2022年首届天府杯数学建模国际大赛-问题C: E-Commerce Product Sales Forecast电子商务产品销售预测思路详解
选题分析
问题C是一道偏数据分析题目,侧重考察预测类模型。题目中明确提到需要用“更优秀的智能人工智能算法”,明示要用到一些比较新的机器学习模型来完成预测。同时该题目也非常贴心地提供了数据,并分好了训练与测试集,22万的数据量也并不算大,个人笔记本完全可以跑起来。这道题就非常适合对机器学习比较熟悉的小伙伴选择,若想冲奖,单纯的套模型肯定不够好,需要贴合题意的数据预处理,以及多种模型的对比与分析,最好可以多模型融合或者模型创新。
题目翻译
随着公司不断创造商品销售额,其数据对其自身的营销规划、市场分析和物流规划具有重要意义。然而,影响销售预测的因素很多。传统的基于统计的测量模型,如时间序列模型,不适合现实。假设太多,导致预测结果不佳。因此,需要更优秀的智能人工智能算法来提高预测的准确性,从而帮助企业降低库存成本、缩短交货周期,并提高抵御风险的能力。
附件包含两类数据:商品历史销售数据、商品月度订单数据。商品历史需求销售数据提供商品代码、日期、是否销售、商品销售量。商品月度订单数据提供商品代码、商品类型、月份、订单数量、月初和月末的库存。(标签中的空值表示该产品当天没有销售)。

请建立一个数学模型来解决以下问题:
问题1:完成附件中数据的数据预处理,并解释预处理方法。
问题2:从统计分析来看,月初库存与月底库存之间是否存在明显的关系,以及商品类型对商品库存的影响是什么?
问题3:根据提供的样本建立模型,预测未来三个月的产品销售量,并测试预测模型。评估指标(准确度1)是每个月所有产品的平均准确度。在提交示例中写下您的预测结果,附件中给出了需要预测的产品和月份,预测销售量填写在标签中。
问题4:请扩展数据中存在的其他研究价值的描述,并根据之前的结论撰写不超过两页A4论文的商业报告。
(数据来源:http://challenge.xfyun.cn/topic/info?type=product-sales)

评估函数
题目拆解分析
题目给出四个小问,分别可概括如下:
(1)数据预处理
(2)变量之间的关系——>推测影响并分析
(3)建立预测模型
(4)扩展数据价值(语文建模)
首先题目中明确提到“传统的基于统计的测量模型,如时间序列模型,不适合现实。假设太多,导致预测结果不佳”,也就是说,不可以仅使用传统的时间序列模型(包括AR/MA等)。那么其他的经典预测模型有:灰色预测、逻辑回归、支持向量机回归等。但是考虑到给出的数据类型单一,想要排除时间这一变量十分困难,因此入手点应该是整合新的标签变量,并选取可以结合时间变量但并不单一依赖于时序的机器学习模型。
解题思路
(1)数据预处理:
由题意“标签中的空值表示该产品当天没有销售”,所以需要将空值补0,但是经检查,数据集中并无空值,猜测出题方默认已经转化了零值。
既然不需要对空缺值进行填充,那么预处理就变得简单了起来。为便于后续的对比,将Commodity demand training set和Commodity monthly order training set中的日期统一,即在Commodity demand training set中新增列“Year”和“Month”对应原先的“date”,代码如下:
import pandas as pd
df_demand=pd.read_csv('Commodity demand training set.csv',low_memory=False)
df_monthly=pd.read_csv('Commodity monthly order training set.csv',low_memory=False)
df_demand['Year']=df_demand['date'].apply(lambda x: int(x[0:4]))
df_demand['Month']=df_demand['date'].apply(lambda x: int(x[5:7]))输出结果如下:

接下来,我们简单绘制图像观测数据特征(以1001号商品为例):
import matplotlib.pyplot as plt # plots
df_de1=df_demand[df_demand['product_id']==1001]
print(df_de1)
df_de1 = df_de1.set_index(['date'], drop=True)
plt.figure(figsize=(18, 6))
df_de1['label'].plot()
plt.title('merchandise sales (daily data)')
plt.grid(True)
plt.show() #1001商品销量时间序列可视化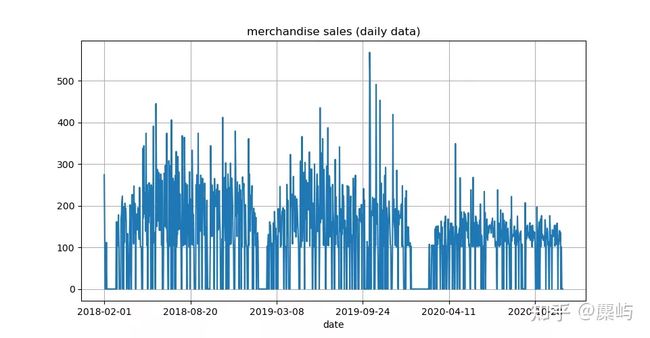
product_id=1001,销量时序
不难看出,销量的数据跟时间有着较强的关系,且数据存在季节特征。
接着分别测验了id为1002和1003的数据,结果如下:

product_id=1002,销量时序
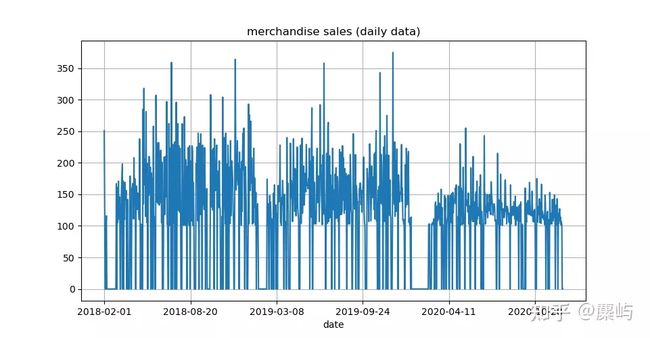
product_id=1003,销量时序
不难发现它们具有相似的季节特性,且都与时间高度相关。
(2)寻找变量之间的关系
同样以1001号的数据为例,绘制月初与月末库存的散点图:

id=1001
由图像很难看出有什么直接的关系。
接着我们忽略商品id的影响,尽可能选取多的数据点绘制散点图(由于图片显示限制,选取了部分但是较多的原始数据)
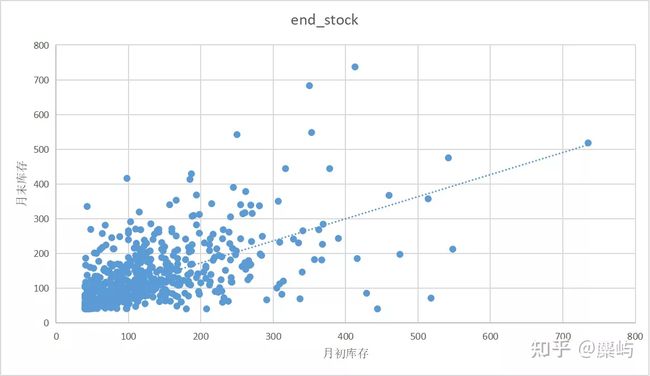
发现散点出现了聚集的趋势。
这里从简单统计学分析的角度寻找月初库存与月底库存之间是否存在明显的关系以及商品类型对商品库存的影响是难以得到精确的关系的,需要借助显著性分析。
利用SPSS获得变量间的相关系数,初步判断相关性是否显著。
(3)预测模型
一般销量预测,特征工程主要从这几个方面入手:时间相关特征、历史销量相关特征、价格相关特征。
可以采用神经网络模型或者决策树模型,这里笔者采用LightGBM。
同XGBoost类似,LightGBM依然是在GBDT算法框架下的一种改进实现,是一种基于决策树算法的快速、分布式、高性能的GBDT框架,主要说解决的痛点是面对高维度大数据时提高GBDT框架算法的效率和可扩展性。
“Light”主要体现在三个方面,即更少的样本、更少的特征、更少的内存,分别通过单边梯度采样(Gradient-based One-Side Sampling)、互斥特征合并(Exclusive Feature Bundling)、直方图算法(Histogram)三项技术实现。另外,在工程上面,LightGBM还在并行计算方面做了诸多的优化,支持特征并行和数据并行,并针对各自的并行方式做了优化,减少通信量。
训练的损失函数采用tweedie,由于存在间歇性需求的问题,很多商品的销量的销量为0,满足tweedie分布,因此采用tweedie作为损失函数效果要比mse要更好,由于时间序列的数据存在先后,只能用历史来预测未来,因此在交叉验证的时候就得格外小心,不能使用随机划分,因为这样会泄露未来的数据,但是时序也有自己的一套交叉验证方法,我这里使用了三折交叉。
使用三折交叉验证,建立三个LGB模型:
由于树模型无法捕捉到趋势,只能学习到历史的东西,不能外推,预测的时候就容易偏高或者偏低,所以最终的结果需要根据经验估计一个系数来修正预测误差。
https://mbd.pub/o/bread/mbd-Y5qamZdt