联邦学习经典算法总结
看过很多联邦学习分类分割的文章了,现在来个总结吧。
1.FedAvg Communication-Efficient Learning of Deep Networks from Decentralized Data https://arxiv.org/abs/1602.05629
https://arxiv.org/abs/1602.05629
最经典的FL算法
论文里面无收敛分析证明,收敛分析证明需要看这篇文章
关于FedAvg在非IID数据上的趋同
算法:

聚合部分代码:
def average_weights(w):
"""
Returns the average of the weights.
"""
w_avg = copy.deepcopy(w[0])
for key in w_avg.keys():
for i in range(1, len(w)):
w_avg[key] += w[i][key]
w_avg[key] = torch.div(w_avg[key], len(w))
return w_avg代码分析:收集所有客户端的模型,然后将模型进行直接平均。
2.FedProx:在FedAvg局部客户端训练时加上一个近似项(就是加上正则化),目的是对偏离全局模型大的客户端进行惩罚,让参与训练的客户端收到约束。
论文:FEDERATED OPTIMIZATION IN HETEROGENEOUS NETWORKShttps://arxiv.org/abs/1812.06127
github:
tensorflow版本:GitHub - litian96/FedProx:异构网络中的联合优化 (MLSys '20)
pytorch版本:GitHub - ki-ljl/FedProx-PyTorch: PyTorch implementation of FedProx (Federated Optimization for Heterogeneous Networks, MLSys 2020).
参数μ={0.001, 0.01, 0.1, 0.5, 1},参数μ需要调参
论文里面有收敛分析证明。
算法:

客户端局部代码:
proximal_term = 0.0
for w, w_t in zip(model.parameters(), global_model.parameters()):
proximal_term += (w - w_t).norm(2)
loss = loss_function(y_pred, label) + (args.mu / 2) * proximal_term服务器聚合代码:
def aggregation(self, index):
s = 0
for j in index:
# normal
s += self.nns[j].len
params = {}
for k, v in self.nns[0].named_parameters():
params[k] = torch.zeros_like(v.data)
for j in index:
for k, v in self.nns[j].named_parameters():
params[k] += v.data * (self.nns[j].len / s)
for k, v in self.nn.named_parameters():
v.data = params[k].data.clone()
3.FedBN: ICLR
FedBN:通过本地批处理规范化对非 IID 特征进行联合学习https://arxiv.org/abs/2102.07623
代码:
GitHub - med-air/FedBN: [ICLR'21] FedBN: 通过本地批处理规范化对非 IID 特征进行联邦学习
FedBN使用局部批次归一化来缓解平均模型之前的特征漂移。
比如医学成像中不同的扫描仪/传感器,自动驾驶(高速公路与城市)中不同的场景分布,其中本地客户端存储具有与其他客户端不同分布的示例,作者认为局部客户端数据在特征空间中的分布存在偏差,并将这种情况定义为特征漂移。由于医院中使用的不同成像机器和协议,例如不同的强度和对比度,图像外观可能会有很大的不同。具体操作就是:使客户端的BN层保持本地更新,而不需要在服务器上进行通信和聚合。

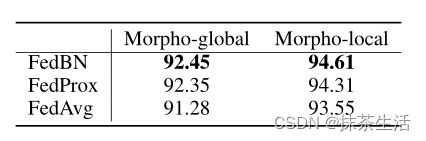
首先这幅图告诉我们,局部无BN的话,模型平均并不能得到一个很好的模型,而当局部有BN时,局部训练误差面变得相似

这幅图告对于一个最优权重w*,改变γ*会恶化该模型,而对于给定的最优BN参数γ*,改变w*也会降低质量。如果同时平均模型和BN参数将会造成较高的泛化误差,所有要将局部参数保留在本地,只平均不带BN参数的模型。
实验结果:

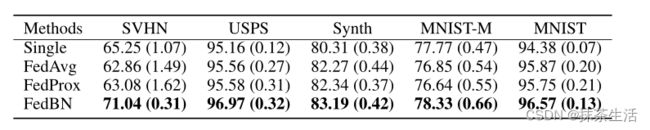

同时实验还进行了外部泛化,如果来自另一个领域的新中心加入训练,我们可以将全局模型的非BN层参数传递到这个新中心。这个新的中心将计算自己的均值和方差统计量,并学习相应的本地BN参数。
算法:

# aggregate params
if args.mode.lower() == 'fedbn':
print("this is fedBN")
for key in server_model.state_dict().keys():
if 'norm' not in key:
temp = torch.zeros_like(server_model.state_dict()[key], dtype=torch.float32)
for client_idx in range(args.node_num):
temp += client_weights[client_idx] * models[client_idx].state_dict()[key]
server_model.state_dict()[key].data.copy_(temp)
for client_idx in range(args.node_num):
models[client_idx].state_dict()[key].data.copy_(server_model.state_dict()[key])
else:
print("this is not fedBN")
for key in server_model.state_dict().keys():
# num_batches_tracked is a non trainable LongTensor and
# num_batches_tracked are the same for all clients for the given datasets
if 'num_batches_tracked' in key:
server_model.state_dict()[key].data.copy_(models[0].state_dict()[key])
else:
temp = torch.zeros_like(server_model.state_dict()[key])
for client_idx in range(len(client_weights)):
temp += client_weights[client_idx] * models[client_idx].state_dict()[key]
server_model.state_dict()[key].data.copy_(temp)
for client_idx in range(len(client_weights)):
models[client_idx].state_dict()[key].data.copy_(server_model.state_dict()[key])4.MOON CVPR
模型对比联邦学习
MOON的核心思想是利用模型表示之间的相似性来纠正个体的局部训练,即在模型级别进行对比学习。它通过最大化当前局部模型学习的表示与全局模型学习的表示的一致性来纠正局部更新。MOON的目的是减少局部模型学习的表示与全局模型学习的表示之间的距离,增加局部模型学习的表示与先前局部模型学习的表示之间的距离。


实验结果:

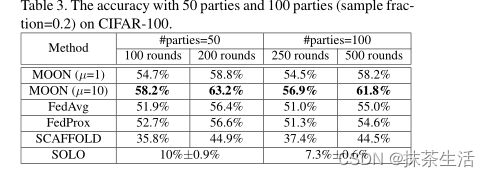
fedProx的超参数设置为μ={0.001, 0.01, 0.1, 0.5, 1},默认一般为0.01