推荐系统从入门到入门(2)——简单推荐系统构建(无框架、Tensorflow)
本系列博客总结了不同框架、不同算法、不同界面的推荐系统,完整阅读需要大量时间(又臭又长),建议根据目录选择需要的内容查看,欢迎讨论与指出问题。
目录
系列文章梗概
系列文章目录
3.基于协同过滤的系统构建
3.1.2 预构建
3.1.3 系统构建
3.2 基于矩阵分解的协同过滤电影推荐系统
3.2.1 原理与系统设计
3.2.2 优化问题求解
3.2.3 系统构建(无框架)
3.2.4 系统构建(Tensorflow)
3.2.5 原理补充
3.2.6 效果对比
系列文章梗概
本次大作业主要是以电影推荐系统为例,介绍并实践不同框架下推荐系统的构建。在问题背景介绍部分,首先从推荐算法与关联分析引入,通过推荐系统的动机、架构、评估、应用详解了推荐系统,并对电影推荐系统做了定义与数据集介绍。在推荐系统的算法部分,先分类综述了推荐算法,随后详解了不同类型的协同过滤算法并在本地不同框架下做了推荐实践。在MapReduce部分,首先通过背景与全流程详解了MapReduce的原理,并通过WordCount实现了配置与简单应用,后续完成了基于MapReduce的电影推荐系统构建。在Spark部分,首先通过生态与全流程详解了Spark的原理,后续完成了基于Spark的电影推荐系统。在对比分析部分,分别从原理、数据处理方式、性能等对比MapReduce与Spark框架,并基于两个构建出的推荐系统做性能对比验证,并总结了两种框架的优缺点与选择标准与依据。在方法补充与实践部分,拓展了协同过滤之外的其他推荐算法并实际构建出了对应的电影推荐系统。在系统界面构建部分,简述了系统界面的设计,详解了不同框架、不同数据集下的数据可视化,并分别在Web、APP、Uni-app上构建了相对完整的电影推荐系统,在总结部分,对一些实验趣事与结论进行了补充。参考部分根据类别划分,汇总了本次实验的参考文献与资料。
系列文章目录
第一章 推荐系统从入门到入门(1)——推荐系统综述与协同过滤_@李忆如的博客-CSDN博客
第二章 推荐系统从入门到入门(2)——简单推荐系统构建(无框架、Tensorflow)
3.基于协同过滤的系统构建
在了解协同过滤的相关概念、原理、流程后,在本部分将实践构建基于不同原理的协同过滤电影推荐系统(不同框架、数据可视化、Web应用在后文介绍与构建),以基于用户与基于矩阵分解的协同过滤电影推荐系统为例。
3.1 基于用户的协同过滤电影推荐系统
3.1.1 原理与系统设计
在2.2与2.2.1中对基于用户的协同过滤算法做了简介,其核心是根据用户之间的评分行为相似度预测用户评分。对于本实验特定任务(电影推荐),核心即为找到与推荐用户相似的用户,并参考他/她的喜好与评价进行推荐,原理可视化为图16所示:

图16 基于用户的协同过滤电影推荐原理
在系统构建前,先对相关实现进行设计,总结如表11:
表11 基于用户的协同过滤电影推荐系统实现设计
| 数据集 |
MovieLens Latest Datasets(ml-latest-small) |
| 框架与环境 |
无框架、本地Pycharm |
| 相似度度量 |
余弦相似度 |
3.1.2 预构建
在了解完相关原理,设计好了系统后,在本部分对系统进行预构建及解析。
在构建前对数据集做介绍,如表11所示,本次实验测试使用的是MovieLens Latest Datasets(ml-latest-small),是MovieLens的一个小数据子集,形式上与MovieLens保持一致(包含用户与电影信息与评价)。具体来说,在该电影系统中使用了610个用户为9742部电影打分,生成了100836行的数据集。本次使用数据包括:movies.csv和ratings.csv,部分数据展示如图17所示:
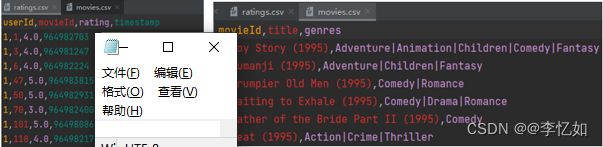
图17 测试数据展示
如表11所示,本次实验测试使用的相似度度量指标是余弦相似度,在2.2.2(2)中有定义,根据式6去编写度量函数评估用户间的相似度,代码如图18所示:

图18 余弦相似度代码
Tips:为统一样式,本报告代码图片均在Carbon | Create and share beautiful images of your source code渲染,风格为Seti。
至此,本系统的介绍与准备全部结束,可以正式开始系统的构建。
3.1.3 系统构建
在本实验中,无框架的基于用户的协同过滤电影推荐系统构建步骤总结如表12:
表12 无框架的基于用户的协同过滤电影推荐系统构建步骤
| 输入: 电影数据集(主要使用:movies.csv和ratings.csv) |
| 过程: |
| 1、数据读取:读取文件,保存评分结果 |
| 2、生成评分列表:根据电影和评分列表数据生成每个用户对看过的电影的评分列表 |
| 3、生成评分矩阵:生成单个用户对所有电影的评分矩阵 |
| 4、推荐:对于选取用户,找出相似用户,根据规则产生推荐 |
| 5、系统构建(后文详解):数据可视化,搭建Web服务(or APP or uni-app) |
| 输出:电影推荐列表 |
(1)数据读取
本实验测试中,数据集重要信息保存在movies.csv和ratings.csv,故编写read_movies与read_userRating两个函数去对应读取数据,用list二维列表保存电影和用户对电影的评分结果,行表示电影和用户对电影的评分,列为电影的属性和评分结果,用movies,ratings分别存储两个函数返回的结果。在实现上,核心是数据遍历+csv分解,代码如图19所示:
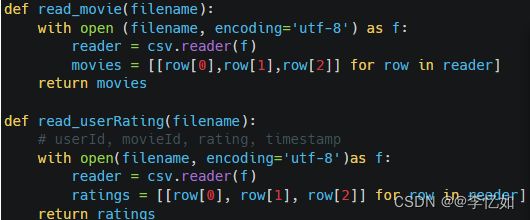
图19 数据读取代码
(2)评分列表生成
由于本部分实验系统基于用户,故因生成每个用户看过的电影的评分列表(根据(1)读入的数据,即电影与评分列表)。在实现上,核心是遍历+01判断(是否看过此电影),代码如图20所示,评分列表部分展示如图21所示:

图20 评分列表生成代码

图21 评分列表展示
(3)评分矩阵生成
由协同过滤简介(2.1)中所述可知,用户-评分矩阵是相似度度量所需的重要数据,所以在生成评分列表后,要对应构建每个用户对所有电影的评分矩阵,核心为遍历+判断赋值(有评分的在矩阵里赋值,无评分赋0,与矩阵定义保持一致),代码如图22所示,部分评分矩阵展示(以输入用户id=50为例)如图23所示:
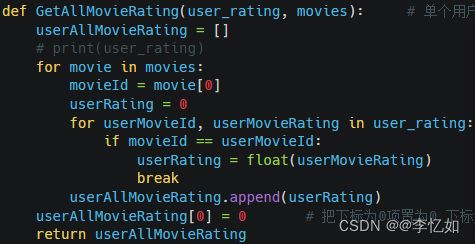
图22 评分矩阵生成代码

图23 部分评分矩阵展示
Tips:一行为一个用户对所有电影的评分矩阵(第一行为被推荐用户)。
(4)推荐
成功读取数据,生成评分列表与评分矩阵后,进入推荐系统的核心——推荐,由2.2.2所述,推荐的核心则是相似度度量。在本测试实验中以推荐用户id=50,topn中n=10为例详解推荐过程。
本测试实验代码实现逻辑为:根据每个用户的评分向量(矩阵)求该用户与目标用户的余弦相似度。用列表保存每个用户的id和该用户与目标用户余弦相似度结果,根据余弦相似度结果排序,选取topn个用户。并用这n个用户的id再一次生成他们对所有电影的评分矩阵,用它们的余弦相似度求和并开平方,方便后面计算推荐电影评分。
核心代码如图24所示,余弦相似度部分数据展示如图25所示,推荐评分结果部分数据展示如图26所示,针对本样例(id=50,topn中n=10)的推荐结果如图27所示:

图24 无框架基于用户的协同过滤推荐核心代码

图25 余弦相似度部分数据展示
分析:由图25所示,本地输出了每一个用户与被推荐用户的(余弦)相似度,根据相似度去推荐电影是推荐的核心,也是推荐原理可视化的一种解释。
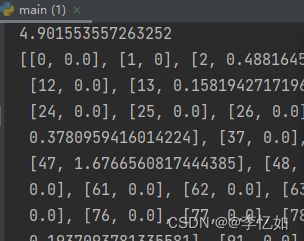
图26 部分推荐评分展示
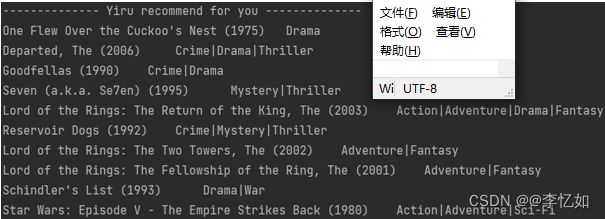
图27 电影推荐样例
Tips:Yiru是个人程序水印。
分析:如图27所示,本测试实验设计的无框架的基于用户的协同过滤推荐系统算法模块可以成功运行(数据可视化、系统模块等后文详解搭建),验证了设计与程序实现的合理性与正确性。
(5)系统评估
对本测试实验的设计与实现进行性能评估,首先在程序中引入time类,使用perf_counter方法记录实验耗时,在ml-latest-small将推荐进行20次,记录平均运行时间为25.414s。
本部分测试方法相对性能较差,对环境、设计与实现进行多维分析,总结主要原因如下:
- 环境上,使用本地CPU环境,且无计算框架,算力不足,难以处理大数据问题。
- 设计上,指标单一,数据量小,系统模型效果有待评估与优化。
- 实现上,反复使用遍历,时间复杂度高,随数据量增大效率将大大降低。
至此,无框架的基于用户的协同过滤电影推荐系统构建与分析完成,后续将探究不同语言、不同框架下不同协同过滤方式的电影推荐系统的构建,核心流程与代码逻辑与本部分相似,故代码仅作核心部分或有差异展示,避免赘述。
(6)完整代码
完整代码如下:
import math
import csv
import time
def read_movie(filename):
with open(filename, encoding='utf-8') as f:
reader = csv.reader(f)
movies = [[row[0], row[1], row[2]] for row in reader]
return movies
def read_userRating(filename):
# userId, movieId, rating, timestamp
with open(filename, encoding='utf-8')as f:
reader = csv.reader(f)
ratings = [[row[0], row[1], row[2]] for row in reader]
return ratings
def ratingsArray(movies, ratings): # 生成评分矩阵
user_rating_array = []
number = 0
user_rating_list = []
for userRating in ratings: # 建立用户的评分列表集合
if str(number) == userRating[0]:
user_rating_list.append([userRating[1], userRating[2]])
# print(number,userRating[0],userRating[1], userRating[2])
else:
user_rating_array.append([number, user_rating_list])
# print(number, user_rating_list)
user_rating_list = []
number = number + 1
user_rating_list.append([userRating[1], userRating[2]])
user_rating_array.append([number, user_rating_list]) # 添加最后一个
# print(user_rating_array)
return user_rating_array
def CosSimilarity(UserId, user_rating_list, movies):
# test_rating_list = user_rating_list[UserId][1]
testAllMovieRating = GetAllMovieRating(user_rating_list[UserId][1], movies)
print(UserId, testAllMovieRating)
# print(test_rating_list)
# print(len(user_rating_list)) # 611个,包含下标0
resCos = []
for id in range(len(user_rating_list)):
if id == UserId or id == 0:
continue
userAllMovieRating = GetAllMovieRating(user_rating_list[id][1], movies)
# print(id, userAllMovieRating)
# 计算余弦相似度
Cos = CosFunction(testAllMovieRating, userAllMovieRating)
resCos.append([id, Cos])
print(resCos)
# key=(lambda x:x[1]),reverse=True
res1 = sorted(resCos, key=(lambda x: x[1]), reverse=True) # 取前10个与目标用户相似的用户
res1 = res1[:10]
print(res1)
# 求前20个用户的所有电影评分矩阵
res1AllMovieRating = []
for item in res1:
userAllMovieRating = GetAllMovieRating(user_rating_list[item[0]][1], movies)
print(item[0], userAllMovieRating)
res1AllMovieRating.append([item[0], userAllMovieRating])
# 前20个用户的Cos余弦相似度求和
sum2 = 0
for i in range(len(res1)):
sum2 = sum2 + math.sqrt(res1[i][1])
# sum2 = math.sqrt(sum2)
print(sum2)
# 求所有电影对目标用户的推荐评分,目标用户看过的电影推荐评分设置为0
MovieRecommend = []
for i in range(len(testAllMovieRating)):
recommend = 0
sum1 = 0
for j in range(len(res1)):
sum1 = sum1 + res1[j][1] * float(res1AllMovieRating[j][1][i])
recommend = sum1 / sum2
if testAllMovieRating[i] != 0:
recommend = 0
MovieRecommend.append([i, recommend])
print(MovieRecommend)
MovieTop = sorted(MovieRecommend, key=(lambda x: x[1]), reverse=True) # 根据推荐评分对电影排序
print(MovieTop)
Recommend = MovieTop[:10]
print(Recommend)
return Recommend
def CosFunction(test, user): # 计算两用户之间余弦相似度
sum1 = 0
sum2 = 0
sum3 = 0
for i in range(len(test)):
sum1 = sum1 + test[i] * user[i]
sum2 = sum2 + math.pow(test[i], 2)
sum3 = sum3 + math.pow(user[i], 2)
CosTotal = sum1 / (math.sqrt(sum2)
* math.sqrt(sum3))
# print(CosTotal)
return CosTotal
def GetAllMovieRating(user_rating, movies): # 单个用户对九千多部电影的评分矩阵
userAllMovieRating = []
# print(user_rating)
for movie in movies:
movieId = movie[0]
userRating = 0
for userMovieId, userMovieRating in user_rating:
if movieId == userMovieId and userMovieRating != 'rating':
# print(userMovieRating)
userRating = float(userMovieRating)
break
userAllMovieRating.append(userRating)
userAllMovieRating[0] = 0 # 把下标为0项置为0 下标为0不代表是电影
return userAllMovieRating
def RecommendMovies(movies, recommend):
print("-------------- Yiru recommend for you --------------")
for item, item2 in recommend:
print(movies[item][1], '\t', movies[item][2])
if __name__ == '__main__':
start = time.perf_counter()
movies = read_movie('movies.csv')
ratings = read_userRating('ratings.csv')
user_rating_list = ratingsArray(movies, ratings)
recommend = CosSimilarity(50, user_rating_list, movies)
RecommendMovies(movies, recommend)
end = time.perf_counter()
print("运行耗时", end - start)
3.2 基于矩阵分解的协同过滤电影推荐系统
3.2.1 原理与系统设计
在2.3.2中对基于矩阵分解的协同过滤算法做了简介,其核心是利用用户-项目评分矩阵(图12)预测用户对项目的评分。对于本实验特定任务(电影推荐),核心即为通过模型最小化观众-电影矩阵构成的损失函数,并根据训练好的模型进行推荐,原理可视化为图28所示:

图28 基于矩阵分解的协同过滤电影推荐原理
在系统构建前,先对相关实现进行设计,总结如表13:
表13 基于矩阵分解的协同过滤电影推荐系统实现设计
| 数据集 |
MovieLens Latest Datasets(ml-latest-small) |
| 框架与环境 |
Tensoerflow(非必要)、本地Pycharm |
| 模型评估 |
平方差损失函数 |
3.2.2 优化问题求解
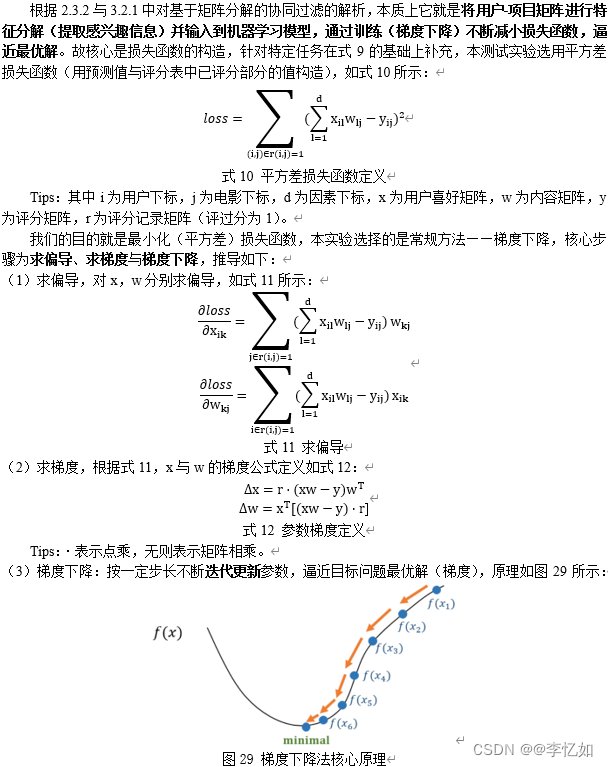
若使用基于矩阵分解,实际上该问题(电影推荐)就变成一个机器学习问题,故最重要的部分就是优化问题的求解(如何最小化损失函数),故本部分根据其原理对优化问题及求解进行推导。
3.2.3 系统构建(无框架)
在了解原理与系统设计,推导了优化问题求解过程后,正式进入系统构建,本实验以无框架与有框架的两种基于矩阵分解的协同过滤电影推荐系统构建来探究同方法不同框架(系统)的影响与效果对比。
本部分先介绍无框架的系统构建,步骤总结在表14:
表14 无框架的基于矩阵分解的协同过滤电影推荐系统构建步骤
| 输入: 电影数据集(主要使用:movies.csv和ratings.csv) |
| 过程: |
| 1、数据读取:读取文件,保存评分结果 |
| 2、初始化:将需要构建的矩阵随机初始化,构造损失函数,初始化矩阵参数梯度 |
| 3、梯度下降:利用梯度下降不断更新参数 |
| 4、评分与预测:利用喜好矩阵与内容矩阵得到预测评分,根据评分进行推荐 |
| 5、系统构建(后文详解):数据可视化,搭建Web服务(or APP or uni-app) |
| 输出:电影推荐列表 |
在数据读取、遍历、初始化等操作中代码逻辑与基于用户的协同过滤类似,在3.1.3中有详解,在本部分仅做核心代码解析。
(1)损失函数
本测试实验是基于矩阵分解,在Python中多维数组与矩阵运算相关函数定义在numpy库中,是本部分最重要的库,详细用法可见:NumPy。
如式10所示,本实验选择平方差损失函数,代码实现如图30所示:

图30 损失函数代码
(2)梯度与梯度下降
本测试实验中梯度推导如式12,故根据其定义在代码上定义梯度,并根据梯度下降原理去编写梯度下降代码,如图31所示:

图31 梯度定义及梯度下降实现代码
(3)评分与推荐
在梯度下降结束后,得到用户对电影的评分,根据topn原则进行排序后推荐,评分与推荐的核心代码如图32所示,电影推荐样例(以用户id=50,topn中n=10为例)如图33所示:
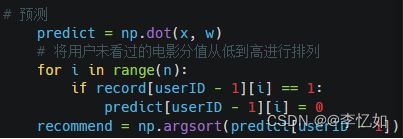
图33 评分与推荐核心代码

图34 电影推荐样例
分析:如图34所示,本测试实验设计的无框架的基于矩阵分解的协同过滤推荐系统算法模块可以成功运行(数据可视化、系统模块等后文详解搭建),验证了设计与程序实现的合理性与正确性。
(4)完整代码
完整代码如下:
# -*- coding: utf-8 -*-
import warnings
warnings.filterwarnings("ignore")
import pandas as pd
import numpy as np
import time
# 获取数据
ratings_df = pd.read_csv('real_ratings.csv')
movies_df = pd.read_csv('movies.csv')
userNo = max(ratings_df['userId']) + 1
movieNo = max(ratings_df['movieRow']) + 1
# 创建电影评分表
rating = np.zeros((userNo, movieNo))
for index, row in ratings_df.iterrows():
rating[int(row['userId']), int(row['movieRow'])] = row['rating']
def recommend(userID, lr, alpha, d, n_iter, data):
'''
userID(int):推荐用户ID
lr(float):学习率
alpha(float):权重衰减系数
d(int):矩阵分解因子(即元素个数)
n_iter(int):训练轮数
data(ndarray):用户-电影评分矩阵
'''
# 获取用户数与电影数
m, n = data.shape
# 初始化参数
x = np.random.uniform(0, 1, (m, d))
w = np.random.uniform(0, 1, (d, n))
# 创建评分记录表,无评分记为0,有评分记为1
record = np.array(data > 0, dtype=int)
# 梯度下降,更新参数
for i in range(n_iter):
x_grads = np.dot(np.multiply(record, np.dot(x, w) - data), w.T)
w_grads = np.dot(x.T, np.multiply(record, np.dot(x, w) - data))
x = alpha * x - lr * x_grads
w = alpha * w - lr * w_grads
# 预测
predict = np.dot(x, w)
# 将用户未看过的电影分值从低到高进行排列
for i in range(n):
if record[userID - 1][i] == 1:
predict[userID - 1][i] = 0
recommend = np.argsort(predict[userID - 1])
a = recommend[-1]
b = recommend[-2]
c = recommend[-3]
d = recommend[-4]
e = recommend[-5]
a1 = recommend[-6]
b1 = recommend[-7]
c1 = recommend[-8]
d1 = recommend[-9]
e1 = recommend[-10]
print('-------- Yiru recommend for you--------\n1:%s\n2:%s\n3:%s\n4:%s\n5:%s\n6:%s\n7:%s\n8:%s\n9:%s\n10:%s。' \
% (movies_df['title'][a], movies_df['title'][b], movies_df['title'][c], movies_df['title'][d],
movies_df['title'][e], movies_df['title'][a1], movies_df['title'][b1], movies_df['title'][c1],
movies_df['title'][d1],
movies_df['title'][e1]))
start = time.perf_counter()
recommend(172, 1e-4, 0.999, 20, 100, rating)
end = time.perf_counter()
print("耗时:", end - start)
3.2.4 系统构建(Tensorflow)
本部分介绍基于Tensorflow的系统构建,步骤总结在表15:
表15 基于矩阵分解的协同过滤电影推荐系统(Tensorflow)构建步骤
| 输入: 电影数据集(主要使用:movies.csv和ratings.csv) |
| 过程: |
| 1、数据读取与处理:读取文件,清洗数据,划分训练测试集 |
| 2、初始化:创建电影评分矩阵rating和评分记录矩阵record |
| 3、模型构建:根据相关矩阵与目标函数构建模型 |
| 4、训练与评估:训练模型,根据损失函数值等指标评估效果 |
| 5、推荐:使用训练好的模型,对指定用户进行电影推荐 |
| 6、系统构建(后文详解):数据可视化,搭建Web服务(or APP or uni-app) |
| 输出:电影推荐列表 |
下面对基于Tensorflow的系统构建的核心代码与效果进行展示与解析。
(1)数据处理
在本测试实验中对movies.csv和ratings.csv进行了简单处理,生成了moviesProcessed.csv,便于后续模型使用,初始化与处理后数据样式样例如图35所示:
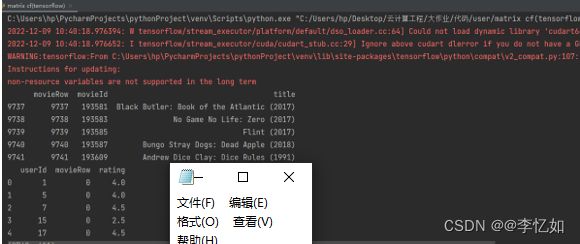
图35 初始化与数据处理效果样例
(2)模型构建
本测试实验模型主要信息来源于评分矩阵rating和评分记录矩阵record,构建核心为参数设置与损失函数定义等,代码如图36所示:

图36 模型构建核心代码
(3)训练与评估
在本测试实验中,模型的训练主要使用tensorflow中的summary方法,用法详见:Module: tf.summary | TensorFlow v2.11.0 (google.cn)。设置迭代次数阈值或损失函数阈值等条件停止训练输出模型,使用损失函数值errors评估模型,代码如图37所示:
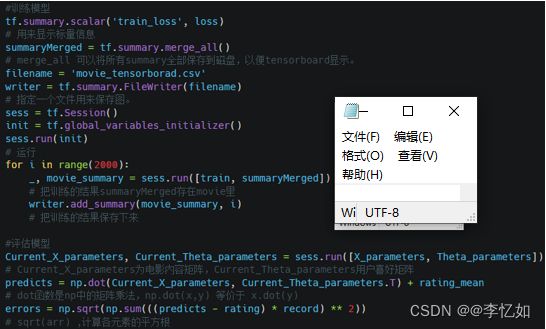
图37 模型训练与评估核心代码
(4)推荐
在得到评估结果达到要求的模型后,可使用模型对对应用户进行电影推荐,样例(以用户id=50,topn中n=10为例)如图38所示:

图38 电影推荐样例
分析:如图38,本部分设计的基于矩阵分解的协同过滤推荐系统(Tensorflow)算法模块可以成功运行(数据可视化、系统模块等后文详解搭建),验证了设计与程序实现的合理性与正确性。
(5)完整代码
完整代码如下:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 改进:要划分训练集和测试集,并在进行模型评估阶段,可参考之前做过的协同过滤推荐系统中的,
# 通过prediction[ground_truth.nonzero()]来筛选只考虑测试数据集中的预测评分
import pandas as pd
import numpy as np
# import tensorflow as tf
import tensorflow._api.v2.compat.v1 as tf
tf.disable_v2_behavior()
# 第一步:------------------------收集和清洗数据
ratings_df = pd.read_csv('ratings.csv')
# print(ratings_df.tail())
# tail命令用于输入文件中的尾部内容。tail命令默认在屏幕上显示指定文件的末尾5行。
# 相对应的有:ratings_df.head()
movies_df = pd.read_csv('movies.csv')
movies_df['movieRow'] = movies_df.index
# 生成一列‘movieRow’,等于索引值index
# print(movies_df.tail())
movies_df = movies_df[['movieRow', 'movieId', 'title']]
# 筛选三列出来
movies_df.to_csv('moviesProcessed.csv', index=False, header=True, encoding='utf-8')
# 生成一个新的文件moviesProcessed.csv
print(movies_df.tail())
ratings_df = pd.merge(ratings_df, movies_df, on='movieId')
# print(ratings_df.head())
ratings_df = ratings_df[['userId', 'movieRow', 'rating']]
# 筛选出三列
ratings_df.to_csv('ratingsProcessed.csv', index=False, header=True,
encoding='utf-8')
# 导出一个新的文件ratingsProcessed.csv
print(ratings_df.head())
# 第二步:-----------------------创建电影评分矩阵rating和评分纪录矩阵record
userNo = ratings_df['userId'].max() + 1
# userNo的最大值
movieNo = ratings_df['movieRow'].max() + 1
# movieNo的最大值
rating = np.zeros((movieNo, userNo))
print(rating.shape)
# 创建一个值都是0的数据
flag = 0
ratings_df_length = np.shape(ratings_df)[0]
print(np.shape(ratings_df))
# 查看矩阵ratings_df的第一维度是多少
for index, row in ratings_df.iterrows():
# interrows(),对表格ratings_df进行遍历
# rating[int(row['movieRow']), int(row['userId'])] = row['rating']
# 等价于:
rating[int(row['movieRow'])][int(row['userId'])] = row['rating']
# 在rating表里的'movieRow'行和'userId'列处,填上row的‘评分’,即ratings_df对应的评分
flag += 1
# if (ratings_df_length-flag) % 5000 == 0:
# print(u'还剩多少待处理:%d' %(ratings_df_length-flag))
# print(rating[3][450])
record = rating > 0
record = np.array(record, dtype=int)
print(record)
# 第三步:----------------------------构建模型
def normalizeRatings(rating, record):
m, n = rating.shape
# m代表电影数量,n代表用户数量
rating_mean = np.zeros((m, 1))
# 每部电影的平均得分
rating_norm = np.zeros((m, n))
# 处理过的评分
for i in range(m):
idx = (record[i, :] != 0)
# 每部电影的评分,[i,:]表示每一行的所有列
rating_mean[i] = np.mean(rating[i, idx])
# 第i行,评过份idx的用户的平均得分
# np.mean() 对所有元素求均值
rating_norm[i, idx] = rating[i, idx] - rating_mean[i]
# rating_norm = 原始得分-平均得分
return rating_norm, rating_mean
rating_norm, rating_mean = normalizeRatings(rating, record)
rating_norm = np.nan_to_num(rating_norm)
# 对值为NaNN进行处理,改成数值0
# print(rating_norm)
rating_mean = np.nan_to_num(rating_mean)
# 对值为NaNN进行处理,改成数值0
# print(rating_mean)
# 构建模型
num_features = 12
X_parameters = tf.Variable(tf.random.normal([movieNo, num_features], stddev=0.35))
Theta_parameters = tf.Variable(tf.random.normal([userNo, num_features], stddev=0.35))
# tf.Variables()初始化变量
# tf.random_normal()函数用于从服从指定正太分布的数值中取出指定个数的值,mean: 正态分布的均值。stddev: 正态分布的标准差。dtype: 输出的类型
loss = 1 / 2 * tf.reduce_sum(
((tf.matmul(X_parameters, Theta_parameters, transpose_b=True) - rating_norm) * record) ** 2) + \
0.5 * (1 / 2 * (tf.reduce_sum(X_parameters ** 2) + tf.reduce_sum(Theta_parameters ** 2)))
# 基于内容的推荐算法模型
train = tf.train.AdamOptimizer(1e-3).minimize(loss)
# https://blog.csdn.net/lenbow/article/details/52218551
# Optimizer.minimize对一个损失变量基本上做两件事
# 它计算相对于模型参数的损失梯度。
# 然后应用计算出的梯度来更新变量。
# 第四步:------------------------------------训练模型
# tf.summary的用法 https://www.cnblogs.com/lyc-seu/p/8647792.html
tf.summary.scalar('train_loss', loss)
# 用来显示标量信息
summaryMerged = tf.summary.merge_all()
# merge_all 可以将所有summary全部保存到磁盘,以便tensorboard显示。
filename = 'movie_tensorborad.csv'
writer = tf.summary.FileWriter(filename)
# 指定一个文件用来保存图。
sess = tf.Session()
# https://www.cnblogs.com/wuzhitj/p/6648610.html
init = tf.global_variables_initializer()
sess.run(init)
# 运行
for i in range(2000):
_, movie_summary = sess.run([train, summaryMerged])
# 把训练的结果summaryMerged存在movie里
writer.add_summary(movie_summary, i)
# 把训练的结果保存下来
# 第五步:-------------------------------------评估模型
Current_X_parameters, Current_Theta_parameters = sess.run([X_parameters, Theta_parameters])
# Current_X_parameters为电影内容矩阵,Current_Theta_parameters用户喜好矩阵
predicts = np.dot(Current_X_parameters, Current_Theta_parameters.T) + rating_mean
# dot函数是np中的矩阵乘法,np.dot(x,y) 等价于 x.dot(y)
errors = np.sqrt(np.sum(((predicts - rating) * record) ** 2))
# sqrt(arr) ,计算各元素的平方根
print(u'模型评估errors:', errors)
# 第六步:--------------------------------------构建完整的电影推荐系统
user_id = input(u'您要想哪位用户进行推荐?请输入用户编号:')
sortedResult = predicts[:, int(user_id)].argsort()[::-1]
# argsort()函数返回的是数组值从小到大的索引值; argsort()[::-1] 返回的是数组值从大到小的索引值
print('-------- Yiru recommend for you --------')
# center() 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串。默认填充字符为空格。
idx = 0
for i in sortedResult:
print(u'评分: %.2f, 电影名: %s' % (predicts[i, int(user_id)] - 2, movies_df.iloc[i]['title']))
# .iloc的用法:https://www.cnblogs.com/harvey888/p/6006200.html
idx += 1
if idx == 10:
break
3.2.5 原理补充
对于矩阵分解等需要用到机器学习、深度学习等模型的方法,参数的选择与确定是一个核心问题,不同的选择会使模型效果大相径庭。模型训练过程中重要的参数总结如表16,以矩阵分解中算法收敛效果与模型中的正则项系数λ![]() 和矩阵维度k为例,关系如图39(Netflix电影推荐系统)所示:
和矩阵维度k为例,关系如图39(Netflix电影推荐系统)所示:
表16 训练过程中的重要参数总结
| 1、损失函数: 损失可以衡量模型的预测值和真实值的不一致性,由一个非负实值函数损失函数定义 |
| 2、优化器: 为使损失最小,定义loss后可根据不同优化方式定义对应的优化器 |
| 3、epoch: 学习回合数,表示整个训练过程要遍历多少次训练集 |
| 4、学习率: 学习率描述了权重参数每次训练之后以多大的幅度(step)沿梯下降的方向移动 |
| 5、归一化: 在训练神经神经网络中通常需要对原始数据进行归一化,以提高网络的性能 |
| 6、Batchsize: 每次计算损失loss使用的训练数据数量 |
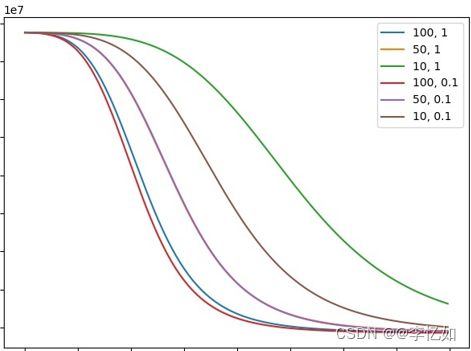
图39 参数对模型效果的影响样例
3.2.6 效果对比
对本测试实验的两种(是否使用tensorflow)设计与实现进行性能评估,首先在程序中引入time类,使用perf_counter方法记录实验耗时,在ml-latest-small将推荐进行20次,记录平均运行时间。数据汇总如表17:
表17 基于矩阵分解的协同过滤电影推荐系统不同实现的性能对比
| 实现 |
平均运行时间 |
| 无框架 |
10.71s |
| Tensorflow |
0.93s(有模型),69.88s(无模型) |
根据两种构建方式的设计与性能对比,Tensorflow在初次使用没有模型的时候效率较低(需要进行模型的训练与评估),但在后续的使用中性能很高(暂不谈推荐效果)。
而无框架矩阵分解则是每次对数据进行初始化、梯度下降等操作,性能稳定且优于本实验构建的无框架基于用户协同过滤推荐系统(25.414s)。