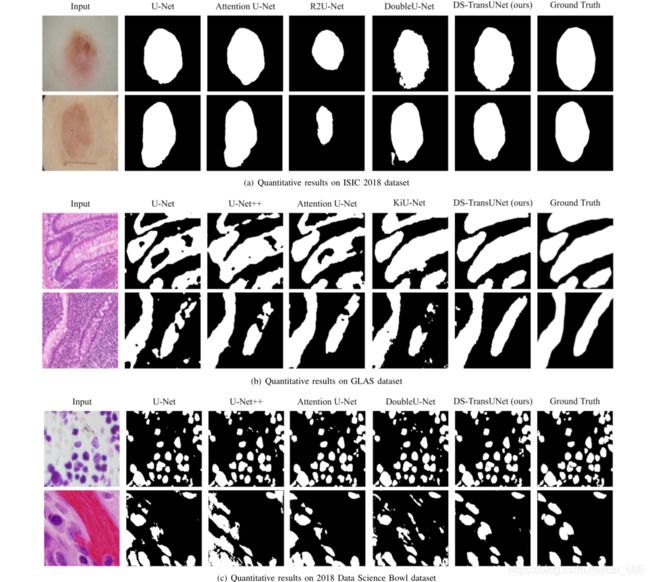
论文:DS-TransUNet 医学图像分割
DS-TransUNet: Dual Swin Transformer U-Net for Medical Image Segmentation
论文:https://arxiv.org/abs/2106.06716
Swin Transformer、更多相关阅读
更多 生物医学图像处理
Introduction
医学图像分割是一个重要而又具有挑战性的研究问题,涉及到临床应用中的许多常见任务,如息肉分割、病变分割、细胞分割等。而医学图像分割是医学图像处理与分析领域中一个复杂而关键的环节,在计算机辅助临床诊断系统中起着重要的作用。其目的是通过半自动或自动的过程对医学图像中具有特殊意义的部分进行分割,提取相关特征,为临床诊断和病理研究提供可靠的依据,协助医生做出更准确的诊断。
随着U-Net的普及,许多新颖的模型被提出,如UNet++、Res-UNet、Attention U-Net、DenseUNet、R2U-Net、KiU-Net和UNet 3+,它们都是专为医学图像分割而设计的,并具有表达性能。
Encoder
在模型的整体结构中,作者使用U型架构。对于编码器,使用 Swin Transformer 提取特征。如下图所示,将输入的医学图像首先分割成 H s × H s \frac{H}{s}×\frac{H}{s} sH×sH 的非重叠patch,其中s为patch的大小。每个patch被当作一个“ token ”,通过线性嵌入层投射到维度C。由于patch是通过卷积运算得到的,所以这里不需要额外的位置信息。
这些 patch token 被正式送入Swin Transformer,它包含四个阶段,每个阶段包含一定数量的 Swin Transformer Block,包括窗口MSA (W-MSA)和移动窗口MSA (SW-MSA)。为了产生 层次表示 , token 的数量将随着网络的深入而减少;在前三个阶段,输入特征经过 Swin Transformer Block 变换后经过 patch merge layer 降低特征分辨率,增加维数。具体来说, patch merge layer 将 相邻2×2的每一组patch的特征串联起来,然后对所连接的通道维度特征应用一个线性层。这将减少 token 的数量2× 2 = 4,分辨率的2×下采样,输出维数增加2。因此,四个阶段的输出分辨率分别为 H s × H s \frac{H}{s}×\frac{H}{s} sH×sH 、 H 2 s × H 2 s \frac{H}{2s}×\frac{H}{2s} 2sH×2sH、 H 4 s × H 4 s \frac{H}{4s}×\frac{H}{4s} 4sH×4sH 和 H 8 s × H 8 s \frac{H}{8s}×\frac{H}{8s} 8sH×8sH ,维度分别为 C 、 2 C 、 4 C 和 8 C C、2C、4C和8C C、2C、4C和8C。
Decoder
如下图所示,解码器主要由三个阶段组成。与U-Net及其变体不同,模型的每个阶段不仅包括上采样(最近上采样)和跳跃连接,而且还包括 Swin Transformer Block 。具体来说,编码器中第4阶段的输出作为解码器的初始输入。在解码器的每一阶段,将输入特征向上采样2次,然后与同一阶段编码器对应的跳跃连接特征图连接。在那之后,输出被送入 Swin Transformer Block 。我们选择这个设计是因为
- 它可以充分利用编码器和上采样的特性
- 它可以在解码器中建立长期依赖和全局上下文交互,以获得更好的解码性能。
经过以上三个阶段,我们可以得到分辨率为 H 4 × H 4 \frac{H}{4}×\frac{H}{4} 4H×4H 的输出。直接使用4次上采样算子会丢失很多浅层特征,因此,我们通过串联两个块对输入图像进行降采样,得到了分辨率为 H × W H×W H×W和 H 2 × H 2 \frac{H}{2}×\frac{H}{2} 2H×2H的低阶特征,其中每个块包含一个3×3卷积层,一组归一化层和ReLU。所有这些输出特征将被用来通过跳跃连接得到最终的掩模预测。

多尺度特征表示
虽然 self-attention 可以有效地建立 patches 之间的长期依赖关系,但对 patch 进行划分时忽略了每个 patch 内部像素级的内在结构特征,从而导致边缘、线等浅层特征信息的丢失。大尺度可以更好地捕获粗粒度特征,而小尺度可以更好地获取细粒度特征。虽然卷积层可以隐式地引入patches之间的位置信息,但是这些信息在每个patch中的像素级上丢失了。在 Crossvit 中,双分支 Transformer 可以在一定程度上缓解上述问题,在图像识别方面取得了比ViT更好的性能。基于此,作者提出了多尺度的Swin Transformer 。具体地说,使用两个独立的分支,其patch size分别为s = 4 (primary)和s = 8 (complementary),在不同的空间层次上进行特征提取。
因此,小规模分支可以得到输出分辨率为 H 4 × H 4 \frac{H}{4}×\frac{H}{4} 4H×4H 、 H 8 × H 8 \frac{H}{8}×\frac{H}{8} 8H×8H 、 H 16 × H 16 \frac{H}{16}×\frac{H}{16} 16H×16H 和 H 32 × H 32 \frac{H}{32}×\frac{H}{32} 32H×32H 。
而大规模分支的输出分辨率为 H 8 × H 8 \frac{H}{8}×\frac{H}{8} 8H×8H 、 H 16 × H 16 \frac{H}{16}×\frac{H}{16} 16H×16H 、 H 32 × H 32 \frac{H}{32}×\frac{H}{32} 32H×32H和 H 64 × H 64 \frac{H}{64}×\frac{H}{64} 64H×64H 。
多尺度特征融合
在获得双分支编码器的输出特征后,如何融合输出特征是多尺度特征表示学习的核心问题。直接的方法是将多尺度特征简单地串接起来,然后进行卷积运算。然而,这种直接的方法无法捕获不同尺度特性之间的长期依赖关系和全局上下文联系。为此,我们提出了一种新的 Transformer交互融合 (Transformer Interactive Fusion,TIF)模块,该模块利用MSA机制实现多尺度特征之间的高效交互。特别地,我们在TIF中选择标准 Transformer Block,而不是 Swin Transformer Block ,主要是因为后者本质上是在基于矩形的特征图上操作,而在多尺度特征融合模块中,我们需要根据一个分支的特征图生成指定大小的 token ,然后与另一个分支重塑的 token 序列一起计算 self-attention 。每个阶段只需要进行两次单层 self-attention 操作,计算复杂度是可以接受的。
如图3所示,本文提出的TIF能够整合两个不同尺度分支的特征。下面我们选择小规模的分支机构进行具体分析,同样的步骤也适用于大型分支机构。
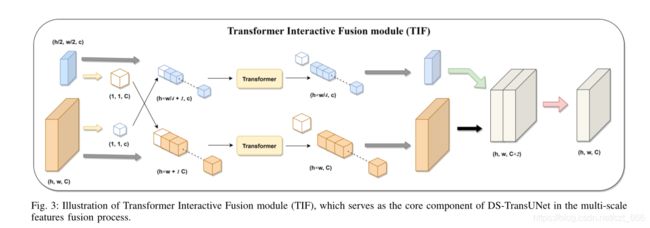
具体来说,对于同一阶段 i ( i = 1 , 2 , 3 , 4 i = 1,2,3,4 i=1,2,3,4)的两个分支的输出,
主支系 F i = [ f 1 i , f 2 i , … , f h × w i ] ∈ R C × ( h × w ) F^i= [f^i_1,f^i_2,…,f^i_{h×w}]∈\mathbb R^{C×(h×w)} Fi=[f1i,f2i,…,fh×wi]∈RC×(h×w),
补充支系 G i = [ g 1 i , g 2 i , … , g h 2 × w 2 i ] ∈ R C × ( h 2 × w 2 ) G^i= [g^i_1, g^i_2,…,g^i_{\frac{h}{2}×\frac{w}{2}}]∈\mathbb R^{C×(\frac{h}{2}×\frac{w}{2})} Gi=[g1i,g2i,…,g2h×2wi]∈RC×(2h×2w)。得到变换输出 G i G^i Gi:
g ^ i = Flatten ( Avgpool ( G i ) ) \hat g^i= \text{Flatten}(\text{Avgpool}(G^i)) g^i=Flatten(Avgpool(Gi))
其中 g ^ i ∈ R C × 1 \hat g^i∈\mathbb R^{C×1} g^i∈RC×1, Avgpool为1维平均池化层,随后进行扁平化操作。 token g ^ i \hat g^i g^i 表示 g i g^i gi在像素级与 F i F^i Fi交互的全局抽象信息。同时, F i F^i Fi与 g ^ i \hat g^i g^i连接成 1 + h × w 1 + h × w 1+h×w 个 token 序列,送入Transformer层进行全局自注意计算:
F i = Transformer ( [ g ^ i , f 1 i , f 2 i , … , f h × w i ] ) , = [ f ^ 0 i , f ^ 1 i , … , f ^ h × w i ] ∈ R C × ( 1 + h × w ) F o u t i = [ f ^ 1 i , f ^ 2 i , … , f ^ h × w i ] ∈ R C × ( h × w ) \begin{aligned} F^i &= \text{Transformer}([\hat g^i, f^i_1, f^i_2,…,f^i_{h×w}]),\\ &= [\hat f^i_0,\hat f^i_1,…,\hat f^i_{h×w}] ∈\mathbb R^{C×(1+h×w)}\\ F^i_{out} &= [\hat f^i_1,\hat f^i_2,…,\hat f^i_{h×w}] ∈\mathbb R^{C×(h×w)} \end{aligned} FiFouti=Transformer([g^i,f1i,f2i,…,fh×wi]),=[f^0i,f^1i,…,f^h×wi]∈RC×(1+h×w)=[f^1i,f^2i,…,f^h×wi]∈RC×(h×w)
其中, F o u t i F^i_{out} Fouti 为小型支路在TIF中的最终输出。该方法引入 F i = [ f 1 i , f 2 i , … , f h × w i ] F^i= [f^i_1,f^i_2,…,f^i_{h×w}] Fi=[f1i,f2i,…,fh×wi]中每个 token 和整个 G i G^i Gi 之间的连接,使得细粒度特征也可以从大尺度分支中获取粗粒度信息。因此,TIF模块可以对多尺度分支进行有效的特征融合,从而获得更好的分割性能。
实验
数据集:
Polyp Segmentation、ISIC 2018 Dataset、GLAS Dataset和2018 Data Science Bowl
评价指标:
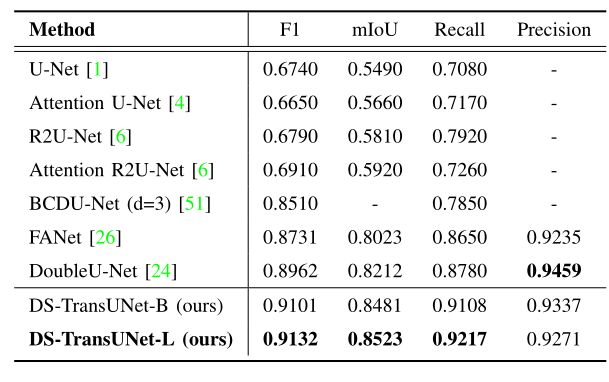
mDice = 2 × T P 2 × T P + F P + F N , mIoU = T P T P + F P + F N , Precision = T P T P + F P , Recall = T P T P + F N \begin{aligned} \text{mDice} &=\frac{2 × TP}{2 × TP + FP + FN},\\ \text{mIoU} &=\frac{TP}{TP + FP + FN},\\ \text{Precision} &=\frac{TP}{TP + FP},\\ \text{Recall} &=\frac{TP}{TP + FN} \end{aligned} mDicemIoUPrecisionRecall=2×TP+FP+FN2×TP,=TP+FP+FNTP,=TP+FPTP,=TP+FNTP