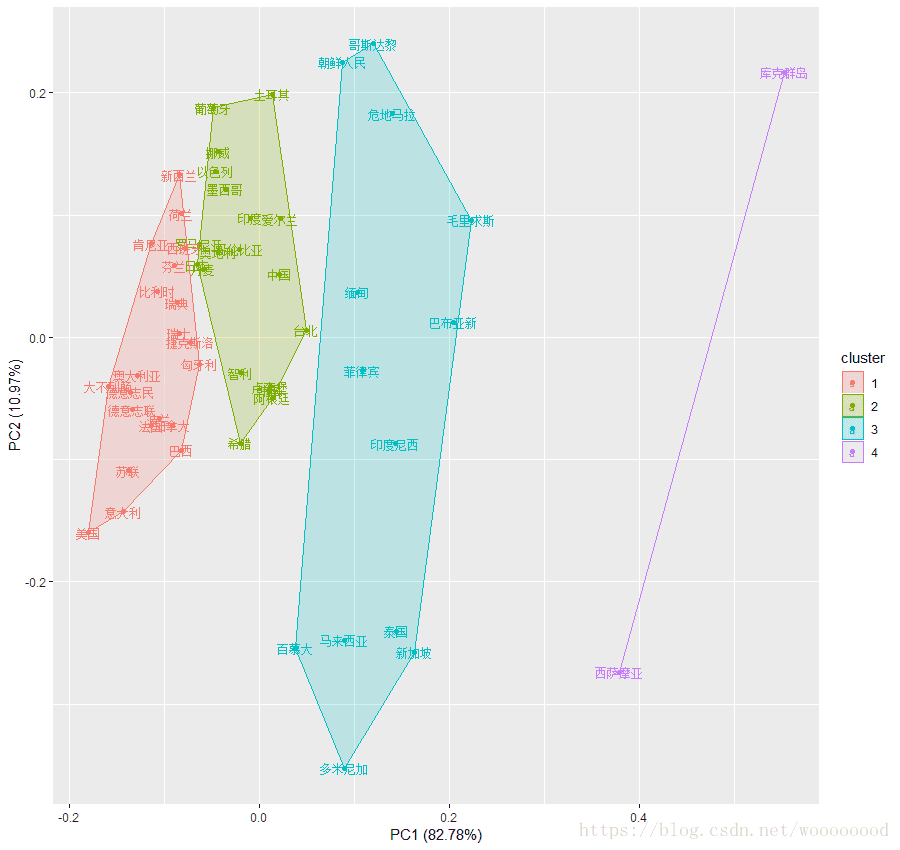
-
- PAM法:围绕中心点的划分
该方法是对于中心点的划分,对于存在异常值的数据,该方法相比k均值更好。
在R中,使用cluster包的pam函数来实现算法。
如:
- PAM法:围绕中心点的划分
library(cluster)
data_pam <- pam(data2_scale,k=4,stand=TRUE)
data_pam
autoplot(pam(data2_scale,k=4,stand = TRUE), data =data2_scale, label=TRUE, label.size = 3, frame = TRUE)