pytorch框架搭建yolov3模型训练自己的数据
前言
之前一直使用tensorflow来实现yolov3,最近学习pytorch框架,就试着用pytorch来搭建yolov3模型,说实话,比tensorflow要麻烦一点。
首先是环境,项目中有requirements.txt文件,可以直接pip install -r requirements.txt安装:
python3.7
matplotlib>=3.2.2
numpy>=1.18.5
opencv-python>=4.1.2
pillow
PyYAML>=5.3
scipy>=1.4.1
tensorboard>=2.2
torch>=1.6.0
torchvision>=0.7.0
tqdm>=4.41.0
制作数据集
一般我们都是使用labelImge标注工具,安装也很简单
pip install PyQt5
pip install pyqt5-tools
pip install lxml
pip install labelImg
然后在cmd中输入labelImg回车
源码下载
下载地址:https://github.com/ultralytics/yolov3
有些源码没有cfg文件夹,可以自己找找或者私信我
数据处理
将训练数据放入data文件夹下,使用常规的文件夹格式,另外新加images和labels文件夹,Annotations中放入xml文件

分割训练集和测试集
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'data/Annotations'
txtsavepath = 'data/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('data/ImageSets/trainval.txt', 'w')
ftest = open('data/ImageSets/test.txt', 'w')
ftrain = open('data/ImageSets/train.txt', 'w')
fval = open('data/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
在ImageSets中会得到相关文件

根目录下,新建voc_label.py,得到labels
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test','val']
classes = ["输入自己的类别"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('data/Annotations/%s.xml' % (image_id))
out_file = open('data/labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('data/labels/'):
os.makedirs('data/labels/')
image_ids = open('data/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('data/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('data/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
labels文件夹下会生成相关文件

配置文件
在data文件夹下新建2007voc.data:
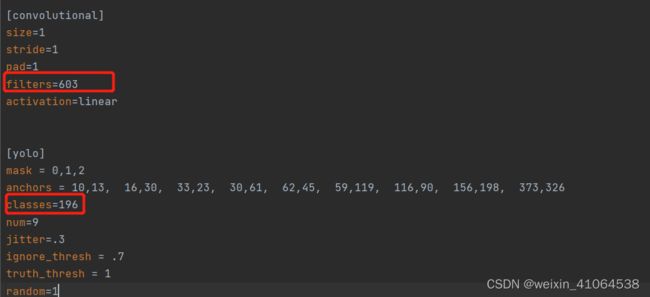
classes=196 #修改 输入自己的数量 记得删除后面的汉字和#号
train=data/train.txt
valid=data/test.txt
names=data/2007voc.names
backup=backup/
eval=coco
在data文件夹下新建2007voc.names,输入检测的类别

修改yolov3.cfg配置文件,也可以使用其他网络结构,比如yolov3-tiny.cfg,修改方式一样

必须修改的部分有两个,总共六处(yolov3-tiny.cfg只有四处),classes改为自己的类别数量,机器classes上面的filters,filter =3*(类别数量 + 5)
权重下载
官网提供的权重文件需要另外转化,比较麻烦,这里我直接提供yolov3和yolov3-tiny两种权重文件,已经上传,可以直接下载使用:
https://download.csdn.net/download/weixin_41064538/82001090
训练
准备工作做完了,现在可以开始训练,需要修改train.py四个地方

直接运行train得到训练模型best.pt

预测
我们将测试数据防止data/samples目录下:
修改detect.py文件

直接运行detect.py,就能在output文件夹下看到输出结果
