策略梯度算法简明教程
为什么需要策略梯度
基于值的强化学习方法一般是确定性的,给定一个状态就能计算出每种可能动作的奖励(确定值),但这种确定性的方法无法处理一些现实的问题,比如玩100把石头剪刀布的游戏,最好的解法是随机的使用石头、剪刀和布并尽量保证这三种手势出现的概率一样,因为任何一种手势的概率高于其他手势都会被对手注意到并使用相应的手势赢得游戏。

再比如,假设我们需要探索上图中的迷宫拿到钱袋。如果采用基于值的方法,在确定的状态下将得到确定的反馈,因此在使用这种方法决定灰色(状态)方格的下一步动作(左或右)是确定的,即总是向左或向右,而这可能会导致落入错误的循环中(左一白格和左二灰格)而无法拿到钱袋。也许有人要质疑这时的状态不应用一个方格,而是迷宫中的所有方格表示。但是考虑如果我们身处一个巨大的迷宫无法获得整个迷宫的布局信息,如果在相同的可感知的状态下总是做出固定的判断的话,仍然会导致在某个局部原地打转。事实上很多实际问题特别是对弈类问题都有类似的特征,即需要在貌似相同的状态下应用不同的动作,如棋类游戏的开局。
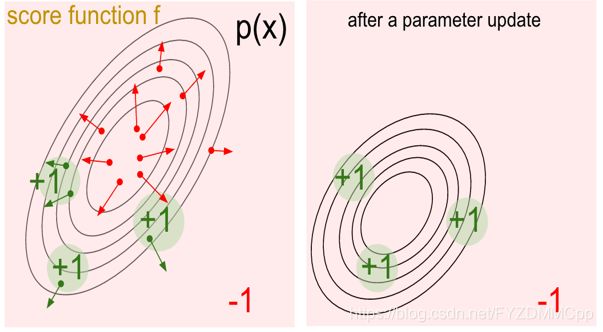
策略梯度正是为了解决上面的问题产生的,它的秘密武器就是“随机”。首先随机能提供非确定的结果,这种非确定的结果并不是完全的随意,而是服从某种概率分布的随机。策略梯度不计算奖励(reward),而是输出选择所有动作的概率分布,然后基于概率选择动作。 其训练的基本原理是通过反馈调整策略,具体来说就是在得到正向奖励时,增加相应的动作的概率;得到负向的奖励时,降低相应动作的概率。下面左图中的绿点表示获得正向奖励的动作,右图表示更新后的策略,可以发现产生正向奖励的区域的概率都增加了(离圆心的距离更近)。
下面我们来具体了解策略梯度算法。
基本概念
对象系统:策略梯度的学习对象,这个对象即可以是一个系统,比如汽车或一个游戏,也可以是一个对手,比如势头剪刀布的游戏对手或者一个职业围棋手。
Policy策略:![]() 表示在状态
表示在状态 和参数
和参数 条件下发生动作
条件下发生动作 的概率。
的概率。
Episode轮次:表示从起始状态开始使用某种策略产生动作与对象系统交互,直到某个终结状态结束。比如在围棋游戏中的一个轮次就是从棋盘中的第一个落子开始直到对弈分出胜负,或者自动驾驶的轮次指从汽车启动一直到顺利抵达指定的目的地,当然撞车或者开进水塘也是种不理想的终结状态。
Trajectory轨迹: 表示在PG一个轮次的学习中,状态、动作和奖励
表示在PG一个轮次的学习中,状态、动作和奖励 的顺序排列。举个栗子:
的顺序排列。举个栗子:![]() 。由于策略产生的是非确定的动作,同一个策略在多个轮次可以产生多个不同的轨迹。
。由于策略产生的是非确定的动作,同一个策略在多个轮次可以产生多个不同的轨迹。
轮次奖励:![]() 表示在一个轮次中依次动作产生的奖励的总和。在实现中,对每个策略评估奖励期望时,会求多个轮次的平均值。
表示在一个轮次中依次动作产生的奖励的总和。在实现中,对每个策略评估奖励期望时,会求多个轮次的平均值。
策略梯度的学习是一个策略的优化过程,最开始随机的生成一个策略,当然这个策略对对象系统一无所知,所以用这个策略产生的动作会从对象系统那里很可能会得到一个负面奖励。为了击败对手,我们需要逐渐的改变策略。策略梯度在一轮的学习中使用同一个策略直到该轮结束,通过梯度上升改变策略并开始下一轮学习,如此往复,直到轮次累计奖励收敛为止。
目标函数
根据上述策略梯度的基本原理,我们可以把它的目标形式化的描述为以下表达式:
![]()
这个函数表示策略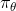 在0到t步累计奖励的期望值。之所以是期望值,是因为每一步的奖励是根据策略(生成动作选择的概率分布)得到的奖励期望;而不是选择一个确定动作,得到确定的奖励。策略梯度的目标就是确定构成策略的参数,使得
在0到t步累计奖励的期望值。之所以是期望值,是因为每一步的奖励是根据策略(生成动作选择的概率分布)得到的奖励期望;而不是选择一个确定动作,得到确定的奖励。策略梯度的目标就是确定构成策略的参数,使得 取得最大的期望值。即:
取得最大的期望值。即:
![]()
策略梯度算法中使用梯度上升来更新参数,根据数学期望的定义:
![]()
求导得:
![]()
这里进行不下去了,由于![]() 依赖于,无法直接求导,因此要使用一个小技巧。根据
依赖于,无法直接求导,因此要使用一个小技巧。根据![]() 进行转换:
进行转换:
![]()
代入得:
![]()
这回求完了,根据期望的定义往回转换,得:
![]()
由于:


可得最终结果:
![\nabla_\theta J(\theta)=E_{\tau \sim \pi_\theta(\tau)}[\sum_{t=1}^{T}\nabla_\theta log\pi_\theta(\alpha_t|s_t)(\sum_{t=1}^{T} r(s_t,\alpha_t))]](http://img.e-com-net.com/image/info8/cac62cf2c15645c8ab9f022bd6b1ce24.gif)
把期望用均值来近似:
![\nabla_\theta J(\theta)=\frac{1}{N}\sum_{i=1}^{N}[\sum_{t=1}^{T}\nabla_\theta log\pi_\theta(\alpha_t|s_t)(\sum_{t=1}^{T} r(s_t,\alpha_t))]](http://img.e-com-net.com/image/info8/c64ca3a443724294924321e1f7f86786.gif)
折腾这么一大顿,终于求完了,这就是要优化的目标函数。即使你没太看懂,也能从这里大概做一个直观理解:奖励高时策略倾向于增加相应动作的概率,奖励低时就减小。策略梯度和传统的监督式学习的学习过程还是比较相似的:每轮次都由前向计算和反向传播构成,前向计算负责计算目标函数,反向传播负责更新算法的参数,依此进行多轮次的学习指导学习效果稳定收敛。唯一不同的是,监督式学习的目标函数相对直接,即目标值和真实值的差,这个差值通过一次前向反馈就能得到;而策略梯度的目标函数源自轮次内所有得到的奖励,并且需要进行一定的数学转换才能计算,另外由于用抽样模拟期望,也需要对同一套参数进行多次抽样来增加模拟的准确性。
应用实例
下面我们通过一个实例介绍如何应用PG解决具体问题:学习玩Atari PONG游戏。 PONG是一个模拟打乒乓球的游戏,玩家控制屏幕一侧的一小块平面模拟乒乓球拍上下移动来击球。如果迫使对方失球则己方一侧的得分加一,反之对方得分。使用策略梯度学习PONG游戏的基本思路是使用算法控制的一方与游戏控制的另一方进行对弈,通过观察游戏状态以及比分变化调整动作(向上或向下)的概率分布,使本方得分最大化。学习的过程可以写成以下代码:
policy = build_policy_model()
game.start()
while True:
state = game.currentState()
action, prob = policy.feedforward(state)
reward = game.play(action)
trajectory.append((state, prob, action, reward))
if game.terminated():
if count < SAMPLE_COUNT:
trajectories.append(trajectrory)
trojectroy = []
count += 1
break
else:
policy.backpropagation(trajectories)
game.restart()
trajectory = []
trajectories = []
count = 0第 1 行构造一个策略模型并随机的初始化模型的参数。模型的功能是通过前向反馈由状态信息计算出所有动作的概率分布,例如(向上 90%,向下 10%),并选取概率最大的动作发给游戏作为指令。
第 2 行开始游戏。
第 4 行获得当前的状态,如球拍的位置和球的移动速度方向信息。
第 5 行将状态信息传入策略模型计算相应的动作。这里还要记录动作的概率![]() ,这是为了在反向阶段计算目标函数导数。
,这是为了在反向阶段计算目标函数导数。
第 6 行使用 4 计算出的动作进行游戏并获得奖励
第 7 行将一轮的交互信息(状态,动作概率,动作和奖励)存入当前轨迹中
第 8 行如果游戏未结束(乒乓球还在被双方击打中)则继续使用当前的策略模型进行下一步的交互。
第 10 行如果游戏结束(一方未击中乒乓球)则保存上一轮轨迹信息并使用相同的策略模型开始新一轮的游戏,也就是为了降低个体差异的影响,为同一个策略模型生成多个样本。
第 15 行产生足够的样本以后,通过策略模型的反向传递进行参数的更新,再用更新后的策略开始新一轮次的学习
问题和改进
虽然策略梯度理论上能处理基于值的方法无法处理的复杂问题,但由于依赖样本来优化策略,导致这种方法受样本个体差异影响有比较大的方差,学习的效果不容易持续增强和收敛。一个基本的改进思路是通过减少无效的元素来降低方差,由于当前的动作不会对过去的奖励产生影响,因此可以将目标函数改为:
![\nabla_\theta J(\theta)=\frac{1}{N}\sum_{i=1}^{N}[\sum_{t=1}^{T}\nabla_\theta log\pi_\theta(\alpha_t|s_t)(\sum_{t^{'}=t}^{T} r(s_{t^{'}},\alpha_{t^{'}}))]](http://img.e-com-net.com/image/info8/c78db478ff74438fb7d3a262d52b48c0.gif)
还可以用经典的折扣系数来降低距离较远动作带来的影响:
![\nabla_\theta J(\theta)=\frac{1}{N}\sum_{i=1}^{N}[\sum_{t=1}^{T}\nabla_\theta log\pi_\theta(\alpha_t|s_t)(\sum_{t^{'}=t}^{T} \gamma ^{|t-t^{'}|}r(s_{t^{'}},\alpha_{t^{'}}))]](http://img.e-com-net.com/image/info8/374f2974cc084b858f201772ffb742a8.gif)
另外我们还需要考虑一个问题:实际计算中产生的轮次奖励并不能准确代表这个策略的好坏程度,比如当策略已经较好时,使用一个不太好的样本生成了较小的轮次奖励,由于这个奖励非负,传统的策略梯度算法仍然尝试增加产生这个轨迹的动作的概率,从而导致学习效果不升反降。所以我们需要引入一个基准值(baseline value),使得算法能够增加优于基准值的动作的概率,降低低于基准值动作的概率,即:
![\nabla_\theta J(\theta)=\frac{1}{N}\sum_{i=1}^{N}[\sum_{t=1}^{T}\nabla_\theta log\pi_\theta(\alpha_t|s_t)(\sum_{t^{'}=t}^{T} r(s_{t^{'}},\alpha_{t^{'}})-b)]](http://img.e-com-net.com/image/info8/f56fd5cca8cf4513a87ed77c47946beb.gif)
基准值 目前一般常取的是均值,即
目前一般常取的是均值,即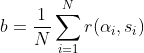 。可以看出,这个基准值也是随着更新动态变化的。研究人员们还在尝试用其他方法生成更好的基准值,其实如果你仔细想一下就会发现,对基准值的动态估计其实就是值函数的估计问题。因此,策略梯度算法可以和基于值的算法相结合,以实现更好的效果。比如Actor-critic,在我看来其实就是策略梯度法和DQN的一种结合,这个我们以后有机会再聊吧~
。可以看出,这个基准值也是随着更新动态变化的。研究人员们还在尝试用其他方法生成更好的基准值,其实如果你仔细想一下就会发现,对基准值的动态估计其实就是值函数的估计问题。因此,策略梯度算法可以和基于值的算法相结合,以实现更好的效果。比如Actor-critic,在我看来其实就是策略梯度法和DQN的一种结合,这个我们以后有机会再聊吧~